
kaggle competition - Tabular Playground Series
시작하기에 앞서
이번 포스팅은 각종 데이터 분석 대회를 주최하는 kaggle의 Active Competition TPS에 직접 참가한 내용입니다.
처음으로 kaggle active competition에 참가함에 있어 seol tommy, MoCuishleD님과 함께 총 3명으로 참가하였습니다.
https://www.kaggle.com/c/tabular-playground-series-sep-2021/overview/prizes
팀 이름은 GMO입니다.
사용된 notebook은 모두 Public으로 공개되어 있습니다.
https://www.kaggle.com/seoltommy/gmo-submission
https://www.kaggle.com/mocuishled/gmo-eda
https://www.kaggle.com/tolight20/tps-gmo-tolight20
1. TPS 알아보기
TPS는 Insurance Policy, 보험 정책에 따른 Claim을 할 지, 하지 않을 지 결정하는 binary classification 문제 입니다.
1.1 Submission
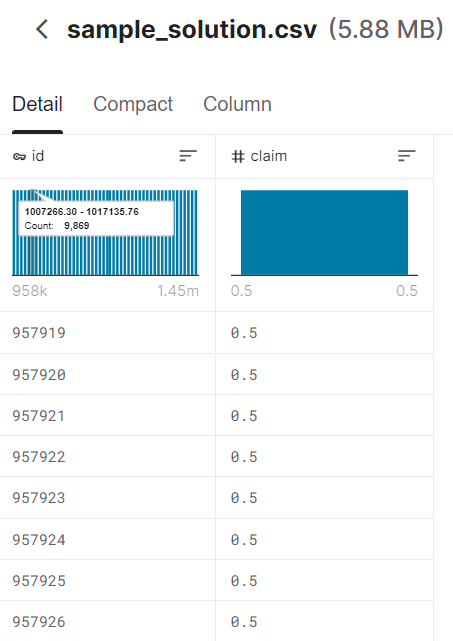
binary classification이긴 하지만 Submission은 각 test id별로 Claim Probability를 계산하여 제출해야 합니다.
1.2 Train
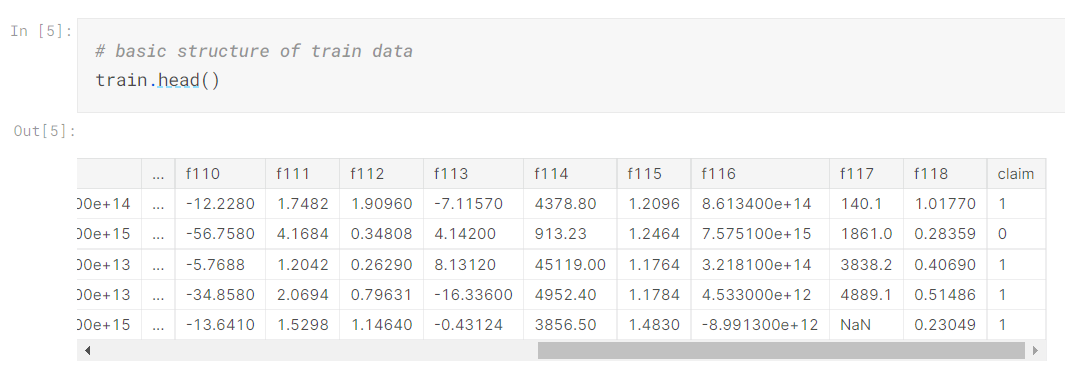
TPS의 Train data는 id, claim을 포함해 이름을 f1부터 f118까지 이름을 알수없는 features까지 총 120개의 features를 가지고 있습니다.
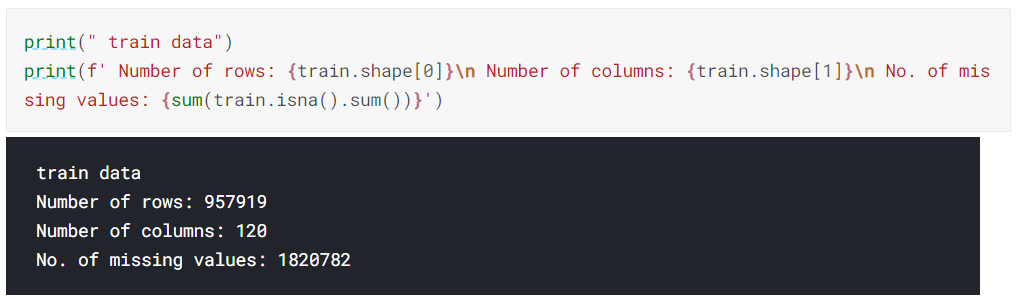
또한 상당히 많은 missing value가 존재하고 있습니다.
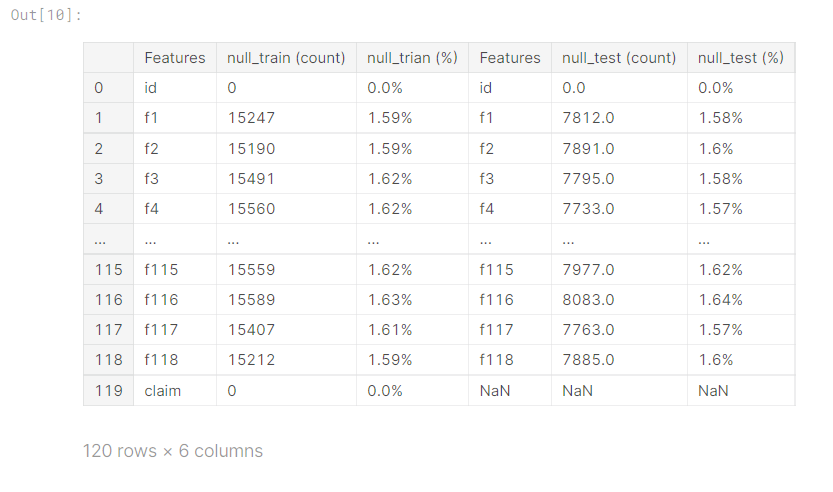
이 missing value가 특정 row나 column에 집중 된 것이 아닌 고르게 분포 되어 있기 때문에 저희 팀은 이 missing value를 채우는 것을 가장 중점적으로 생각하였습니다.
1.3 Test
test도 train과 같은 구성으로 claim을 제외한 119개의 feature로 구성되어 있습니다.
2. EDA
저희 팀의 EDA목표는 missing value를 가장 현명하게 채우는 방법 입니다.
2.1 Missing value exit or not?
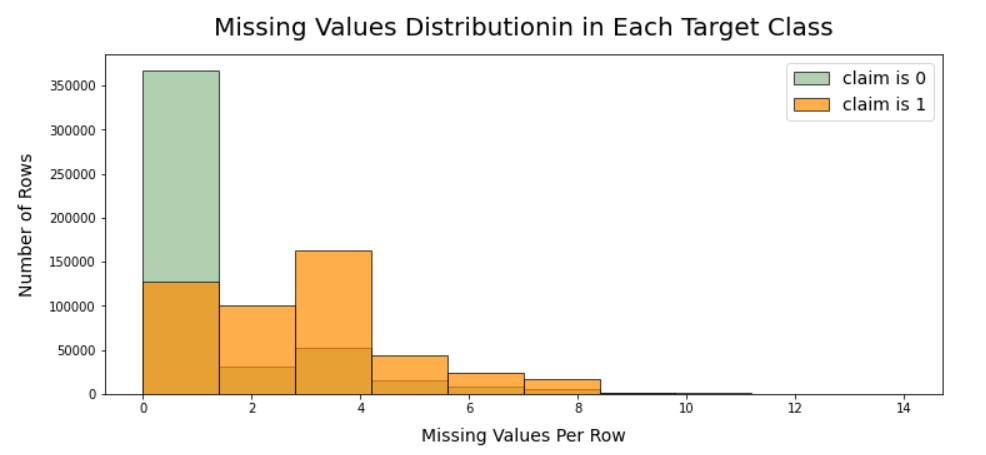
위 그래프는 claim이 0일 때와 1일 때의 missing value의 갯수를 표로 나타낸 것 입니다.
자세히 본다면 missing value가 존재할 때, claim이 1일 확률이 높은 것을 알 수 있습니다.
2.2 그렇다면 어떻게 채울 것 인가?
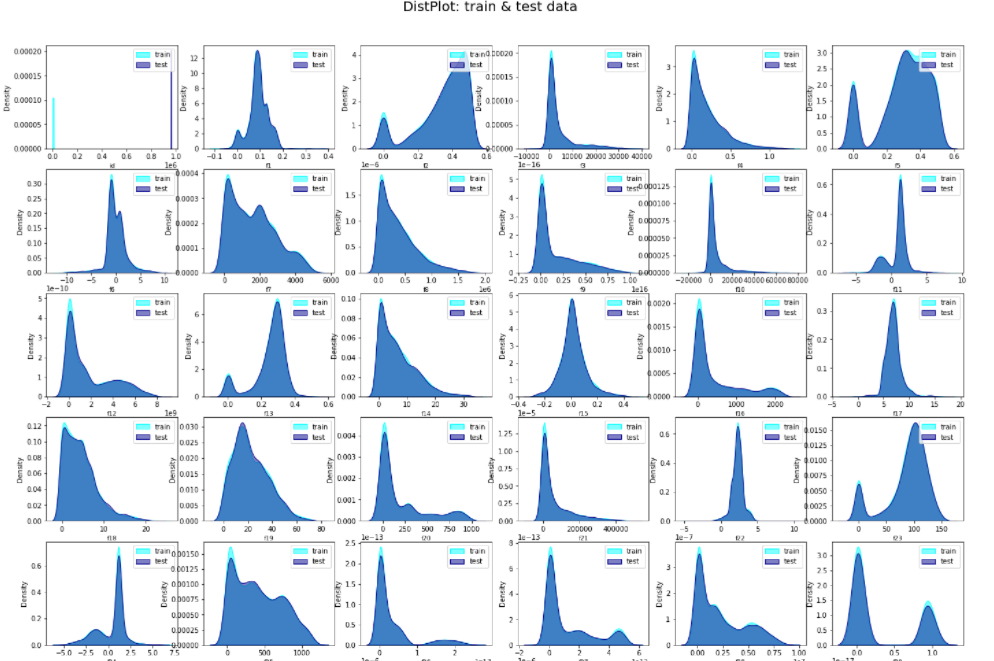
train data의 분포를 그래프로 그린 것 입니다.
features가 전부 다른 분포 모양을 하고 있습니다만 저희 팀은 그 중 최대한 정규분포와 비슷한 features, peak이 여러개인 features로 구분하였습니다.
즉 정규분포와 비슷한 분포를 가진 features는 mean을, peak이 여러개인 features는 Median 75를 사용하였습니다.
Median 75를 사용한 이유는 최대 빈출 값을 사용하려고 하였으나 75%정도의 빈출 값이 더 좋은 성능을 보여주었기 때문입니다.
2.3 그 외 전처리

missing value를 채우는 것 과 별개로 새로운 features를 추가하여 성능을 높이려는 노력을 하였습니다.
Train데이터를 보면 missing value가 존재 할 경우 claim이 1일 확률이 더 높았습니다. 그렇기 때문에 missing value의 갯수를 row별로 합산하여 새로운 feature를 생성하였습니다.
또한 여러 실험결과 row별 max, min, std값을 새로운 feature로 추가하였으며 모든 feature를 곱한 multiply라는 feature까지 총 5개의 feature를 추가하였습니다.
3. 모델
hyper parameter튜닝에 있어서는 Optuma를 활용하신 Vishwas Chepuri님의 글을 참고하였습니다.
https://www.kaggle.com/vishwas21/tps-sep-21-tuning-xgb-catb-lgbm-and-stacking
테스트에 사용한 모델은 총 3가지 입니다.
- XGBoost
- LightGBM
- Catboost
이 3가지 모델을 여러가지 features와 혼합하여 test한 결과 Catboost가 가장 좋은 성능을 보여주었습니다.
4. 결과

Private leaderboard기준 총 1942명의 팀 중 395위를 차지하였습니다. 상위 20%정도의 성적을 거둘 수 있었습니다.
4.1 반성점
사실 모델을 구성 할 때 Stacking을 사용한다면 더 좋은 점수를 낼 수 있을 것 이라고 생각하였습니다.
하지만 결국 Stacking을 구사하는 모델을 코딩 할 수 없었고 아쉬운대로 feature engineering와 catboost만 사용한 결과가 되었습니다.
마치며
이번 대회에서 저의 역할은 주로 modeling에 관한 부분이었습니다. 모델의 성능을 테스트하고 hyper parameter를 찾으며 어떤 features를 추가한 score가 가장 좋은 결과를 보여주는가를 주로 테스트하였습니다. 하지만 다른 부분에 관해서도 전적으로 팀원들과 상담하며 함께 진행하였고 active competition에 참가한 것은 처음이었기 때문에 답을 모르는 상태로 찾아 헤메는 상당히 귀중한 경험을 했다고 생각합니다.