
kaggle competition - Titanic
시작하기에 앞서
이번 포스팅은 각종 데이터 분석 대회를 주최하는 kaggle의 듀토리얼격인 titanic에 직접 참가해 보며 알아보겠습니다.
저도 kaggle은 처음 이라 Subin An님의 code를 사용하였습니다. 감사합니다.
https://www.kaggle.com/subinium/subinium-tutorial-titanic-beginner
1. kaggle알아보기
- kaggle competition에 참가하기 위해선 회원가입이 필요합니다.
- 가입을 완료했다면
competition란에서titanic을 찾아갑니다.
- 전 이미
competition에 참가중이기 때문에Submit Predictions으로 활성화 되있습니다만 처음이시라면Join Competition이 활성화 되어 있을 겁니다. -
Join Competition을 클릭하여titanic에 참가합니다.
code란에 가시면 사진과 같이New Notebook란이 활성화 됩니다.Notebook은kaggle에서 제공하는 데이터 분석용 프로그래밍 환경입니다.- 기본적으로 여러가지 라이브러리가 설치되어 있으며 데이터 분석에 필요한 리소스또한 제공합니다.
- 또한
Competition에 참가중이라면 다음과 같이 자동으로data를 추가해 줍니다.
- 클릭하면 경로를 복사할 수 있으며 이 방법 이외에도
data란에서 직접 데이터를 다운로드 받을 수도 있습니다.
2. 라이브러리 불러오기
# 필요한 라이브러리를 우선 불러옵니다.
## 데이터 분석 관련
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
## 데이터 시각화 관련
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid') # matplotlib의 스타일에 관련한 함
## 그래프 출력에 필요한 IPython 명령어
%matplotlib inline
## Scikit-Learn의 다양한 머신러닝 모듈을 불러옵니다.
## 분류 알고리즘 중에서 선형회귀, 서포트벡터머신, 랜덤포레스트, K-최근접이웃 알고리즘을 사용해보려고 합니다.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
- 라이브러리는 크게 3가지 분류로 나눌 수 있습니다.
데이터 분석,시각화,머신러닝- 머신러닝에 처음보는 라이브러리가 다수 있지만 머신러닝에 관련된 포스팅은 추후에 따로 포스팅 하겠습니다.
3. 데이터 읽어들이고 살펴보기
- 코드를 살펴보기 앞서
titanic의 데이터를 먼저 살펴보도록 하겠습니다. titanic은gender_submission.csv,train.csv,test.csv세가지 데이터 파일이 존재합니다.gender_submission.csv는 우리가competition에 제출해야하는 형식의 예시파일 입니다.titanic에서gender_submission.csv는PassengerId와Survived를 표시해서 제출해야 함을 알려주고 있습니다.train.csv는tatinic이라는 실질적인 데이터입니다.- 승객의 정보, 이 승객이 살아남았는지를 기록한 실제 데이터입니다.
test.csv는 우리가train.csv를 통해 학습한 모델을 적용시켜야 하는 문제 파일입니다.- 학습된 모델로
test.csv의 정보로 기록된 승객이 살아 남을 것인가 예측 하는 것이titanic의 최종목표입니다.
# 데이터를 우선 가져와야합니다.
train_df = pd.read_csv("../input/titanic/train.csv")
test_df = pd.read_csv("../input/titanic/test.csv")
# 데이터 미리보기
train_df.tail()
- 데이터를 불러들이고 제대로 불러 들어왔는지 확인하는 작업입니다.
- 데이터의 경로는 오른쪽 상단에서 경로를 복사하고 확인 할 수 있습니다.
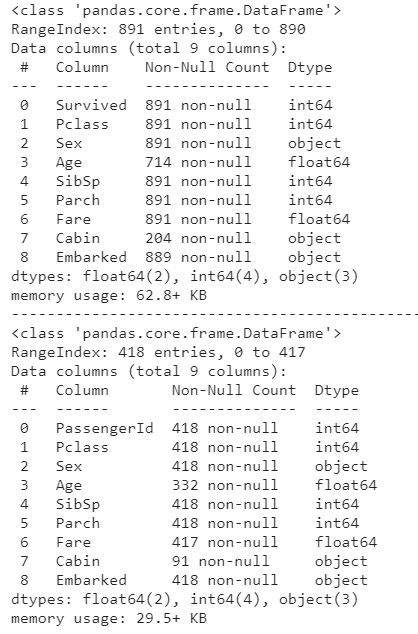
train_df.info()
print('-'*60)
test_df.info()
- info메소드를 이용하여 데이터의 정보를 확인합니다.

- 각각 구성된
columns값,몇 개의 데이터,데이터 타입을 확인 할 수 있습니다. train_df부터 살펴보겠습니다.- 총 891개의 승객 데이터가 있으며
Age,Cabin,Embarked에는null값이 채워져 있는 칸이 있다는 것을 알 수 있습니다. test_df또한 살펴 보겠습니다.Survivedcolumn이 없으며 418개의 데이터가 있습니다.- 또한
Age,Fare,Cabin의 몇몇 값에는null값이 채워져 있는 것을 알 수 있습니다.
4. 데이터 가공하기
- 가장 먼저 생존률과 관계 없어보이는, 이번 모델에서 사용하지 않을 column을 선별해 지워줍니다.
승객ID와이름그리고티켓값은 생존률과 아무 상관이 없다고 생각하여 과감하게 지워주었습니다.test.df에서PassengerId를 지우지 않은 이유는 저희가 제출해야하는 데이터에 포함되어 있기 때문입니다.
train_df = train_df.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
test_df = test_df.drop(['Name','Ticket'], axis=1)
- 이제 이러한 데이터를 가지고 하나씩 가공해 보도록 하겠습니다.
4.1 Pclass
train_df의Survived를 제외한 첫번째column인Pclass를 가공해 보도록 하겠습니다.
train_df["Pclass"].value_counts()
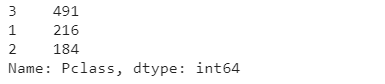
Pclass는 1, 2, 3이라는 세가지 값을 가지고 있습니다.- 1등급, 2등급, 3등급이라는 의미의
Pclass는 수치적 의미보단 범주형(카테고리형) 데이터 이므로one-hot encoding을 사용하겠습니다. one-hot encoding은pd.get_dummies()라는 메소드를 이용하려고 합니다.pd.get_dummies()메소드는 범주형 데이터를 0과 1로 구성된DataFrame을 생성해 주는 메소드 이기 때문에 자주 쓰이는one-hot encoding방법 입니다.
# get_dummies메소드를 이용하여 "Pclass" column만 one-hot encoding합니다.
Pclass_train_dummies = pd.get_dummies(train_df["Pclass"])
Pclass_test_dummies = pd.get_dummies(test_df["Pclass"])
# one-hot encoding된 column의 이름을 지정해줍니다. 혹시 one-hot encoding이 잘 이해가 안된다면 직접 Pclass_train_dummies를 출력하여 확인해 봅시다.
Pclass_train_dummies.columns = ['1st', '2nd', '3rd']
Pclass_test_dummies.columns = ['1st', '2nd', '3rd']
# 기존의 train_df 데이터 프레임에서 Pclass부분을 지워줍니다.
train_df.drop(["Pclass"], axis=1, inplace=True)
test_df.drop(["Pclass"], axis=1, inplace=True)
# 또한 기존의 데이터 프레임에서 one-hot encoding된 데이터 프레임을 이어붙여줍니다. 지금부터는 Pclass대신 '1st', '2nd', '3rd'로 구성된 columns가 Pclass의 역할을 할 것입니다.
train_df = train_df.join(Pclass_train_dummies)
test_df = test_df.join(Pclass_test_dummies)
4.2 Sex
Sexcolumn 또한 수치적 의미가 아닌 범주형 데이터이므로one-hot encoding을 해줍니다.Pclass와 마찬가지로pd.get_dummies()메소드를 사용하겠습니다.
sex_train_dummies = pd.get_dummies(train_df["Sex"])
sex_test_dummies = pd.get_dummies(test_df["Sex"])
sex_train_dummies.columns = ["femail", "mail"]
sex_test_dummies.columns = ["femail", "mail"]
train_df.drop(["Sex"], axis=1, inplace=True)
test_df.drop(["Sex"], axis=1, inplace=True)
train_df = train_df.join(sex_train_dummies)
test_df = test_df.join(sex_test_dummies)
4.3 Age
Agecolumn은train_df와test_df양 데이터 프레임에 결손값이 존재하는 column입니다.- 이러한 결손값을 채워주기 위해선 다음과 같은 네가지 방법이 존재합니다.
- 랜덤
- 평균값
- 중간값
- 버리기
- 여기선 우선 평균값으로 채우겠습니다. 데이터의 통일성을 위해 train_df의 평균값을 계산하여 test_df에도 적용하겠습니다.
# fillna는 결손값을 찾아 채우는 함수 입니다.
train_df["Age"].fillna(train_df["Age"].mean() , inplace=True)
test_df["Age"].fillna(train_df["Age"].mean() , inplace=True)
4.4 SibSp & Parch
- 사실 잘 이해는 안되는 데이터 입니다. 하지만 이미
one-hot encoding이 되어있으니 넘어가도록 하겠습니다.
4.5 Fare
Fare는test_df에 단 한가지 결손값이 존재합니다.- 데이터 누락이라고 보기보단 무단탑승이라고 생각하고 0으로 처리하겠습니다.
test_df["Fare"].fillna(0, inplace=True)
4.6 Cabin
- 이 데이터를 활용하기에는 너무 어렵습니다. 과감하게 버리도록 하겠습니다.
train_df = train_df.drop(['Cabin'], axis=1)
test_df = test_df.drop(['Cabin'], axis=1)
4.7 Embarked
Embarked는 탑승항구를 의미합니다.Embarked또한 결측치가 존재하는 column입니다.- 데이터를 먼저 살펴보자면
train_df['Embarked'].value_counts()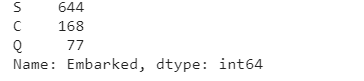
test_df['Embarked'].value_counts()
- S가 가장 많은 부분을 차지하고 있는 것을 알 수 있습니다.
- 그러므로 결측치에는 S를 채워주도록 하겠습니다.
train_df["Embarked"].fillna('S', inplace=True)
test_df["Embarked"].fillna('S', inplace=True)
- 이후 범주형 데이터 이므로
one-hot encoding을 해주겠습니다.
embarked_train_dummies = pd.get_dummies(train_df['Embarked'])
embarked_test_dummies = pd.get_dummies(test_df['Embarked'])
embarked_train_dummies.columns = ['S', 'C', 'Q']
embarked_test_dummies.columns = ['S', 'C', 'Q']
train_df.drop(['Embarked'], axis=1, inplace=True)
test_df.drop(['Embarked'], axis=1, inplace=True)
train_df = train_df.join(embarked_train_dummies)
test_df = test_df.join(embarked_test_dummies)
4.8 머신러닝을 위한 데이터 나누기
- 머신러닝에 관한 부분은 추후에 포스팅 하겠으나 우선 간단하게 알아보도록 하겠습니다.
- scikit-Learn에 의한 머신러닝은 간략하게 인자 와 출력값을 요구합니다.
- 2차원 데이터라고 가정하였을때 X(인자)에 따른 Y(출력값)을 입력받고 인자에 따른 출력값의 패턴을 각각의 모델로 학습하여 X_test(테스트인자)에서 Y(출력값)을 도출해 내는 것 입니다.
# train_df에서 Survived를 제외한 모든 columns를 인자로 넣을 예정입니다.
# 이러한 인자들의 차이에 의해 도출되는 Y(결과값)은 Survived가 될 예정입니다.
X_train = train_df.drop("Survived",axis=1)
Y_train = train_df["Survived"]
# 정답 데이터 프레임을 위해 남겨두었던 PassengerId를 잠시 지우고 복사하여 새로운 데이터 프레임을 만듭니다.
X_test = test_df.drop("PassengerId",axis=1).copy()
5. 머신러닝 알고리즘 적용하기
- 순서대로 로지스틱 회귀, SVC, 랜덤 포레스트, k-최근접 이웃 알고리즘을 적용해 보겠습니다.
# Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
# 도출된 모델에 X_test를 인자로 넣어 Y_pred를 도출해 냅니다.
Y_pred = logreg.predict(X_test)
# scikit-Learn은 score함수를 통해 얼마나 모델과 인자관의 상관관계가 밀접한지 나타 낼 수 있습니다.
logreg.score(X_train, Y_train)
# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
svc.score(X_train, Y_train)
# Random Forests
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
knn.score(X_train, Y_train)
- 전부 실행해 본다면
Random Forests가 가장 높은 점수를 보여주고 있습니다. - 그렇기에
Random Forests알고리즘을 이용하여 도출된 결과를 제출하도록 하겠습니다.
6. 제출하기
# Random Forests
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
# gender_submission에서 본 형식 그대로 submission DataFrame을 생성합니다.
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
# titanic.csv파일에 submission DataFrame을 저장합니다.
submission.to_csv('titanic.csv', index=False)
- 이제 오른쪽 상단 데이터란을 보시면
titanic.csv파일에output란에 생성 된 것을 확인 할 수 있습니다. - 이 생성된 파일을 다운로드 받고
competition란으로 돌아가Submit Prediction에 제출하면 됩니다.
7. 점수

- 축하합니다!
titanic competition을 완료하였습니다. - 저는 위 코드로 49465등을 달성하였습니다.
마치며
이번 포스팅에서는 kaggle의 titanic competition을 해보았습니다. 우선 competition에서 commit을 해보자는 것에 의의를 두고 다른사람의 코드를 빌려 분석하였습니다. kaggle에는 titanic이외에도 몇가지 듀토리얼 격의 competition을 준비해 놓았습니다.
이제 이러한 competition을 도전해 보아도 되며 titanic의 점수를 높이기 위해 노력해 보아도 괜찮습니다.