
Prediction Of Stock Current Value
1. 개요
- 모든 코드는 깃헙에 공개되어 있습니다.
https://github.com/nanoteyep/ToyProject/tree/main/ToyProject1
- 이번 프로젝트는 네이버 금융 페이지에서 기업 별 시세 정보를 가져와 이를 바탕으로 기업의 현재가를 예측하는 프로그램을 작성해 보도록 하겠습니다.
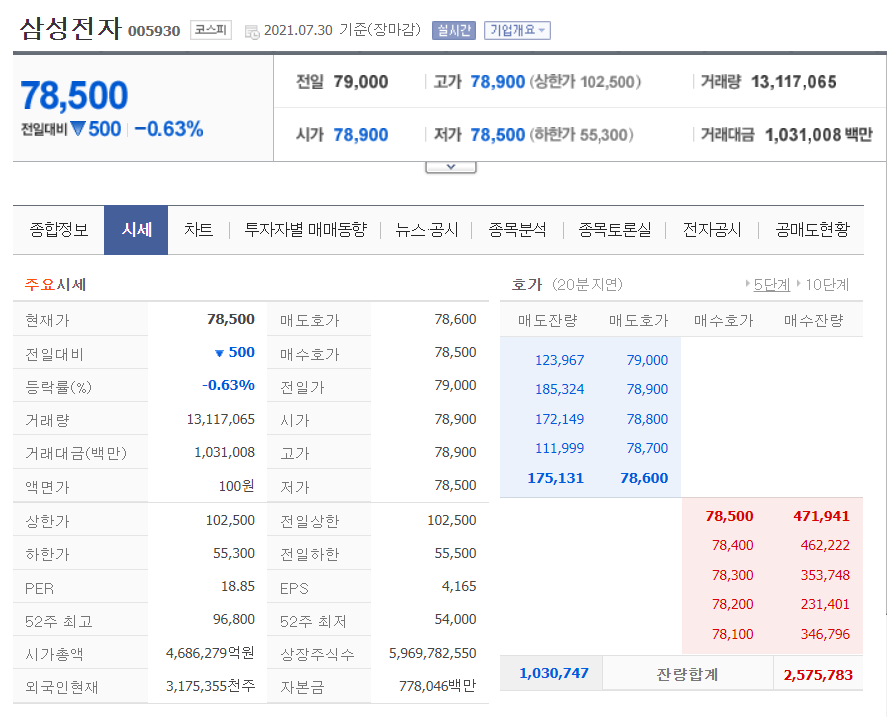
- 위 페이지는 이번 프로젝트의 표적 페이지 중
삼성전자의 페이지 입니다. -
위 페이지의
주요 시세테이블의 데이터를 파싱해 이를 바탕으로현재가를 예측하는 것이 이번 프로젝트의 목표입니다. - 기업의 현재가는 연속된(continuous)한 값이므로
분류가 아닌회귀알고리즘, 그 중선형회귀알고리즘을 사용할 예정입니다.
2. 라이브러리
# import library
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from urllib.request import urlopen
from bs4 import BeautifulSoup
from google.colab import files
import time
import asyncio
from sklearn.linear_model import LinearRegression
- 기본적으로 사용하는 라이브러리들입니다.
- 실질적으로 사용되는 라이브러리는
numpy,pandas,urlopen,BeautifulSoup,files,LinearRegression입니다. - 나머지는 대부분 디버깅을 위해 사용된 라이브러리이기에 위의 6가지 라이브러리만 불러들여와도 충분합니다.
numpy,pandas는 데이터 활용을 위해 사용된 라이브러리 입니다.urlopen과BeautifulSoup는 파싱을 위해 사용된 라이브러리이며files는 파싱된 데이터를 다운로드 하는데 필요한 라이브러리입니다.LinearRegression은 이번에 사용될선형회귀알고리즘을 위한 라이브러리 입니다.
3. 함수 선언
def get_company_code():
df = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download', header=0)[0]
company_code_df = df[['회사명','종목코드']]
return company_code_df
def make_soup(company_code):
# company_code = '005930' # test company code
company_code = str(company_code).zfill(6)
url = f'https://finance.naver.com/item/sise.nhn?code={company_code}'
source = urlopen(url)
soup = BeautifulSoup(source, 'lxml')
return soup
def call_element(class_name):
features = []
for element in class_name:
features.append(element.text.strip().replace(',',''))
return features
# collecting features has class name as p11
def make_features(soup):
p11 = soup.find_all(class_='p11')
features = call_element(p11)
features = features[:24]
features[4] = features[4][:-1]
features[10] = features[10][:-1]
features[20] = features[20][:-2]
features[22] = features[22][:-2]
features[23] = features[23][:-2]
return features
def make_stock_data(company_name, company_code, features):
stock_dict = {'기업명':[company_name],
'기업코드':[company_code],
'현재가':[features[0]],
'매도호가':[features[1]],
'전일대비':[features[2]],
'매수호가':[features[3]],
'등락률':[features[4]],
'전일가':[features[5]],
'거래량':[features[6]],
'시가':[features[7]],
'거래대금':[features[8]],
'고가':[features[9]],
'액면가':[features[10]],
'저가':[features[11]],
'상한가':[features[12]],
'전일상한':[features[13]],
'하한가':[features[14]],
'전일하한':[features[15]],
'PER':[features[16]],
'EPS':[features[17]],
'52주 최고':[features[18]],
'52주 최저':[features[19]],
'시가총액':[features[20]],
'상장주식수':[features[21]],
'외국인현재':[features[22]],
'자본금':[features[23]]}
stock_data = pd.DataFrame(stock_dict)
return stock_data
-
get_company_code()는 국내 상장주식들의회사명과종목코드를 불러오는 함수 입니다.df = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download', header=0)[0]는 대한민국 기업공시 채널에서 국내 상장 주식들의 정보를 불러오는 구문입니다. 해당 url에 접속하여 자동으로 데이터를 다운로드 받아df변수에 저장합니다.df변수는회사명과종목코드이외에도 여러가지 정보를 포함하고 있으나 이번 프로젝트에는 필요가 없기에 저장하지 않습니다.company_code_df에회사명과종목코드를 저장하고 반환합니다.
-
make_soup()함수는 네이버 금융에서 해당 기업의 페이지 정보를 가져오는 함수입니다.- 네이버 금융은
https://finance.naver.com/item/sise.nhn?code=+종목코드의 형식으로 되어있습니다. - 즉, 기업의 종목코드만 알 수 있다면 그 기업의 페이지 정보를 불러들일 수 있습니다.
- 그렇게 불러들인 정보를
lxml형태로 저장하고soup라는 변수에 저장한 후 반환합니다.
- 네이버 금융은
-
call_element()함수는class_name이라는 인자를 받아들인 후class에 인자가 포함된htmㅣ문을 저장하는 함수입니다.- 추후에 설명하지만 우리가 불러들여야 하는 테이블의 숫자들은 모두
class에p11이라는 이름을 가지고 있습니다. - 이 내용들을 features라는 리스트에 앞뒤 공백을 제거한 후, 숫자의 1000단위마다 표기한
,를 제거 한 후 저장합니다.
- 추후에 설명하지만 우리가 불러들여야 하는 테이블의 숫자들은 모두
-
make_features()함수는class에 수많은p11을 포함한html문중주요 시세의 숫자 부분만 저장하는 함수 입니다.- 네이버 금융 시세 페이지는 대부분의 수치를
tah p11 va01,tah p11,p11라는class이름을 지었으며주요 시세란의 모든 수치는 전부class이름에 `p11을 가지고 있습니다. - 하지만
주요 시세의 수치들은 1번부터 24번까지이며 나머지는 그 외의 부분 수치이기에 지금은 저장하지 않습니다. - 5, 11, 21, 23, 24번은 한글 수치이름을 포함하고 있기에 숫자만 저장하기 위해 뒷 부분을 잘라서 저장합니다.
- 이렇게 저장된 데이터를 features에 넣고 반환합니다.
- 네이버 금융 시세 페이지는 대부분의 수치를
-
make_stock_data()함수는 지금까지 모은 features데이터를 가공하기 편하게DataFrame형태로 바꾼 후 반환합니다.
4. main
# ATTENTION! THIS SHELL TAKES TOO LONG TIME!! IT TAKES ABOUT 1HOURS AND 17MINITUES
# load company code
company_code_df = get_company_code()
# initiallize
stock_data = pd.DataFrame()
for index, company in company_code_df.iterrows():
company_name = company['회사명']
company_code = company['종목코드']
soup = make_soup(company_code)
features = make_features(soup)
stock_data = pd.concat([stock_data, (make_stock_data(company_name, company_code, features))],ignore_index=True, axis=0)
# save data every 200 index
if index % 200 == 0:
stock_data.to_csv("stock_data.csv")
print(f"DataFrameSaved at {index}rows")
# finally save all data and download
stock_data.to_csv("stock_data.csv")
files.download("stock_data.csv")
주의!! 이 코드는 무척 오래걸립니다! 약 한시간 17분 걸렸습니다.
- 이제 대한민국 기업공시 채널에 기록된 모든 회사의 데이터를 파싱, 저장합니다.
- 오래 걸리기에 200번마다 데이터를 저장하고 알려주는 구문을 넣었으며 모든 데이터를 긁어왔다면
stock_data.csv라는 파일을 만들고 다운로드 받습니다. - github에 코드와 함께 데이터도 같이 저장해 놓았으니 직접 돌리지 마시고 데이터를 다운로드 받아 사용하는 것을 추천드립니다.
5. 데이터 가공
stock_data = pd.read_csv('stock_data.csv')
stock_data.head()
stock_data.info()
stock_data.isnull().sum()
- 데이터를 여러 방법으로 확인해 봅니다.
- 그 다음
null값을 확인해 줍니다.
stock_data.drop(stock_data[stock_data['자본금'] == 5].index, inplace=True)
for index,data in stock_data.iterrows():
try:
float(data['액면가'])
except ValueError:
stock_data.drop(index, inplace=True)
stock_data['액면가'].fillna(0, inplace=True)
stock_data.drop(stock_data[stock_data['EPS'].isnull()].index, inplace=True)
# stock_data.drop(stock_data[stock_data['EPS'] < 0].index, inplace=True)
# stock_data['PER'].fillna((stock_data['현재가']/stock_data['EPS']), inplace=True)
stock_data.drop(stock_data[stock_data['PER'].isnull()].index, inplace=True)
stock_data['전일하한'].fillna(stock_data['하한가'], inplace=True)
stock_data.isnull().sum()
stock_data.info()
-
결손값(null)을 처리하기 위한 코드입니다.- 분석결과
액면가란이 비어있는 데이터가 조금 있었습니다. 그런 코드들은 데이터가 한칸씩 순서대로 데이터를 저장한 저의 경우 원하는 대로 데이터가 원하는 column에 들어가지 않았습니다. 이러한 데이터는 공통적으로자본금column에5라는 수치가 들어있기에 전부 지워줍니다. - 또한
액면가의 단위가 원이 아닌US, JYP, CYN과 같은 경우 데이터가 밀리지는 않았으나 숫자로 변환할 수 없어 알고리즘에 적용할 수 없습니다. 몇 안되는 수치이니 이 또한 지워줍니다. - 왜 인지는 모르겠으나
액면가가NaN으로 채워진 row가 하나 있기에 0을 넣어 주었습니다. 액면가는 그삼성전자조차500이라는 작은 수치이기 때문입니다. PER과EPS는 기업의 당기 순이익에 기반하기에 이 수치가 공개되지 않은 기업들은결손값을 가지게 되었습니다.EPS는 존재하나PER이 존재하지 않는 기업또한 존재하였는데 이를 직접 계산하여 넣어주려니 수치가inf(무한대)가 되기에 그냥 전부 지워주었습니다.전일하한가가 없는 기업들은하한가를 그대로 넣어주었습니다.- 마지막으로
결손치(null)이 있는지 확인하니 없었으며 rows가 대략 150개 정도 줄어들었습니다. 전체 2450개중에 150개면 유의미한 수치는 아니라고 생각합니다.
- 분석결과
6. 머신러닝(ML)
X_train = stock_data.drop(["기업명", "기업코드", "현재가"], axis=1)
X_test = X_train.iloc[-100:]
X_train = X_train.iloc[:-100]
Y_train = stock_data["현재가"].iloc[:-100]
Y_answer = stock_data["현재가"].iloc[-100:]
- ML을 돌리기 전에 input할 데이터를 골라냅니다.
현재가는 표적 데이터니Y_train에 따로 잘라내며기업명과기업코드는 알고리즘 단계에서 필요 없으니 잘라내고X_train에 저장합니다.- 국내 모든 상장기업의 데이터를 가져왔기 때문에
TEST CASE를 준비 할 수 없었습니다. - 그렇기에
X_train의 마지막 100개 데이터를 잘라내어TEST CASE로 사용하려고 합니다. - 마찬가지로
Y_train의 마지막 100개 데이터는 학습된TEST CASE와 대조할 정답 데이터이기 때문에Y_anser에 저장합니다.
linear = LinearRegression()
linear.fit(X_train, Y_train)
Y_pred = linear.predict(X_test)
linear.score(X_train,Y_train)
LinearRegression선형회귀알고리즘을 이용하여 학습시킵니다.score()함수를 이용하여 모델과 인자의 상관관계를 학습한 결과 0.999972라는 무척 높은 수치가 계산되었습니다.- 이는
현재가가인자와 무척 밀접한 상관관계가 있음을 나타냅니다. - 사실 여기서 오류가 한가지 있는데 저희가
인자로 선택한 데이터 중에는현재가가 반영된 데이터가 있기 때문에 이처럼 높은 상관관계가 형성되었다고 생각합니다.
pd.DataFrame({"Y_answer" : Y_answer.values, "Y_pred" : Y_pred})
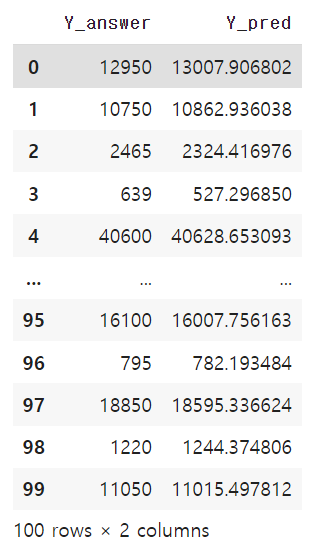
- 왼쪽이 실제 기업의
현재가이며 오른쪽이 저희가 모델을 통해 학습한예측 현재가입니다. - 상당히 비슷한 수치를 지닌 것을 보아 성공적으로 알고리즘이 적용된 것 같습니다!
마치며
이번 포스팅은 개인적으로 해보고 싶었던 주가예측 프로그램을 짜보았습니다. 첫 프로젝트 이기에 아쉬운 점이 많기도 하였으나 웹상에서 데이터를 불러들이고 이를 가공하여 활용한다는 관점에서는 제대로 지금까지 배운 내용을 복습 할 수 있었던 프로젝트라고 생각합니다.