
Image Classification_ResNET
시작하기에 앞서
- 이번 포스팅은
kaggle의 데이터 셋인Animals Detection Images Dataset를 이용한 Image Classification입니다.https://www.kaggle.com/antoreepjana/animals-detection-images-dataset
- 작업 환경은
Kaggle Notebook이며 코드는 아래 링크에 공유되어 있습니다.https://www.kaggle.com/tolight20/animal-classification/notebook
- 모델코드는 아래 링크를 참조하였습니다.
- 동물 이미지 분류를 하기 위해 Dataset을 찻던 도중 kaggle 내에 공유된 Dataset이 있었기에 사용하게 되었습니다.
1. 데이터 불러오기
data_dir = "../input/animals-detection-images-dataset"
train_dir = os.path.join(data_dir, "train")
test_dir = os.path.join(data_dir, "test")
all_train_subdir = glob.glob(train_dir + "/*")
all_test_subdir = glob.glob(test_dir + "/*")
train_classes=[os.path.basename(pp) for pp in all_train_subdir]
test_classes=[os.path.basename(pp) for pp in all_test_subdir]
-
kaggle내의 Dataset을 kaggle Notebook을 이용하여 편집하기 때문에 위와 같은 경로에 저장되어 있습니다. 각자의 데이터 저장장소에 맞는 경로를 입력하여 데이터를 불러옵니다.
-
Animals Detection Images Dataset은 test, train 두개의 폴더로 되어 있으며 각각의 폴더는 animal classes를 나타내는 80개의 폴더로 되어 있습니다. -
그렇기 때문에 subdir를 지정하여 test, train내의 폴더 명을 전부 불러 온 후 classes목록으로서 리스트에 저장 한 것 입니다.
img_path = []
label = []
test_path = []
test_label = []
label_dict = {label : index for index, label in enumerate(train_classes)}
for subdir in all_train_subdir:
image_files = glob.glob(os.path.join(subdir, "*.jpg"))
for image_file in image_files:
temp_img_path = image_file
temp_label = os.path.basename(os.path.dirname(image_file))
img_path.append(temp_img_path)
label.append(temp_label)
for subdir in all_test_subdir:
image_files = glob.glob(os.path.join(subdir, "*.jpg"))
for image_file in image_files:
temp_img_path = image_file
temp_label = os.path.basename(os.path.dirname(image_file))
test_path.append(temp_img_path)
test_label.append(temp_label)
-
모든 이미지를 불러들이면 메모리를 너무 많이 차지하기 때문에 이미지 경로를 저장한 후 필요할 때 마다 경로의 이미지를 불러오는 방식을 사용하였습니다.
-
그렇게 이미지의 경로 와 label을 순서대로 저장하였습니다. 때문에 같은 인덱스 값을 가진 img_path와 label은 서로 매치되는 방식입니다.
-
label_dict는 각 classes마다 번호를 매칭해주는 dict입니다. Spider는 0으로 지칭되는 방식입니다.
import torchvision.transforms.functional as TF
def resize_img(image, target_size = (256, 256)):
image_new = TF.resize(image, target_size)
return image_new
- 이 Dataset의 문제점으로 모든 이미지의 크기가 제각각 이라는 점 입니다. 그렇기 때문에 크기를 256X256으로 전환해주는 함수를 만들어 주었습니다.
transform = transforms.Compose(
[transforms.ToTensor(), # change to torch.tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # mean, distribution
batch_size = 64
class CustomDataset(data.Dataset):
def __init__(self, img_path, label):
super(CustomDataset, self).__init__()
self.img_path = img_path
self.label = label
def __getitem__(self, index):
self.image = np.array(cv2.flip(cv2.imread(self.img_path[index]),0))
self.image = transform(self.image)
self.image = resize_img(torch.flip(self.image, [0, 1]))
self.label_idx = torch.tensor(label_dict[self.label[index]])
return self.image, self.label_idx
def __len__(self):
return len(self.img_path)
train_dataset = CustomDataset(img_path, label)
test_dataset = CustomDataset(test_path, test_label)
-
위에서 image를 path로 저장하였기 때문에 image로 불러오고 label또한 같이 불러오는 코드입니다.
-
image는 불러오면서 Normalization을 해주었으며 사이즈 조정까지 된 상태로 나오게 됩니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, num_workers=os.cpu_count(), shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, num_workers=os.cpu_count())
- 이제 DataLoader를 이용해 필요한 batch사이즈 만큼 불러오며 학습을 진행하게 됩니다.
2. 모델 - ResNet
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expension = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels*BasicBlock.expension, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
self.relu = nn.ReLU()
if stride != 1 or in_channels != BasicBlock.expension * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels*BasicBlock.expension, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*BasicBlock.expension)
)
def forward(self, x):
x = self.residual_block(x) + self.shortcut(x)
x = self.relu(x)
return x
class BottleNeck(nn.Module):
expension = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_block(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels*BottleNeck.expension, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels*BottleNeck.expension)
)
self.shortcut = nn.Sequential()
self.relu = nn.ReLU()
if stride != 1 or in_channels != out_channels * BottleNeck.expension:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels*BottleNeck.expension, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*BottleNeck.expension)
)
def forward(self, x):
x = self.residual_block(x) + self.shortcut(x)
x = self.relu(x)
return x
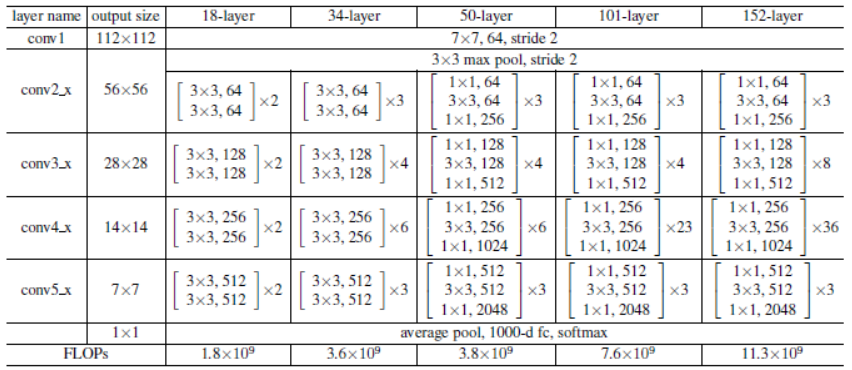
-
ResNet의 구조는 위 사진을 참고해주시길 바랍니다.
-
ResNet을 살펴보면 ResNet34까지와 이후의 ResNet의 블록구조가 조금씩 차이가 있습니다.
-
위 코드는 ResNet의 특징인 Residual block을 구현한 코드입니다.
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=80, init_weights=True):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2, padding=1)
)
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512*block.expension, num_classes)
# weights inittialization
if init_weights:
self._initialize_weights()
def _make_layer(self, block, out_channels, num_block, stride):
strides = [stride] + [1] * (num_block - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expension
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# define weight initialization function
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def resnet18():
return ResNet(BasicBlock, [2,2,2,2])
def resnet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50():
return ResNet(BottleNeck, [3,4,6,3])
def resnet101():
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
return ResNet(BottleNeck, [3, 8, 36, 3])
-
위 코드는 본격적으로 ResNet을 구현한 코드입니다.
-
_make_layer라는 함수를 사용하여Residual block을 이용한 구조를 일정 층 수 만큼 겹친 layer를 만들었습니다. -
_initialize_weights함수는 혹시 이전에 사용한 weight가 남아있을 경우 초기화 해주는 코드입니다.
3. 학습
import torch.optim as optim
model = resnet34()
learning_rate = 0.005
loss_fn = nn.CrossEntropyLoss() # multi-class classification용
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
- 이렇게 만든 모델 중
ResNet34를 사용하였으며 optimization function으로는Adam을 사용하였습니다.
epochs = 3
iterations = 100
for epoch in range(epochs):
train_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# gradient 초기화
optimizer.zero_grad()
# feed-forward
outputs = model(inputs) # forward 함수 call.
loss = loss_fn(outputs, labels) # cross-entropy loss 계산.
# backprop
loss.backward() # local gradient 계산 및 loss backprop
optimizer.step() # weight update
# 특정 iteration마다 loss값 출력
train_loss += loss.item() # loss summation
if i % iterations == iterations - 1:
print("[%d, %5d] loss: %.3f" % (epoch+1, i+1, train_loss/iterations))
train_loss = 0.0 # 특정 개수마다 loss를 출력해주기 때문에 초기화.
print("Finish Training")
-
이 전에 배운 CNN때 사용한 학습코드입니다.
-
epochs를 3으로 둔 이유는 kaggle이 running time을 9시간 까지만 제공하기 때문입니다!!!!!
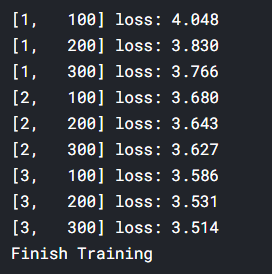
-
학습이 진행되면서 loss가 떨어지는 것을 확인 할 수 있습니다.
-
아마 epoch를 처음 생각했던대로 400까지 돌렸다면 충분히 신뢰가능한 모델이 생성되었을 것 입니다.
4. 결과
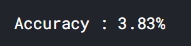
-
네, 완전히 박살난 모델입니다.
-
만약 충분한 epochs를 돌릴 수 있는 환경이었다면 괜찮은 결과를 볼 수 있을 것이라고 예측해봅니다.
마치며
정말 아쉽다고 생각하고 있습니다. 제가 주로 사용하는 kaggle과 colab모두 runtime에 제한을 두고 있어 이를 충분히 돌려볼 수가 없었습니다. 또한 gpu세팅을 했었지만 kaggle환경에서 제대로 작동하지 않아 cpu를 사용하여 연산한 것도 아쉬운 점 중 하나입니다. 다음 프로젝트에 있어서는 이를 어느정도 해결해 보고자 합니다.