
Jigsaw rate severity of toxic comments
시작하기에 앞서
- 이번 포스팅은 2021년 12월 6일 당시
kaggle의active competition으로 참가한 Jigsaw rate severity of toxic comments라는 competition입니다. - 이번 competition은 총 4인으로 진행되었으며 각자 역할을 가지고 토론한 내용을 아래 notion에 정리하였습니다.
https://crystalline-pan-4ae.notion.site/HOME-KIN-L-P-757de4fc08dc4ec3932c0abadcaa8351
- 제가 담당한 역할은
Transformer를 활용한 접근법이며 아래 노트북은 팀의 최종 제출 결과물이 아니며 제 담당부분만 공유하였습니다.https://www.kaggle.com/tolight20/jigsaw-starter-roberta-rowruddit-mrl
https://www.kaggle.com/tolight20/jigsaw-starter-roberta-1st-mrl
https://www.kaggle.com/tolight20/0-828-jigsaw-dl-ensemble-inference - 위 노트북은 아래 노트북을 참고하였습니다.
https://www.kaggle.com/debarshichanda/pytorch-w-b-jigsaw-starter
https://www.kaggle.com/leolu1998/jigsaw-ensemble-tfidf-bert
문제 정의
이번 competition은 reddit에서 추출한 comments의 toxicity, 즉 유해도를 측정하는 문제 입니다.
특이사항으로는 toxicity는 score형식으로 제출함과 동시에 score의 범위는 상관 없으며, 동점을 인정하지 않는다. 입니다.
즉, 제출된 점수를 토대로 comments사이의 ranking을 매기는 시스템이라고 판단 됩니다.
데이터 정의
보통 kaggle의 competition은 train dataset이 정의되어 있습니다. 하지만 이번 competiton은 train data가 정의되어 있지 않습니다.
competition에서 주어진 데이터는 제출에 사용되는 test data격인 commenttoscore.csv파일과 학습에 사용 할 수 있는 validation_data.csv파일이 있습니다.
그렇기 때문에 주어진 validation_data.csv파일 이외에도 학습에 사용 할 수 있는 데이터를 사용하는 것이 가능합니다.
전략
저희 팀이 주목한 포인트는 Ensemble입니다.
공식 train dataset이 없기 때문에 더 좋은 데이터를 더 좋은 모델로 학습시켜 Ensemble시키는 것이 저희 팀 전략의 근본입니다.
Ensemble
Ensemble은 여러개의 기본모델을 활용하여 하나의 모델을 만들어내는 개념입니다.
즉 A라는 데이터를 B라는 모델로 학습시킨 C라는 결과와 D라는 데이터를 E라는 모델로 학습시킨 F라는 결과를 이용해 성능향상을 노릴 수 있습니다.
그렇기 때문에 저는 Transformer를 통해 문제를 해결하는 접근법을 담당하였으며 이번 포스팅에서는 Transformer만을 이용한 Ensemble을 다룰 예정 입니다.
PLMs의 구조
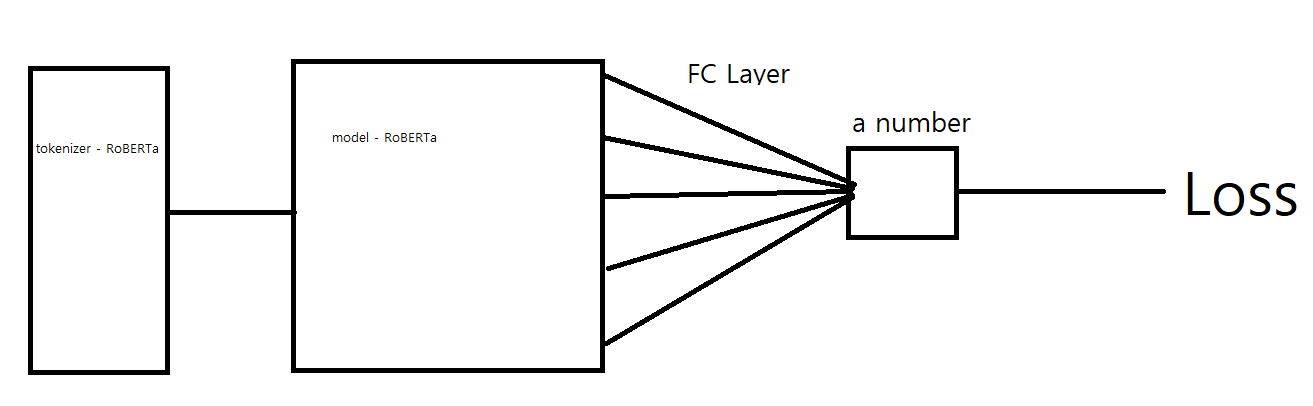
위 그림은 PLMs로 학습된 모델이 스코어를 산출하는 모식도 입니다.
아래 자료를 읽기전에 머리속에 넣고 계신다면 도움이 될 것 입니다.
코드로는 아래와 같이 표현되었습니다.
class JigsawModel(nn.Module):
def __init__(self, model_name):
super(JigsawModel, self).__init__()
self.model = AutoModel.from_pretrained(model_name)
self.drop = nn.Dropout(p=0.2)
self.fc = nn.Linear(768, CONFIG['num_classes'])
def forward(self, ids, mask):
out = self.model(input_ids=ids, attention_mask=mask,
output_hidden_states=False)
out = self.drop(out[1])
outputs = self.fc(out)
return outputs
데이터별 모델 선택
1.validation_dava.csv
이번 competition에서 제공하는 데이터 셋 입니다. 한 쌍의 코멘트가 less toxic, more toxic으로 구분되어 있습니다.
- Criterion : MRL
- 전처리 방법 : 전처리를 하지 않습니다.
- Embedding : PLMs tokenizer
- Model :
RoBERTa-baseRoBERTa-largeAlBERT-base - Fine tuning : Fully Connected
- Training 과정 및 결과
RoBERTa-base tokenizer-RoBERTa-base model-FullyConnected0.816(TOP)RoBERTa-large tokenizer-RoBERTa-large model-FullyConnectedFailed - OoMAlBERT-base tokenizer-AlBERT-base model-FullyConnected0.807
2.Ruddit data
Ruddit은 https://aclanthology.org/2021.acl-long.210/ 에서 참고한 데이터 셋 입니다.
한 comment에 score가 -1부터 1까지 labeling되어 있습니다.
- Criterion : MSE, MRL
- 전처리 방법
- non-toxicity 제거 : Score가 음수로 표현되는 문장은 Score를 0으로 통일하였습니다.
- non-toxicity 제거 안함
- MRL을 사용할 경우 text-score labeling되어 있는 데이터를 가공하여 less, more쌍으로 만듬
- Embedding : PLMs tokenizer
- Model :
RoBERTa-baseAlBERT-base - Fine tuning : Fully Connected
- Training 과정 및 결과
non-toxicity 제거 X-Less, More labeling-RoBERTa-FullyConnected0.811(TOP)non-toxicity 제거 X-AlBERT-base-FullyConnected-3epochs0.608non-toxicity 제거-RoBERTa-base-FullyConnectedFailed - OoMnon-toxicity 제거-AlBERT-base-FullyConnected0.483non-toxicity 제거 X-AlBERT-base-FullyConnected-30epochs0.603
3.Jigsaw Toxic comment classification challenge
Jigsaw에서 최초로 주최한 대회에서 제공한 train dataset입니다.
이번 대회는 train dataset이 없지만 저 당시는 comments를 toxicity를 세분화 하여 분류하고자 하였고 그 때 사용한 train dataset이 남아있습니다.
- Criterion : MSE, MRL
- 전처리 방법
- toxic, severe_toxic, obscene, threat, insult, identity_hate로 구분된 분류를 severe_toxic만 2점으로 처리한 후 합산
- MRL을 사용할 경우 text-score labeling되어 있는 데이터를 가공하여 less, more쌍으로 만듬
- Embedding : PLMs tokenizer
- Model :
AlBERT-base - Fine tuning : Fully Connected
- Training 과정 및 결과
Less, More labeling-RoBERTa-base-FullyConnected0.799(TOP)AlBERT-base-FullyConnected0.692
여러 실험의 결과 각 데이터 별로 TOP score를 기록한 모델을 Ensemble 하게 되었습니다.
with code
set_model_name('roberta')
MODEL_PATHS = set_model_path_name('../input/pytorch-w-b-jigsaw-starter')
set_seed(CONFIG['seed'])
test_dataset = JigsawDataset(df, CONFIG['tokenizer'], max_length=CONFIG['max_length'])
test_loader = DataLoader(test_dataset, batch_size=CONFIG['test_batch_size'],
num_workers=2, shuffle=False, pin_memory=True)
preds1 = inference(MODEL_PATHS, test_loader, CONFIG['device'])
# ------------------------------------------------------------------------------------------
set_model_name('roberta')
MODEL_PATHS = set_model_path_name('../input/jigsaw-starter-roberta-rowruddit-mrl')
set_seed(CONFIG['seed'])
test_dataset = JigsawDataset(df, CONFIG['tokenizer'], max_length=CONFIG['max_length'])
test_loader = DataLoader(test_dataset, batch_size=CONFIG['test_batch_size'],
num_workers=2, shuffle=False, pin_memory=True)
preds2 = inference(MODEL_PATHS, test_loader, CONFIG['device'])
# -------------------------------------------------------------------------------------------
set_model_name('roberta')
MODEL_PATHS = set_model_path_name('../input/jigsaw-starter-roberta-1st-mrl')
set_seed(CONFIG['seed'])
test_dataset = JigsawDataset(df, CONFIG['tokenizer'], max_length=CONFIG['max_length'])
test_loader = DataLoader(test_dataset, batch_size=CONFIG['test_batch_size'],
num_workers=2, shuffle=False, pin_memory=True)
preds3 = inference(MODEL_PATHS, test_loader, CONFIG['device'])
각 모델에 해당하는 노트북을 MODEL_PATHS에 연결하여 preds라는 점수를 얻은 상태 입니다.
preds1 = (preds1 - preds1.min()) / (preds1.max() - preds1.min())
preds2 = (preds2 - preds2.min()) / (preds2.max() - preds2.min())
preds3 = (preds3 - preds3.min()) / (preds3.max() - preds3.min())
preds = (preds1 + preds2 + preds3)/3
이렇게 얻은 preds를 min,max정규화를 해준 뒤 점수를 합산 하고 나눠주는 것으로 Ensemble을 구현하였습니다.
정규화를 해주는 이유는 각 모델에서 산출한 score의 scale이 제각각이기에 맞춰 준 것이며 사실상 Ensemble은 각 preds의 비중을 다루게 주어야 합니다만
실험 결과 1:1:1의 비율이 가장 좋은 성능을 보여주었습니다.
마치며
지금 사용된 notebook의 점수는 0.828로 아직 competition이 끝나지 않아 12월 06일 기준 public leaderboard기준 상위 33% 정도 되는 수준입니다.
물론 이 점수가 저희 팀의 스코어는 아니고 제가 담당한 부분만 최대한 성능을 끌어올린 결과라고 생각합니다.
이번 competition에 참가한 이유가 DL의 최신이라고 생각되는 Transformer를 활용하고 숙달하는 것 이기 때문에 이 부분에 관해서는 상당히 목적을 달성했다고 생각합니다.
하지만 그 외에도 여러 사람의 discussion이나 공개된 notebook을 보면서 구조화 된 코드에 대해서 인지하게 되었고 무었보다 협업을 하면서 자신에게 필요한 부분을 수정하거나 추가함을 통해 유지보수가 가능한 코드에 조금 가까워졌다고 생각합니다.
뿐만 아니라 train dataset조차 존재하지 않는 특수한 과제에서 성능을 뽑아내기 위해 고민하고 실험한 과정 자체가 무엇보다 중요한 경험이라고 생각합니다.
저희 팀의 최종 score는 0.855로 현재 12월 6일 public leaderboard기준 상위 11% 입니다.