
버거지수 계산
버거지수란?
밐폭도 @Godtsune_miku
“한 도시의 발전 수준은 (버거킹의 개수+맥도날드의 개수+KFC의 개수)/롯데리아의 개수를 계산하여 높게 나올수록 더 발전된 도시라고 할 수 있다”
라는 한 트위터 글에서 가져온 지수입니다. 지금부터 버거킹, 맥도날드, KFC, 롯데리아의 지역별 지점수를 가져와 이를 계산해 보려고 합니다.
모든 코드와 데이터는 깃헙에 공개되어 있습니다.
https://github.com/nanoteyep/ToyProject/blob/main/BergerKingdom/berger_kingdom.ipynb
시작하기 앞서
- 이 코드는 jupyter notebook 환경에서 작업하였습니다.
- 처음에는 구글 colab에서 작업하였으나 롯데리아 파싱을 진행하던중 TIMEOUT에러가 발생하여 jupyter notebook에서 작업하게 되었습니다.
1. 라이브러리
#import lib
from urllib.request import urlopen
import requests
import json
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import urllib.request
import selenium
from matplotlib import rcParams
from matplotlib import cm, colors, _cm
import matplotlib.pyplot as plt
import matplotlib as mpl
import scipy.stats
2. KFC
- 이 코드는 직접 실행하여도 문제 없으나 시간이 꽤 걸리므로 공개된 깃헙 주소에서 데이터를 다운로드 받는 것을 추천합니다.
#Reading kfc
url = 'https://www.kfckorea.com/kfc/interface/selectStoreList'
kfc_total = pd.DataFrame()
# make empty DataFrame
# 저도 모르겠는데 KFC가 코드를 이상하게 짜서 이 과정이 한번 필요합니다.
data = {
'device': 'WEB',
'sido_search': 'A0181',
'gugun_search': 'A018001',
'show_search': 'Y',
'initYn': 'N',
'rows': '20'
}
resp = requests.post(url, data=data)
kfc_df = pd.DataFrame(resp.json()['rows'])
kfc_df["store_old_address"]
kfc_loc = pd.DataFrame(kfc_df['store_old_address'].apply(lambda v: v.split()[:2]).tolist(),
columns=('d1', 'd2'))
kfc_total = pd.concat([kfc_total, kfc_loc])
# -----------------------------------------------------------
# 진짜 kfc위치를 저장하는 코드
for sido in range(1,18):
sido_code = 'A018' + str(sido)
for gugun in range(1,45):
gugun_code = sido_code + '00' + str(gugun)
data = {
'device': 'WEB',
'sido_search': sido_code,
'gugun_search': gugun_code,
'show_search': 'Y',
'initYn': 'N',
'rows': '20'
}
try:
resp = requests.post(url, data=data)
kfc_df = pd.DataFrame(resp.json()['rows'])
kfc_df["store_old_address"]
kfc_loc = pd.DataFrame(kfc_df['store_old_address'].apply(lambda v: v.split()[:2]).tolist(),
columns=('d1', 'd2'))
kfc_total = pd.concat([kfc_total, kfc_loc])
except KeyError:
continue
kfc_total.to_csv("kfc_total.csv")
# colab에서 작업하던 흔적입니다. files는 구글 coloab에서 사용하던 라이브러리로 jupyter notebook에서는 작동하지 않습니다.
files.download("kfc_total.csv")
- kfc의 경우
gugun_code가A108+sido_code+숫자의 형태로 되어 있는데 이상하게 가장 첫 코드만 형태가 조금 다르기에 가장 처음에 따로 저장해주었습니다. - 이후 총 17개의
sido_code를 탐색해 최대 44개의gugun_code를 탐색하며d1에는 광역시, 도 명을d2에는 예하 시, 구 명을 저장합니다.
나중에 안 사실이지만 data에 시도, 구군 코드를 작성하지 않고 보낸다면 모든 지역의 정보를 한번에 받아올 수 있다고 합니다. data의 rows를 500쯤으로 바꾸어 한번에 파싱한다면 여러개의 url을 탐색하지 않아도 되어 더욱 빠르게 마칠 수 있을것 입니다.
kfc_total = pd.read_csv("kfc_total.csv")
kfc_total.info()
- 데이터를 다운로드 받았다면 이 부분부터 시작하면 됩니다.
kfc_total['d1'].unique()
d1_aliases = """서울:서울특별시 충남:충청남도 강원:강원도 경기:경기도 충북:충청북도 경남:경상남도 경북:경상북도
전남:전라남도 전북:전라북도 제주도:제주특별자치도 제주:제주특별자치도 대전:대전광역시 대구:대구광역시 인천:인천광역시
광주:광주광역시 울산:울산광역시 부산:부산광역시"""
d1_aliases = dict(aliasset.split(':') for aliasset in d1_aliases.split())
kfc_total['d1'] = kfc_total['d1'].apply(lambda v: d1_aliases.get(v, v))
kfc_total['d1'].unique()
kfc_total의 광역시, 도 명은 약칭으로 되어 있는 부분이 많습니다. 이를 정식명칭으로 바꾸어 주는 코드 입니다.
kfc_total['d2'].unique()
d2명도 확인하여 잘못된 주소가 있는지 확인해 줍니다.
3. 버거킹
- 이 코드는 직접 실행하여도 문제 없으나 시간이 꽤 걸리므로 공개된 깃헙 주소에서 데이터를 다운로드 받는 것을 추천합니다.
# 버거킹!
url = 'https://www.burgerking.co.kr/BKR0001.json'
resp = requests.get(url)
json = resp.json()
bgk_tbl = pd.DataFrame(json['body']['storeList'])
bgk_tbl.to_csv("bgk_tbl.csv")
# 마찬가지로 colab에서 작업한 흔적입니다. jupyter notebook 환경이라면 지우면 됩니다.
files.download("bgk_tbl.csv")
bgk_tbl
- 버거킹의 경우 점포찾기에서 사용되는 api를 사용하였습니다.
- 주의 하셔야 할 점은 허가받은 api가 아니라는 점 입니다.
- 문제가 될 시 삭제하겠습니다.
bgk_tbl = pd.read_csv("bgk_tbl.csv")
bgk_tbl['ADDR_1'].tail()
- 데이터를 다운로드 받았다면 이 부분부터 진행하시면 됩니다.
bgk_total = pd.DataFrame()
for addr in bgk_tbl['ADDR_1'].values:
addr = addr.strip().split(' ')
d1, d2 = addr[0], addr[1]
bgk_df = pd.DataFrame({'d1':[addr[0]], 'd2':[addr[1]]})
bgk_total = pd.concat([bgk_total, bgk_df])
bgk_total.head()
- 이 과정은 api를 이용해 얻은 데이터를
d1과d2로 가공하는 과정입니다.
- 위 와 같은 형태로 데이터를 가공합니다.
bgk_total['d1'].unique()
d1_aliases = """서울:서울특별시 충남:충청남도 강원:강원도 경기:경기도 충북:충청북도 경남:경상남도 경북:경상북도
전남:전라남도 전북:전라북도 제주도:제주특별자치도 제주:제주특별자치도 대전:대전광역시 대구:대구광역시 인천:인천광역시
광주:광주광역시 울산:울산광역시 부산:부산광역시"""
d1_aliases = dict(aliasset.split(':') for aliasset in d1_aliases.split())
bgk_total['d1'] = bgk_total['d1'].apply(lambda v: d1_aliases.get(v, v))
bgk_total['d1'].unique()
- 마찬가지로 지역명에 차이가 있다면 수정해 줍니다.
bgk_total['d2'].unique()
d2도 확인해 줍니다.
4. 맥도날드
- 이 코드는 직접 실행하여도 문제 없으나 시간이 꽤 걸리므로 공개된 깃헙 주소에서 데이터를 다운로드 받는 것을 추천합니다.
# 맥도날드!!
MCDONALDS_URL = 'http://www.mcdonalds.co.kr/www/kor/findus/district.do?sSearch_yn=Y&skey=2&pageIndex={page}&skeyword={location}'
def search_mcdonalds_stores_one_page(location, page):
response = urllib.request.urlopen(
MCDONALDS_URL.format(location=urllib.parse.quote(location.encode('utf-8')), page=page))
mcd_data = response.read().decode('utf-8')
soup = bs4.BeautifulSoup(mcd_data)
ret = []
for storetag in soup.findAll('dl', attrs={'class': 'clearFix'}):
storeaddr = storetag.findAll('dd', attrs={'class': 'road'})[0].contents[0].split(']')[1]
storeaddr_district = storeaddr.split()[:2]
ret.append(storeaddr_district)
return pd.DataFrame(ret, columns=('d1', 'd2')) if ret else None
# 여러 페이지를 쭉 찾아서 안 나올 때 까지 합친다.
def search_mcdonalds_stores(location):
from itertools import count
found = []
for pg in count():
foundinpage = search_mcdonalds_stores_one_page(location, pg+1)
if foundinpage is None:
break
found.append(foundinpage)
return pd.concat(found)
mac_total = pd.DataFrame()
for page in range(1,82):
data = {'page': page}
resp = requests.post('https://www.mcdonalds.co.kr/kor/store/list.do', data = data)
soup = BeautifulSoup(resp.text, 'lxml')
for address in soup.find_all('dd', class_='road'):
mac_df_temp = pd.DataFrame({'d1' : [address.get_text().split(' ')[0]],
'd2' : [address.get_text().split(' ')[1]]})
mac_total = pd.concat([mac_df, mac_df_temp])
mac_total.to_csv("mac_total.csv")
# colab작업의 흔적입니다.
files.download("mac_total.csv")
- 맥도날드는 함수를 사용하여 작업하였습니다.
mac_total = pd.read_csv("mac_total.csv")
mac_total.drop(['Unnamed: 0'], axis=1, inplace=True)
mac_total.head()
- 데이터를 다운로드 받았다면 여기서 부터 진행하면 됩니다.

d1_aliases = """서울:서울특별시 충남:충청남도 강원:강원도 경기:경기도 충북:충청북도 경남:경상남도 경북:경상북도
전남:전라남도 전북:전라북도 제주도:제주특별자치도 제주:제주특별자치도 대전:대전광역시 대구:대구광역시 인천:인천광역시
광주:광주광역시 울산:울산광역시 부산:부산광역시 서울시:서울특별시"""
d1_aliases = dict(aliasset.split(':') for aliasset in d1_aliases.split())
mac_total['d1'] = mac_total['d1'].apply(lambda v: d1_aliases.get(v, v))
mac_total['d1'].unique()
- 마찬가지로
d1에서의 명칭이 차이가 있다면 수정해 줍니다.
mac_total['d2'].unique()
d2또한 확인해 줍니다.
5. BMK!
# BMK!!
B = bgk_total.apply(lambda r: r['d1'] + ' ' + r['d2'], axis=1).value_counts()
M = mac_total.apply(lambda r: r['d1'] + ' ' + r['d2'], axis=1).value_counts()
K = kfc_total.apply(lambda r: r['d1'] + ' ' + r['d2'], axis=1).value_counts()
BMK = pd.DataFrame({'B': B, 'M': M, 'K': K}).fillna(0)
BMK['total'] = BMK.sum(axis=1)
BMK = BMK.sort_values('total', ascending=False)
BMK.head(10)
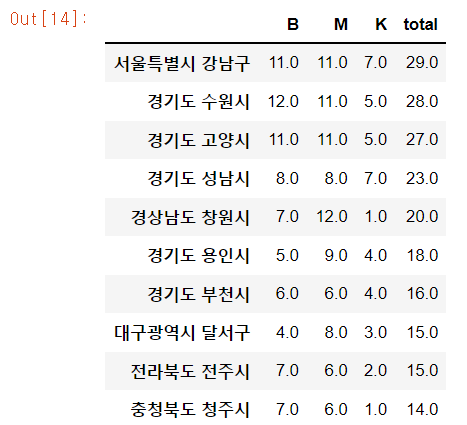
- 롯데리아 파싱을 진행하기 전 지금까지 모아온 데이터를 한번 정리해 줍니다.
6. 롯데리아
- 이 코드는 직접 실행하여도 문제 없으나 시간이 꽤 걸리므로 공개된 깃헙 주소에서 데이터를 다운로드 받는 것을 추천합니다.
LOTTERIA_URL = 'http://www.lotteria.com/Shop/Shop_Ajax.asp'
LOTTERIA_VALUES = {
'Page': 1, 'PageSize': 2000, 'BlockSize': 2000,
'SearchArea1': '', 'SearchArea2': '', 'SearchType': "TEXT",
'SearchText': '', 'SearchIs24H': '', 'SearchIsWifi': '',
'SearchIsDT': '', 'SearchIsHomeService': '', 'SearchIsGroupOrder': '',
'SearchIsEvent': ''}
LOTTERIA_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:12.0) Gecko/20100101',
'Host': 'www.lotteria.com',
'Accept': 'text/html, */*; q=0.01',
'Accept-Language': 'en-us,en;q=0.5',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://www.lotteria.com/Shop/Shop_List.asp?Page=1&PageSize=2000&BlockSize=2000&Se'
'archArea1=&SearchArea2=&SearchType=TEXT&SearchText=&SearchIs24H=&SearchIsWifi=&Se'
'archIsDT=&SearchIsHomeService=&SearchIsGroupOrder=&SearchIsEvent=',
}
postdata = urllib.parse.urlencode(LOTTERIA_VALUES).encode('utf-8')
req = urllib.request.Request(LOTTERIA_URL, postdata, LOTTERIA_HEADERS)
response = urllib.request.urlopen(req)
ltr_data = response.read().decode('utf-8')
soup = BeautifulSoup(ltr_data, 'lxml')
# ------------------------------------------------------------------------------------------------------
# 예전에는 위 url에서 주소도 같이 공개 했기 때문에 위의 코드로도 충분하였습니다.
# 하지만 현재 더이상 위의 url에서 주소를 공개하지 않기 때문에 저는 id를 추출하여 다시한번 다른 url에서 파싱을 진행하도록 하겠습니다.
# id를 추출하여 list로 저장합니다.
id_list = []
for id in range(0,2615,2):
id_list.append(str(soup.find_all('a')[id])[28:32])
# 추출된 id를 이용하여 새로운 페이지에 접속하여 주소를 파싱합니다.
lotte_total = pd.DataFrame()
i = 0
for id in id_list:
try:
url = f'https://www.lotteria.com/Shop/Shop_View.asp?Idx={id}'
resp = urlopen(url)
soup = BeautifulSoup(resp, 'lxml')
shop_name = soup.find('h3').get_text()
d1 = soup.find('td', class_='rt').get_text().split()[0]
d2 = soup.find('td', class_='rt').get_text().split()[1]
lotte_dict = pd.DataFrame({'shop_name':[shop_name],'d1':[d1], 'd2':[d2]})
lotte_total = pd.concat([lotte_total, lotte_dict])
i += 1
if i % 100 == 0:
print(f"Saving..{i}")
lotte_total.to_csv('lotte_total.csv')
except IndexError:
continue
lotte_total.to_csv('lotte_total.csv')
lotte_total.head()
- 롯데리아만 점포 명을 같이 저장한 이유는 밑에서 주소를 수정하기 쉽게 하기 위해서 입니다.
lotte_total = pd.read_csv("lotte_total.csv")
lotte_total.drop(['Unnamed: 0'], axis=1, inplace=True)
lotte_total.tail()
- 데이터를 다운로드 받았다면 여기서부터 진행하시면 됩니다.
d1_aliases = """서울:서울특별시 충남:충청남도 강원:강원도 경기:경기도 충북:충청북도 경남:경상남도 경북:경상북도
전남:전라남도 전북:전라북도 제주도:제주특별자치도 제주:제주특별자치도 대전:대전광역시 대전시:대전광역시 대구:대구광역시 인천:인천광역시
광주:광주광역시 울산:울산광역시 부산:부산광역시 부산시:부산광역시 서울시:서울특별시 세종:세종특별자치시 경남남도:경상남도"""
d1_aliases = dict(aliasset.split(':') for aliasset in d1_aliases.split())
lotte_total['d1'] = lotte_total['d1'].apply(lambda v: d1_aliases.get(v, v))
lotte_total['d1'].unique()
- 롯데리아의 경우 위의 지역 셋과 확연하게 떨어진 값들이 많이 발견됩니다.
d1의 이름만으로는 도저히 지역을 확인 할 수 없는 경우 아래의 코드로 지점명을 확인하며 카카오맵에 검색하여 주소를 알아내었습니다.
lotte_total[lotte_total['d1'] == '대우자동차']
- 주소를 알아 내었다면 수동으로, 직접, 손으로! 주소를 수정해 줍니다.
lotte_total.iloc[lotte_total[lotte_total['d1'] == '굽은다리역'].index] = ['', '서울특별시', '강동구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '감일백제로'].index] = ['', '경기도', '하남시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '진안군'].index] = ['', '전라북도', '진안군']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '인천공항'].index] = ['', '인천광역시', '중구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '동대문구'].index] = ['', '서울특별시', '동대문구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '문경새재도립공원'].index] = ['', '경상북도', '문경시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '번동사거리'].index] = ['', '서울특별시', '강북구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '롯데마트'].index] = ['', '경기도', '수원시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '동해시'].index] = ['', '강원도', '동해시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '중곡동'].index] = ['', '서울특별시', '광진구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '지하철'].index] = ['', '부산광역시', '동래구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '강남역'].index] = ['', '서울특별시', '강남구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '방학'].index] = ['', '서울특별시', '도봉구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '광혜원시외버스정류장'].index] = ['', '충청북도', '진천군']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '성수역1번출구'].index] = ['', '서울특별시', '성동구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '용인시'].index] = ['', '경기도', '용인시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '홈배달'].index] = ['', '경기도', '수원시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '수완지구'].index] = ['', '광주광역시', '광산구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '별곡리'].index] = ['', '충청북도', '단양군']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '2호선'].index] = ['', '서울특별시', '관악구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '청량리역3번출구'].index] = ['', '서울특별시', '동대문구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '회룡역'].index] = ['', '경기도', '의정부시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '진건초등학교'].index] = ['', '경기도', '남양주시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '두정역에서'].index] = ['', '충청남도', '천안시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '죽곡'].index] = ['', '전라남도', '곡성군']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '주례역'].index] = ['', '부산광역시', '사상구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '야탑역4번출구'].index] = ['', '경기도', '성남시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '창원시'].index] = ['', '경상남도', '창원시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '대우자동차'].index] = ['', '인천광역시', '부평구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '동암남로'].index] = ['', '인천광역시', '부평구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '화성시'].index] = ['', '경기도', '화성시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '단계동'].index] = ['', '강원도', '원주시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '까치산역3번출구에서'].index] = ['', '서울특별시', '강서구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '잠실'].index] = ['', '서울특별시', '송파구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '천안시'].index] = ['', '충청남도', '천안시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '모래내시장'].index] = ['', '인천광역시', '남동구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '남항동'].index] = ['', '부산광역시', '영도구']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '순천연향동'].index] = ['', '전라남도', '순천시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '논산'].index] = ['', '충청남도', '논산시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '부천시'].index] = ['', '경기도', '부천시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '금촌역'].index] = ['', '경기도', '파주시']
lotte_total.iloc[lotte_total[lotte_total['d1'] == '제천시'].index] = ['', '충청북도', '제천시']
-
지점명이 들어갈 자리에
''공백 처리를 해 준 것은 더이상 지점명 column을 사용하지 않기 때문입니다. -
d2또한 확인해 줍니다.
lotte_total['d2'].unique()
- 확인 결과 몇몇 결과가 조금 이상한 것을 확인하였습니다.
d2_aliases = """고흥군고흥읍:고흥군 나주시금천면:나주시 장성군장성읍:장성군 논산시연무읍:논산시
임실군임실읍:임실군 창녕군남지읍:창녕군 남양주시화도읍:남양주시 아산신:아산시"""
d2_aliases = dict(aliasset.split(':') for aliasset in d2_aliases.split())
lotte_total['d2'] = lotte_total['d2'].apply(lambda v: d2_aliases.get(v, v))
lotte_total['d2'].unique()
- 이것 또한 지역 셋을 새로 만들어 수정해줍니다.
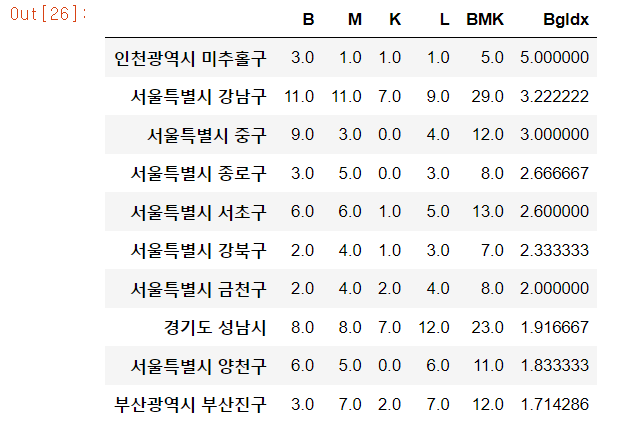
7. 버거지수
L = lotte_total.apply(lambda r: r['d1'] + ' ' + r['d2'], axis=1).value_counts()
bgt = pd.DataFrame({'B': B, 'M': M, 'K': K, 'L': L}).fillna(0)
# 롯데리아 점포수로 나누었을때 무한대가 됨을 방지하기 위해 1을 집어 넣습니다.
bgt.loc[bgt['L'] == 0, 'L'] = 1
- 롯데리아 또한
BMK와 마찬가지로L로 정리해 둡니다. - 정리된 데이터를
BMKL순으로bgt에 정리하였습니다. - 또한 버거지수는 지수 특성상 롯데리아 점포수로 나누어 주기 때문에 지수가 무한대가 됨을 방지하기 위해 0인 지점에는 1을 채워두었습니다.
bgt['BMK'] = bgt['B'] + bgt['M'] + bgt['K']
bgt['BgIdx'] = bgt['BMK'] / bgt['L']
bgt = bgt.sort_values('BgIdx', ascending=False)
bgt.head(10)
8. 시각화
rcParams['font.family'] = 'NanumGothic'
# matplotlib에서 한글폰트가 깨지는 현상이 있어 고생한 흔적입니다.
# plt.rcParams["font.family"] = 'NanumBrush'
# plt.rcParams["font.size"] = 20
# plt.rcParams["figure.figsize"] = (14,4)
plt.figure(figsize=(5, 5))
r = lambda: np.random.random(len(bgt))
plt.scatter(bgt['L'] + r(), bgt['BMK'] + r(), s=6, c='black', edgecolor='none', alpha=0.6)
plt.xlabel('LotteRIA')
plt.ylabel('BGK+MAC+KFC')
plt.xlim(0, 45)
plt.ylim(0, 45)
plt.gca().set_aspect(1)
# 추세선
trendfun = np.poly1d(np.polyfit(bgt['L'], bgt['BMK'], 1))
trendx = np.linspace(0, 45, 2)
plt.plot(trendx, trendfun(trendx))
# 튀는 점 몇 개는 이름도 표시합니다
tolabel = bgt[(bgt['L'] > 17) | (bgt['BMK'] >= 14)]
for idx, row in tolabel.iterrows():
label_name = idx.split()[1][:-1]
plt.annotate(label_name, (row['L'], row['BMK']))

- 기울기가 나타내는 값이 버거지수 입니다.
plt.figure(figsize=(4, 3))
subcnt = bgt[['B', 'K', 'L', 'M']]
subcnt.columns = ['버거킹', 'KFC', '롯데리아', '맥도날드']
p = subcnt.sum(axis=0).plot(kind='bar')
plt.setp(p.get_xticklabels(), rotation=0)
plt.ylabel('매장 수')
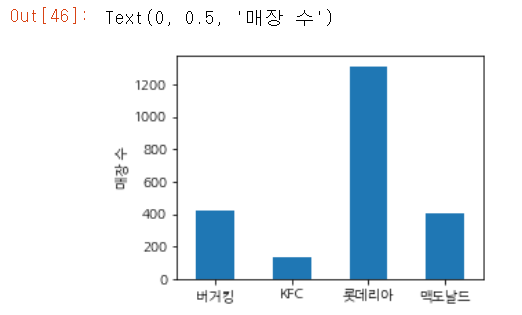
fig = plt.figure(figsize=(9, 9))
def plot_nstores(b1, b2, label1, label2):
plt.scatter(bgt[b1] + np.random.random(len(bgt)),
bgt[b2] + np.random.random(len(bgt)),
edgecolor='none', alpha=0.75, s=6, c='black')
plt.xlim(-1, 15 if b1 != 'L' else 35)
plt.ylim(-1, 15 if b2 != 'L' else 35)
plt.xlabel(label1)
plt.ylabel(label2)
r = scipy.stats.pearsonr(bgt[b1], bgt[b2])
plt.annotate('r={:.3f}'.format(r[0]), (9, 12.5), fontsize=14)
bgbrands = [
('B', '버거킹'), ('K', 'KFC'),
('L', '롯데리아'), ('M', '맥드날드'),
]
for a in range(len(bgbrands) - 1):
for b in range(1, len(bgbrands)):
if a >= b:
continue
ax = fig.add_subplot(len(bgbrands)-1, len(bgbrands)-1, a * 3 + b)
acol, alabel = bgbrands[a]
bcol, blabel = bgbrands[b]
plot_nstores(bcol, acol, blabel, alabel)
plt.tight_layout()
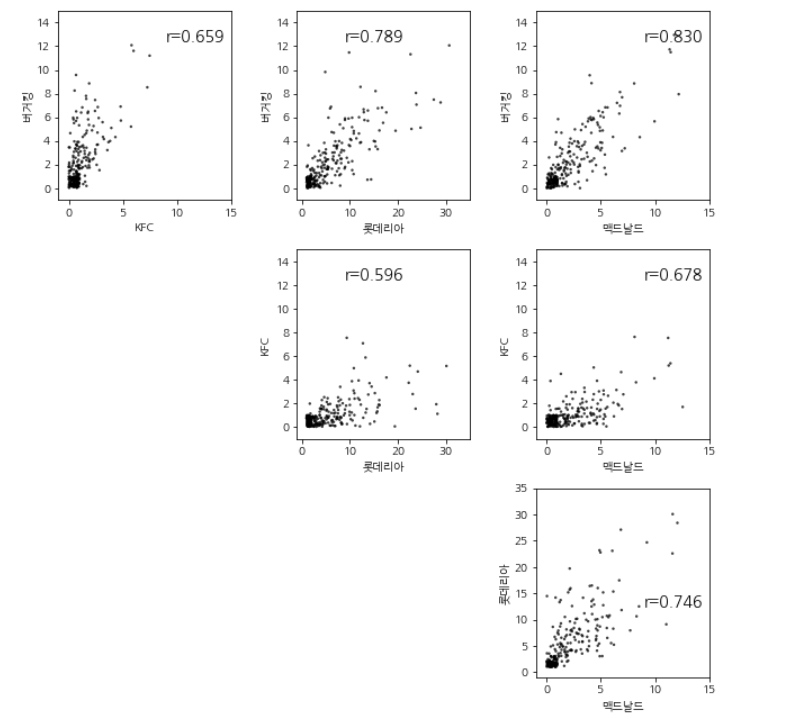
- r 은 x축과 y축 간의 상관관계를 나타내는 지표입니다.
- 보통 0.7 이상이라면 높은 상관관계를 나타낸다고 합니다.
마치며
사실 이 버거지수 프로젝트를 진행하며 마지막에 대한민국 지도상에 지수를 색으로 표시하고 싶었으나 대한민국의 블록맵을 찾지 못하였습니다. 추후에 기회가 생긴다면 버거지수를 좀 더 한눈에 알 수 있게 시각화를 마무리 지어보려고 생각하고자 합니다.