
EDA - LoanGrade data
시작하기에 앞서
- 이번 포스팅은
kaggle의 데이터 셋인All Lending Club loan data에 대한 EDA입니다. - 작업 환경은
Colab이며 코드는 아래 링크에 공유되어 있습니다.https://github.com/nanoteyep/ToyProject/blob/main/EDA/LendingCLUB/LendingClub_EDA.ipynb
1. 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats
pd.options.display.max_rows = 1000
- 파이썬으로 데이터 분석을 하기 위한 기본적인 라이브러리 4종입니다.
scipy.stats는feature사이의 상관계수를 구하기 위해 사용되었으나 현재 최종본인 이 코드에서는 사용하지 않습니다.Loan data가 행과 열 모두 워낙 큰 사이즈를 가지고 있기에pd.options.display.max_rows = 1000를 써줘 …으로 생략하지 않고 1000줄까지 보여주도록 합니다.
2. 데이터 살펴보기
# PATH is have to be changed by your PATH
acc_df = pd.read_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/accepted_2007_to_2018Q4.csv")
rej_df = pd.read_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/rejected_2007_to_2018Q4.csv")
Loan data에는accepted,rejected총 두가지파일이 있습니다.
acc_df.shape
# (2260701, 151)
acc_df.head().T
rej_df.head().T
accepted는 2260701X151이라는 어마어마한 사이즈를 가지고 있습니다.- 그냥
head()를 출력하면column조차 생략되서 나오기 때문에 행과 열을 뒤집어 준 후 출력합니다. - 그리고 151개나 되는
accepted의column들을 이해가 되지 않더라도 일단 하나씩 읽어봅니다.
2.1 accepted 와 rejected
- 두 파일은 상당히 다릅니다.
- 우선 사이즈가 확연하게 다릅니다.
- 또한 가지고 있는
column들이Zip code,State이외에는 전부 다릅니다. - 그렇기 때문에 두 테이블을 만약 합쳐 같이 사용하게 된다면 엄청난 데이터들이 거의
none로 뒤덮일 것 입니다. - 따라서 이번 포스팅에서는 과감하게
rejected파일을 사용하지 않겠습니다. - 또한
accepted내에서도Grade라는 feature에 집중하여 분석하도록 하겠습니다. Grade를 선택한 이유는 단순히 재밌어 보이기 때문입니다.
3. 데이터 전처리
- 원래 데이터 전처리는 EDA이후에 본연의 목적에 맞게 데이터를 과공하는 단계 입니다.
- 하지만 이번 데이터는 우선 사이즈가 너무 크고 필요 없는 데이터도 많아보이기에 분석 효율을 위해 먼저 데이터를 정리해주도록 하겠습니다.
droped = acc_df.columns[acc_df.isnull().sum() > 10000]
data = acc_df.drop(droped, axis=1)
- 우선
null값이 10000개가 넘어가는column을 전부 없애줍니다. - 대출 등급은 대출심사 직후, 즉 데이터가 데이터베이스에 등록되는 순간 부여되는 것 이라고 생각했으며
null값이 21만개 중 1만개나 있다면 이 값들은 대출심사 이후에, 사후에 붙여지는feature라고 생각했기 때문입니다. - 즉
Grade에는 아무런 영향을 끼치지 못하였다고 자동적으로 판단되기에 지워줍니다. - 또한 이 시점부터 데이터프레임의 이름이
data로 변경됩니다.
data.isnull().sum()
data.drop(data[data['loan_amnt'].isnull()].index, axis=0, inplace=True)
data.isnull().sum()
- 다시한번
null값을 확인 한 후loan_amnt가null인rows를 지워줍니다. - 대출정보인데 대출값이
null인 데이터는 필요 없다고 생각했기 때문입니다.
corr_data = data.corr()
corr_data
- 또한 수치데이터들의 상관계수를 구해봅니다.
- 결과 상관계수가 비정상적으로 높은 변수들이 발견되는데 이는 유사값이라고 판단하여 전부 거르겠습니다.
- 그 예로는
loan_amnt와funded_amnt,funded_amnt_inv가 있으며 이중에서loan_amnt만 사용하게 됩니다.
data.drop(data[data['annual_inc'] == max(data['annual_inc'])].index, axis=0, inplace=True)
data.drop(data[data['annual_inc'] == max(data['annual_inc'])].index, axis=0, inplace=True)
- 추 후에 분석하면서 발견한 사실입니다만 매년 수입이 진짜 비정상적으로, 거의 모든 사람들의 100배쯤 되는 사람이 두명 있습니다.
- 가만히 놔두면 스케일이 엄청 이상해지므로 이상치라 생각하여 제거해주었습니다.
df = pd.DataFrame({'loan_amnt':data['loan_amnt'],
'term':data['term'],
'int_rate':data['int_rate'],
'grade':data['grade'],
'sub_grade':data['sub_grade'],
'home_ownership':data['home_ownership'],
'annual_inc':data['annual_inc'],
'verification_status':data['verification_status'],
'loan_status':data['loan_status'],
'purpose':data['purpose'],
'addr_state':data['addr_state'],
'dti':data['dti'],
'fico_range_middle':(data['fico_range_high']+data['fico_range_low'])/2,
'total_pymnt':data['total_pymnt'],
'total_rec_int':data['total_rec_int']})
df.head()
categorical feature, 즉 수치가 아닌str로 작성된features는 일일이 읽고Grade와 관계 있을지 생각해 줍니다.fico_range_middle의 경우high와low값이 있었기에 두값의 평균값을 구하여 넣어주었습니다.- 이렇게 선정된 데이터만
df라는 데이터 프레임속에 저장하였으며 앞으로는 이df라는 데이터프레임을 가지고 분석을 진행할 예정입니다.
df.sort_values(by=['grade'], axis=0, inplace=True)
- 추 후에 시각화 데이터가 이쁘게 나오기 위해
grade순으로 정렬합니다.
# Making grade to score
fix_dict = """A:7 B:6 C:5 D:4 E:3 F:2 G:1"""
fix_dict = dict(dictset.split(':') for dictset in fix_dict.split())
df['scored_grade'] = df['grade'].apply(lambda v: fix_dict.get(v, v))
# To numerical calculation, Make scored_grade into numerical
df['scored_grade'] = df['scored_grade'].apply(pd.to_numeric)
# Also Sub_grade reflect to scored_grade
df['scored_grade'] += (5 - df['sub_grade'].str.get(i=-1).apply(pd.to_numeric)) * 0.2
df.head()
grade를 수치화 하기 위한 작업입니다.- 먼저 A부터 G까지의 등급을 7부터 1까지의 점수를 주고
scored_grade에 저장합니다. - 이후
sub_grade또한scored_grade에 반영합니다. sub_grade는 1이 가장 좋으며 5가 최하기 때문에 1은 +0.8, 2는 +0.6, 3은 +0.4, 4는 +0.2, 5는 +0점을 주었습니다.
# PATH is have to be changed by your PATH
df.to_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/df.csv")
data.to_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/data.csv")
Colab에서 작업하다보니 런타임 오류가 자주생깁니다.- 지금까지 가공한 데이터를 저장하여 모든 코드를 처음부터 다시 돌려야 하는 불상사를 막아줍니다.
4. 분석 및 시각화
# PATH is have to be changed by your PATH
data = pd.read_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/data.csv")
df = pd.read_csv("/content/drive/MyDrive/정상빈/미니프로젝트 EDA/df.csv")
- 런타임 에러 등으로 다시 시작해야 하는 경우 여기서 부터 시작하는 일종의 세이브 포인트입니다.
df.head()
df를 print해 놓음으로서 분석에 용이하게 사용합니다.
4.1 수치형 데이터
corr = df.corr()
corr
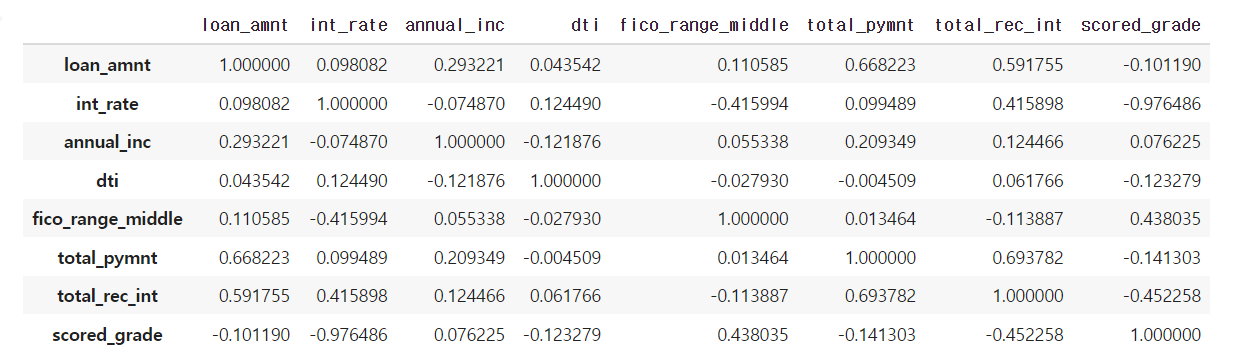
- 먼저
df의 수치데이터 끼리의 상관관계를 구해줍니다. - 이 중
scored_data와 밀접한 상관관계를 가지는features는int_rate,fico_range_middle,total_rec_int입니다.
sns.heatmap(corr)
- heatmap도 그려보았지만 그렇게 의미가 있어 보이지는 않습니다.
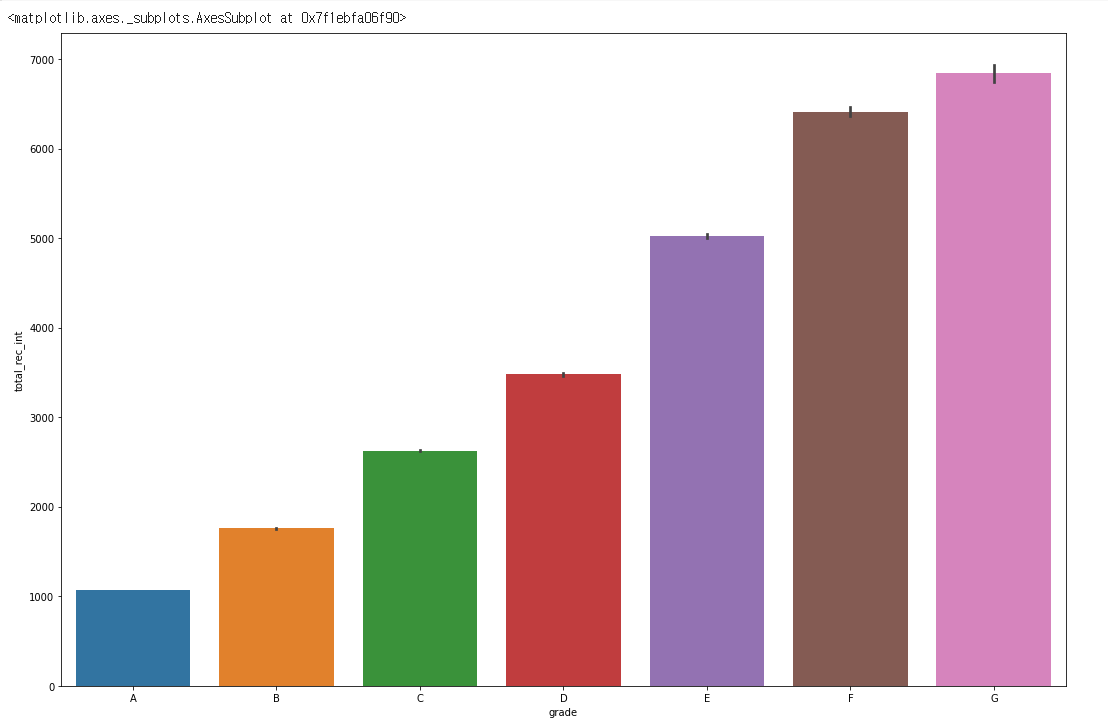
plt.figure(figsize=(18, 12))
sns.barplot(data= df, y = 'int_rate', x = 'grade')
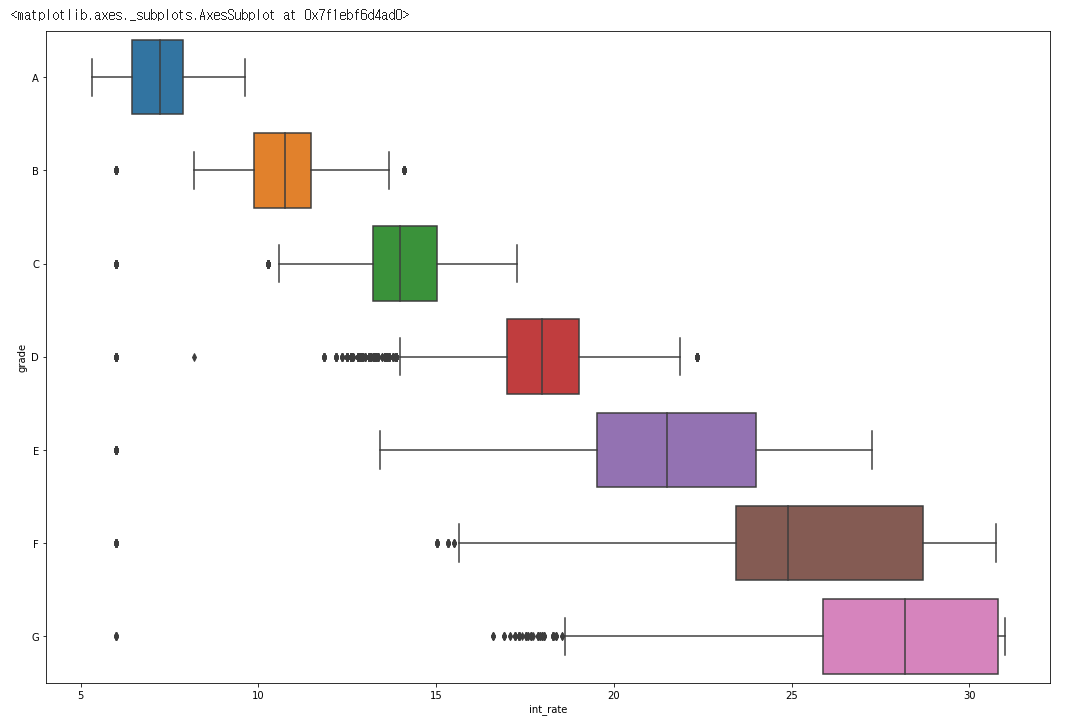
plt.figure(figsize=(18, 12))
sns.boxplot(data= df, x = 'int_rate', y = 'grade')
- 그렇다면 이제부터 밀접한 상관관계를 가지는 세 변수를 차례대로 시각화 해보도록 하겠습니다.
- 가장먼저
int_rate는이자율입니다. - 명확하게
grade와 음의 상관관계를 가지고 있으며barplot은 이를 잘 보여주고 있습니다. -
boxplot은int_rate의 분포를 잘 보여주며grade가 낮이질수록 더 넓은 분포를 보여주고 있습니다. - 이를 통해
grade는이자율이 낮아 질 수록 높은 등급을 받으며 분포도가 상당히 넓게 나오기 때문에이자율이외에도 다양한features에 영향을 받는 다는 것을 알 수 있습니다.
plt.figure(figsize=(18, 12))
sns.barplot(data= df, y = 'total_rec_int', x = 'grade', hue = 'grade')
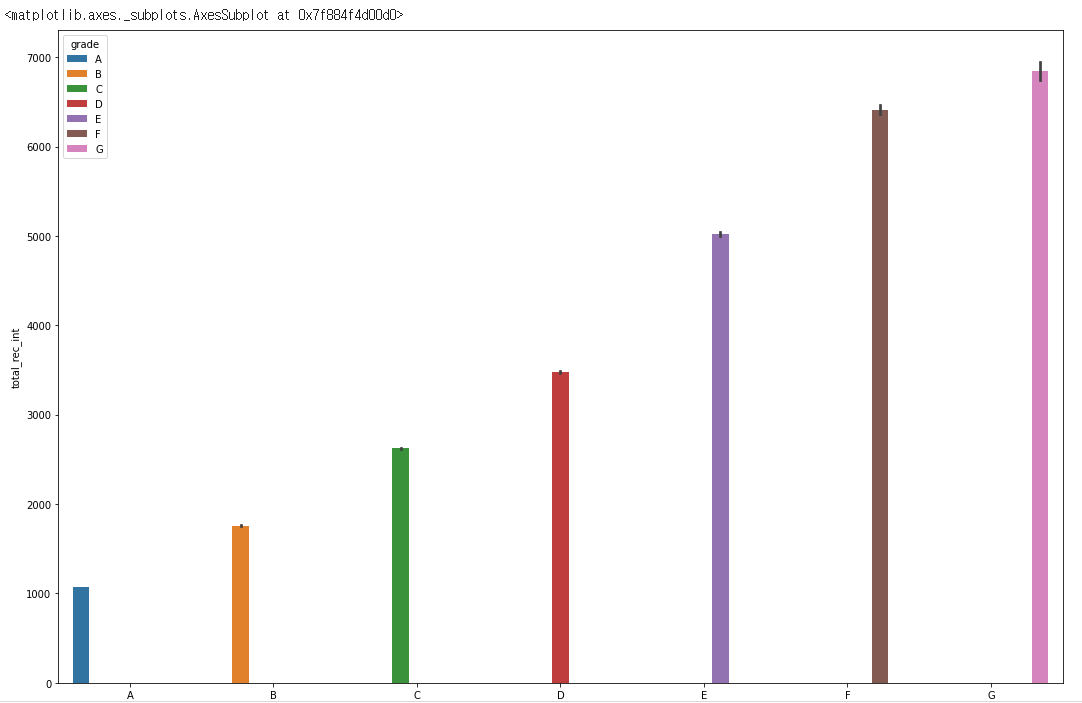
plt.figure(figsize=(18, 12))
sns.boxplot(data= df, x = 'total_rec_int', y = 'grade')
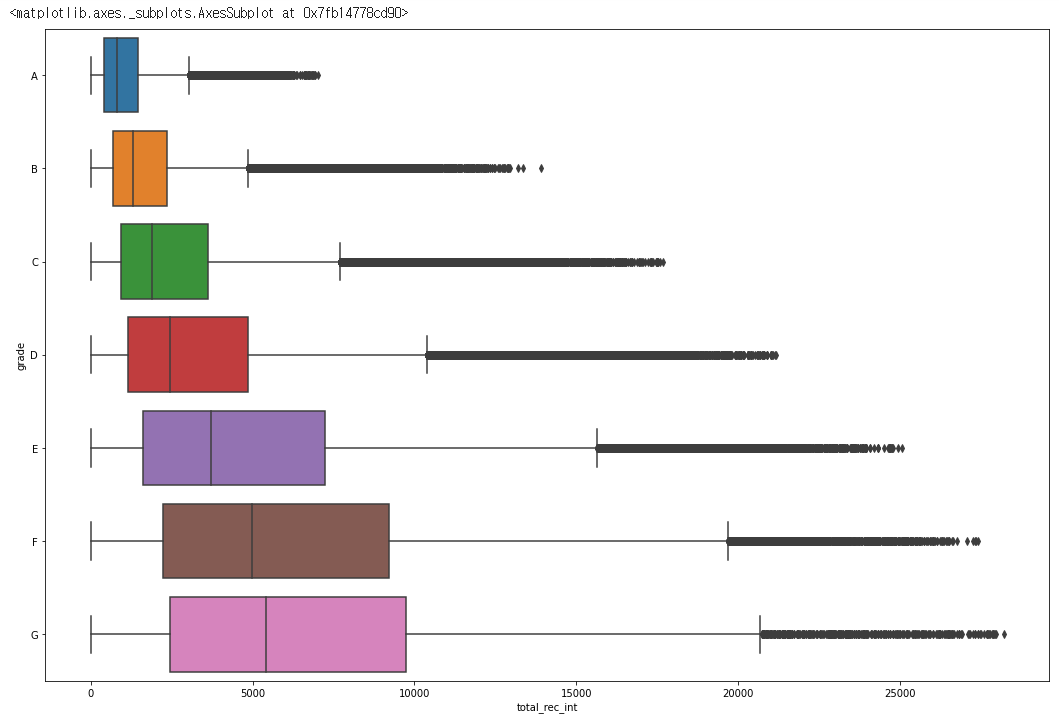
total_rec_int또한 상당히 눈에 보이는 음의 상관관계를 가지고 있습니다.- 다만 분포가 상당히 넓고 이상치또한 엄청 많습니다.
- 따로 알아본 결과 아마 total recieve interest rate의 약자로 추정되며 연체된 이자율의 총합으로 추정됩니다.
- 즉
total_rec_int는 추후에 입력되는 값으로 추정되며grade가 높을수록total_rec_int가 낮게 나올 가능성이 높다, 정도로 해석 할 수 있을 것 같습니다.
plt.figure(figsize=(18, 12))
sns.barplot(data= df, y = 'fico_range_middle', x = 'grade')
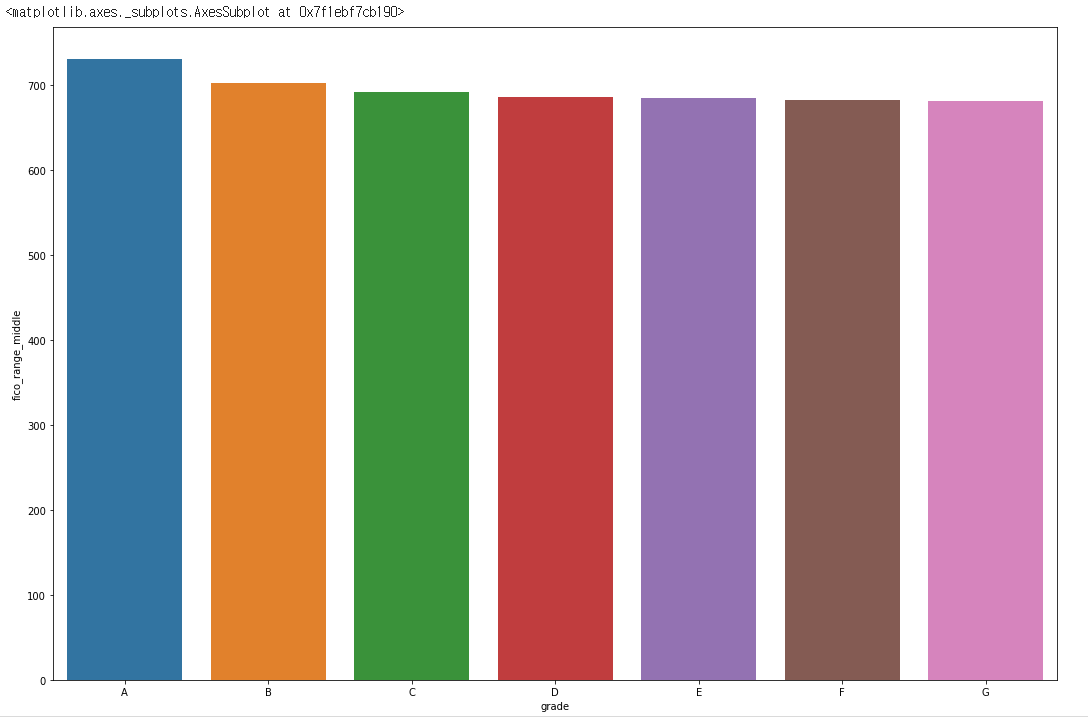
- 다음
feature인fico_range_middle입니다. - 수치상으로는 밀접한 상관관계가 보였으나
barplot상에서는 큰 차이가 보이지 않습니다.
plt.figure(figsize=(18, 12))
sns.boxplot(data= df, x = 'fico_range_middle', y = 'grade')
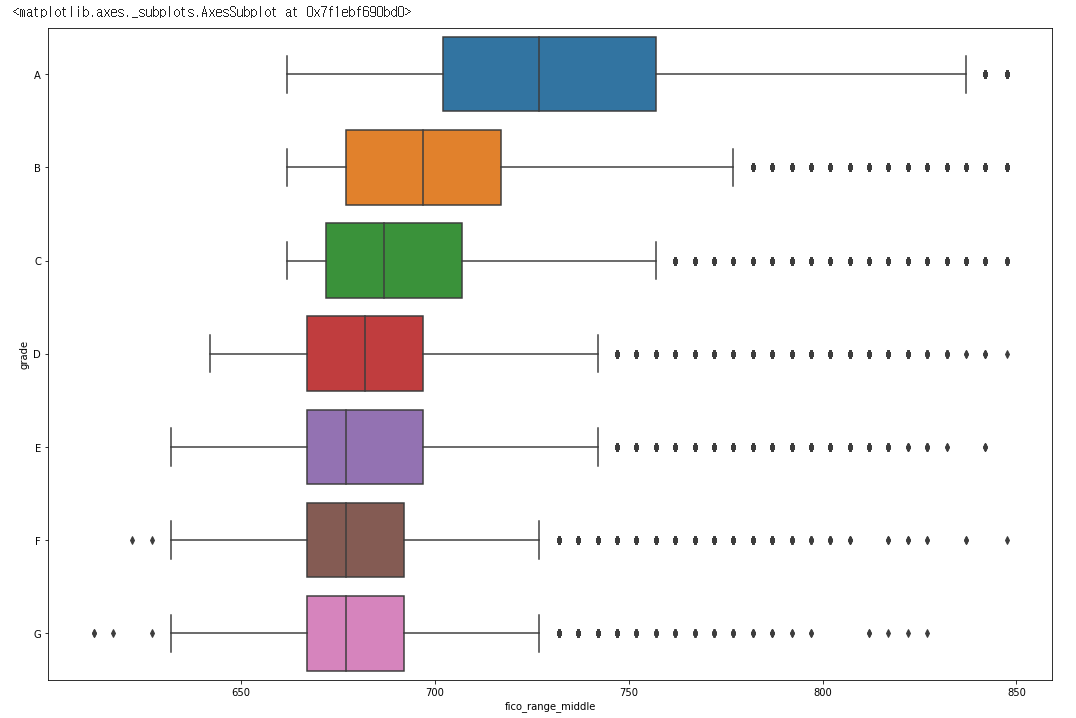
- 분포를 살펴본 결과 분포가 상당히 넓고 이상치 또한 넓은 범위로 분포해 있음을 알 수 있습니다.
- 따라서 좀 더 명확한 상관관계를 얻기위해 평균값을 사용하는
lineplot을 사용하기로 하였습니다.
plt.figure(figsize=(18, 12))
sns.lineplot(data= df, x = 'fico_range_middle', y = 'scored_grade')
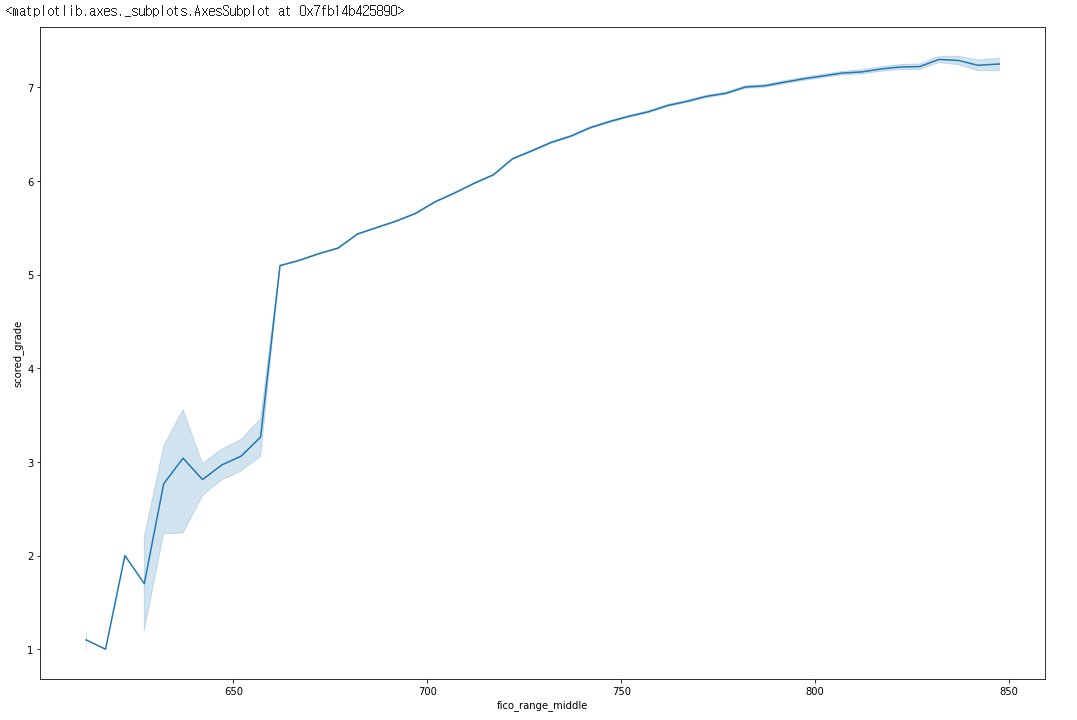
lineplot상에서는 명확한 상관관계가 보이고 있습니다.fico score는 미국의 신용등급 점수 입니다.- 하지만
grade가 낮을 때는 상당히 밀접한 양의 상관관계를 보이나grade가 높아질 수록 그 상관관계가 옅어지는 것을 알 수 있습니다. - 즉
fico_range_middle즉 신용등급 점수가 낮다면 낮은grade를 받을 확률이 높으나 일정치 이상에서는 그렇게 큰 영향을 끼치지는 않는다는 것을 알 수 있습니다.
4.2 범주형 데이터
plt.figure(figsize=(18, 12))
sns.countplot(data=df, x='grade', hue='loan_status')
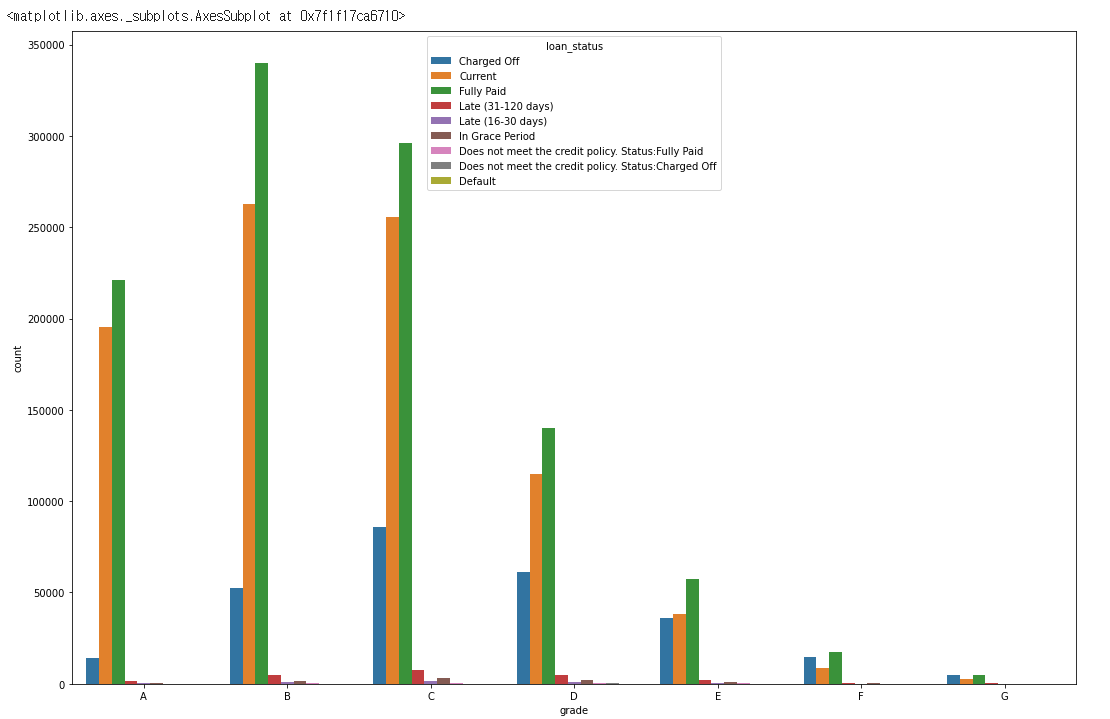
loan_status는 대출의 현재 상태를 알려줍니다.Current는 대출이 현재 상환이 진행중 이라는 뜻이며Charged off는 파산등의 이유로 상환이 완료되지 않고 종료된 경우,Fully paid는 상환이 종료된 경우 입니다.loan_status에 따라grade와의 관계를 시각화 해보았으나 얼핏 봐서는 명확한 관계를 알기 어렵습니다.
for grade in df['grade'].unique():
rate = len(df[(df['loan_status'] == 'Charged Off') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"{grade} has {rate:.2f}%")
#OUTPUT:
#A has 3.28%
#B has 7.92%
#C has 13.18%
#D has 18.82%
#E has 26.57%
#F has 34.67%
#G has 37.48%
grade별로Charged off의 비율을 구해보니 두 관계가 좀 더 명확해 졌습니다.- 즉
grade가 낮을수록 대출한 비용을 회수하지 못할 확률이 커진다는 것을 알 수 있습니다.
plt.figure(figsize=(18, 12))
sns.countplot(data=df, x='grade', hue='purpose')
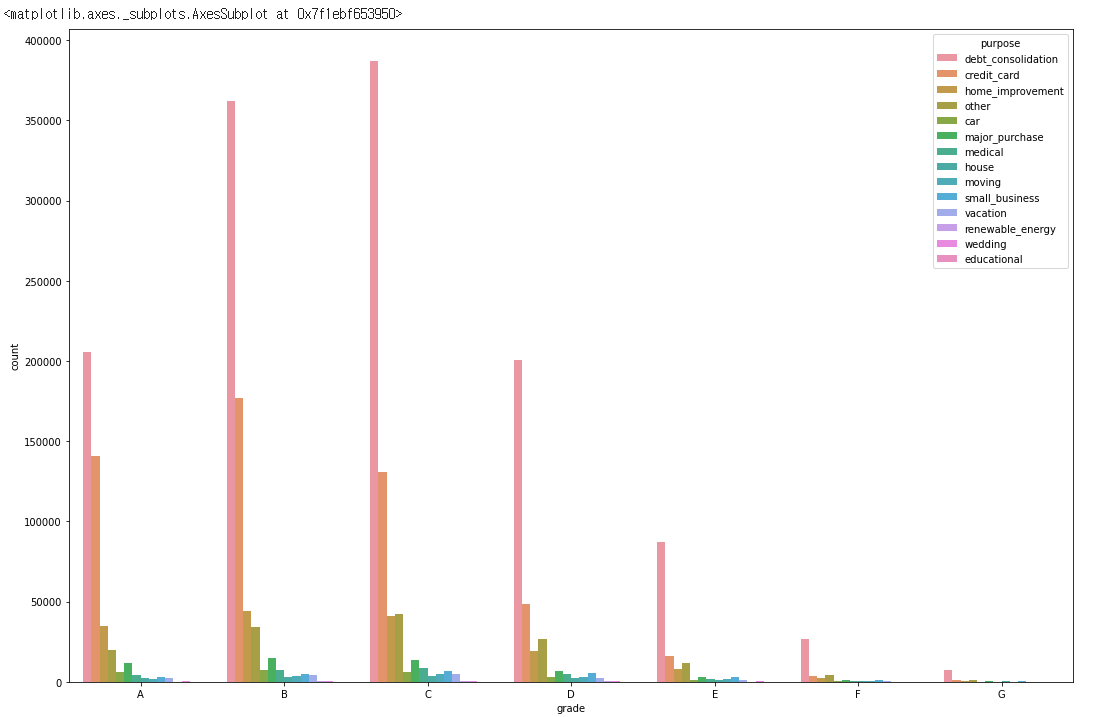
for grade in df['grade'].unique():
rate = len(df[(df['purpose'] == 'debt_consolidation') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"debt_consolidation, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['purpose'] == 'credit_card') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"credit_card, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['purpose'] == 'home_improvement') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"home_improvement, {grade} has {rate:.2f}%")
#OUTPUT:
#debt_consolidation, A has 47.55%
#debt_consolidation, B has 54.54%
#debt_consolidation, C has 59.58%
#debt_consolidation, D has 61.93%
#debt_consolidation, E has 64.33%
#debt_consolidation, F has 64.58%
#debt_consolidation, G has 62.41%
#credit_card, A has 32.45%
#credit_card, B has 26.64%
#credit_card, C has 20.08%
#credit_card, D has 15.03%
#credit_card, E has 11.63%
#credit_card, F has 8.99%
#credit_card, G has 7.10%
#home_improvement, A has 7.97%
#home_improvement, B has 6.68%
#home_improvement, C has 6.30%
#home_improvement, D has 5.94%
#home_improvement, E has 5.99%
#home_improvement, F has 6.01%
#home_improvement, G has 6.08%
grade와purpose즉 대출 목적에 따라grade가 달라질 수 있는가 입니다.- 가장 많은 비중을 차지하는
debt_consolidation,credit_card,home_improvement의 비율을 확인해 보았습니다. - 살펴본 결과
debt_consolidation의 경우 높은grade를 받기 힘들며credit_card는 높은grade를 받을 확률이 높고home_imporvement는 별로 상관이 없는 것으로 판단됩니다.
plt.figure(figsize=(18, 12))
sns.countplot(data=df, x="grade", hue="verification_status")
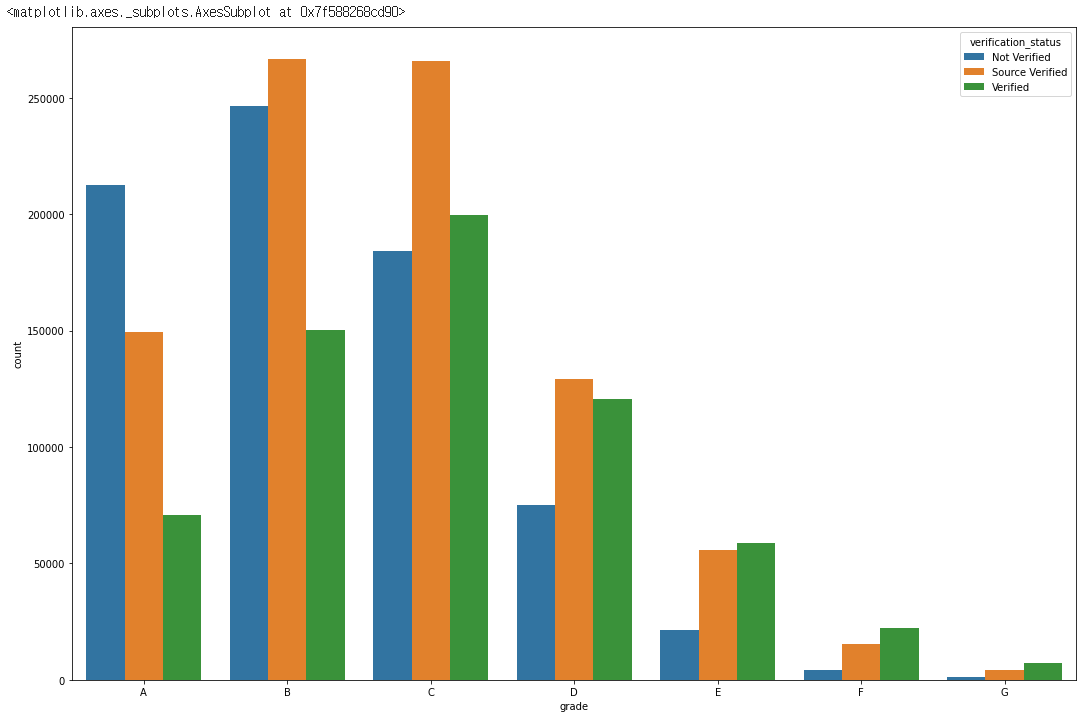
for grade in df['grade'].unique():
rate = len(df[(df['verification_status'] == 'Not Verified') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"not_verified, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['verification_status'] == 'Source Verified') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"Source verified, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['verification_status'] == 'Verified') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"Verified, {grade} has {rate:.2f}%")
#OUTPUT:
#not_verified, A has 49.10%
#not_verified, B has 37.15%
#not_verified, C has 28.33%
#not_verified, D has 23.09%
#not_verified, E has 15.66%
#not_verified, F has 10.37%
#not_verified, G has 8.47%
#Source verified, A has 34.51%
#Source verified, B has 40.23%
#Source verified, C has 40.92%
#Source verified, D has 39.77%
#Source verified, E has 40.96%
#Source verified, F has 36.43%
#Source verified, G has 33.08%
#Verified, A has 16.38%
#Verified, B has 22.62%
#Verified, C has 30.75%
#Verified, D has 37.14%
#Verified, E has 43.38%
#Verified, F has 53.20%
#Verified, G has 58.45%
- 사실
verification_status가 무었을 뜻하는지는 잘 모르겠습니다. - 하지만
not_verified의 경우 높은 확률로 높은grade를,Souce verfied는 관계가 없어보이며Verified는 높은 확률로 낮은grade를 받는 것으로 판단 됩니다.
plt.figure(figsize=(18, 12))
sns.countplot(data=df, x="grade", hue="home_ownership")
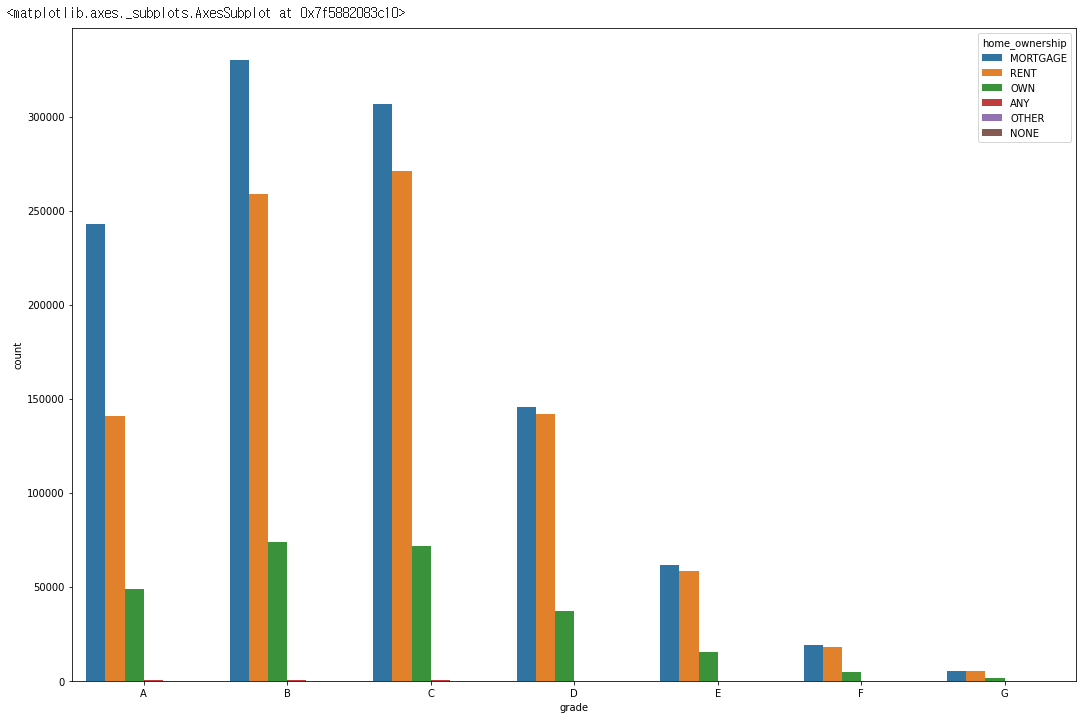
for grade in df['grade'].unique():
rate = len(df[(df['home_ownership'] == 'MORTGAGE') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"MORTGAGE, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['home_ownership'] == 'RENT') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"RENT, {grade} has {rate:.2f}%")
for grade in df['grade'].unique():
rate = len(df[(df['home_ownership'] == 'OWN') & (df['grade'] == grade)])/len(df[df['grade'] == grade])*100
print(f"OWN, {grade} has {rate:.2f}%")
OUTPUT:
MORTGAGE, A has 56.07%
MORTGAGE, B has 49.79%
MORTGAGE, C has 47.16%
MORTGAGE, D has 44.88%
MORTGAGE, E has 45.52%
MORTGAGE, F has 45.19%
MORTGAGE, G has 44.96%
RENT, A has 32.55%
RENT, B has 39.04%
RENT, C has 41.73%
RENT, D has 43.67%
RENT, E has 43.16%
RENT, F has 43.49%
RENT, G has 43.10%
OWN, A has 11.32%
OWN, B has 11.11%
OWN, C has 11.06%
OWN, D has 11.39%
OWN, E has 11.27%
OWN, F has 11.26%
OWN, G has 11.81%
- 마지막으로
home_ownership입니다. - 흥미로운건
OWN, 즉 집을 소유하고 있어도grade에는 큰 영향을 끼치지 않는다는 것 입니다. home_ownership은grade와 약한 상관관계를 가지고 있다는 것을 알 수 있습니다.
5. 결론
grade는 대출을 해주는 입장에서 얼마나 안전하게 대출금을 회수 할 수 있을까, 즉RISK를 나타내는 지표라고 판단됩니다.이자율이 높을 수록 대출금을 상환받는RISK가 커지기 때문에grade가 낮아진다고 생각합니다.- 실제로
grade가 낮을 수록Charged off비율이 높아져 대출금을 전부 상환하지 못한 것으로 판단됩니다. - 나머지
features또한RISK즉 상환 받을 수 없는 위험이 커질수록grade가 낮아지는 경향을 보이고 있습니다.
마치며
사실 처음 EDA를 시작할 때만 해도 grade는 대출회사 입장에서 수익을 극대화 할 수 있는 등급같은 것 이라고 생각했었습니다. 하지만 막상 EDA를 진행해보니 grade는 수익률 보다는 안정성, RISK에 치중된 등급이었으며 이를 결정짓는 요소도 상당히 다양한 것을 깨달았습니다.