
Recent Trends in Deep Learning Based Natural Language Processing
개요
이번 포스팅은 Paper Review 포스팅 입니다.
읽고자 하는 논문 리스트는 아래 고려대학교 DSBA lab에서 작성한 리스트를 사용하고 있습니다.
https://www.notion.so/c3b3474d18ef4304b23ea360367a5137?v=5d763ad5773f44eb950f49de7d7671bd
Paper
이번에 review하는 논문은 아래와 같습니다.
https://arxiv.org/abs/1708.02709
첫 Paper review로는 연구의 전체적인 흐름을 정리한 review paper가 가장 적합하다고 생각하여 이번 논문을 선택하게 되었습니다.
Abstract
이번 논문은 Review paper로 논문이 작성된 2017년을 기준으로 딥러닝 기반 NLP의 최신 동향을 정리해 놓았습니다.
Introduction
우선 NLP란 사람의 언어를 자동으로 분석하거나 표현하는 이론 기반의 컴퓨터 기술입니다.
몇십년 동안 NLP분야는 SVM이나 Logistic regression과 같은 Machine learning기반의 접근 방식을 사용하였지만 neural network기반의 deep learning이 더욱 뛰어난 성능을 보여주었고 기존의 사람의 손을 거쳐야하는 features에 비해 deep learning방식은 Word Embedding을 시작으로 자동으로 features를 표현해 주었습니다.
이번 paper에서는 NLP에서 주로 사용되는 CNN, RNN, Recursive neural network과 같은 모델은 물론 memory-augmenting stragies, attention, unsurpervied model, reinforcement learning, deep generative model과 같은 방식들이 어떻게 작동하는지 또한 review할 생각입니다.
이번 paper의 목차는 다음과 같습니다.
- distributed representation
- 주로 사용되는 모델
- unsupervied learning과 reinforcement learning에 의한 최신 접근방식
- memory module 과 같은 최신 트렌드
- 요약 및 성능비교
Distributed representation
초창기 NLP는 차원의 저주 문제에 무척 취약했습니다.
그렇기 때문에 단어를 좀 더 낮은 차원으로 표현하는 Distributed representation이 발전하였습니다.
-
Word Embedding
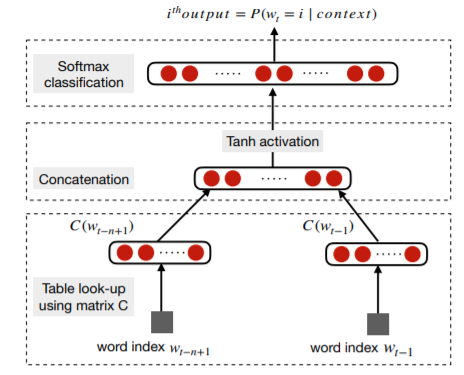
word embedding은 비슷한 문장에서 자주 쓰이는 유사한 단어를 찾는 것 입니다.
즉, 주변 단어를 이용하여 단어의 특징을 표현하는 것 입니다.
이러한 word embedding은 단어 사이의 유사성을 잘 파악합니다.
그렇기 때문에 word embedding은 보통 데이터의 preprocessing의 첫 layer에 등장하며 주로 unlabled된 corpus로 pre-trained하고 있습니다.
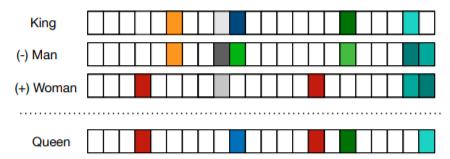
word embedding의 흥미로운 점은 위와 같이 word embedding된 두 단어사이의 연산이 의미를 연산한 것과 같은 결과가 나온다는 점 입니다. -
Word2vec
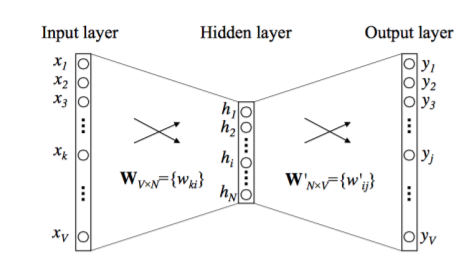
이러한 word embedding기술은 CBOW 와 Skip-gram이라는 개념에 의해서 급 성장하였습니다.
두 개념은 완전히 상반된 개념으로 CBOW가 window 내의 단어를 이용해 target word를 맞추는 방식, Skip-gram이 target word를 이용해 주변 단어를 맞추는 방식입니다.
위 그림은 CBOW을 도식화 한 것이며 CBOW는 한개의 hidden layer를 가진 Fully Connected neural network입니다.
필연적으로 모든 단어들은 W와 W’으로 표현이 가능하며 사용된 단어들은 한번에 h라는 인풋값으로 다루어지게 됩니다.
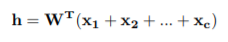
하지만 이렇게 개별단어를 embedding하는 과정은 몇가지 한계점이 있습니다.
그 첫번째는 바로 여러 단어의 조합으로 가지는 의미의 표현 불가 하다는 것 입니다.
이 문제의 해결책으로는 이렇게 조합적 의미를 가지는 단어들을 word co-occurrence를 기준으로 동일시 하여 train시키는 것 입니다.
후속 연구로 이 과정을 semi-supervied learning으로 하는 려는 시도가 있습니다.
두번째 한계는 window 밖에서 의미가 오는 경우 입니다.
이러한 경우 문맥상 good 과 bad가 동일한 의미를 가지게 되는 경우가 있는데 이는 감정평가와 같은 task에서 크게 작용하고 있습니다.
해결책으로는 SSWE라는 방식으로 임베딩을 학습시키는 동시에 supervied learning으로 단어의 sentiment polarity, 즉 단어의 감정 성격을 학습시켰습니다.
세번째 한게로는 word embedding방식의 경우 학습된 상황에 너무 의존한다 라는 것 입니다.
그렇기 때문에 task space에 걸맞게 다시 학습시키는 방식이 제안되었지만 이는 너무 시간과 자원이 많이 들어가기 때문에 negative sampling 이 제안되었습니다.
마지막으로 다중적인 의미를 지니는 단어의 경우 이를 해석할 수 없다는 것 입니다.
해결책으로는 multi-sense word embedding이라는 방식에서 사용되는 다국어의 parallel data에 기반하였습니다.
예를 들어 영어를 프랑스어로 번역하는 경우, bank는 banc와 banque라는 은행이라는 의미와 지리학에서 사용하는 의미를 둘다 제안하는 방식입니다. -
character embeddings
word embedding은 문법적으로도 의미적으로도 정보를 잘 캐치하고 있지만 특정 연구에서는 character level의 NLP가 적용되었고 더 좋은 성능을 보여주었습니다.
보통 사용된 단어로 사전을 만들다보면 OoV(Out of Vocabulary)문제가 발생합니다.
character embedding은 단어를 character의 조합으로 보기 때문에 이러한 문제를 피할 수 있으며 중국어와 같은 문장이 단어의 조합이 아닌 character의 조합으로 이루어진 경우 더 좋은 성능을 보여 주었습니다.
또한 character embedding을 이용하여 단어의 표현력을 향상시키려는 시도가 있었으며 이들은 단어를 bag of characger n-gram으로 표현하였고 이 시도는 OoV 이슈에도 매우 효과적이었으며 속도 또한 매우 빨라 FAST TEXT라고 부르고 있습니다.
이러한 distributed vector가 핫하지만 최근에는 이러한 방식이 단어의 개념적 의미를 얼마나 잘 캐치하는지 논란이 일고 있습니다.
이 논란 속에서 hot ice와 같은 단어의 개념적 의미를 제대로 이해하지 못한다는 결함이 발견되었고 이러한 결함을 해결하기 위한 방안이 최근 연구에서 인기를 끌고 있습니다.
- contextualized word embeddings
단어는 문맥에 따라 다른 의미를 지니기도 합니다.
하지만 word2vec 이나 glove와 같은 기존의 word embedding방식은 단순히 문장을 읽어들이며 단어 사전을 만들기 때문에 문맥에 따른 단어의 의미를 표현하지 못합니다.
그렇기 때문에 contextualied word embedding방식이 제안되었으며 Embedding from Language Model(ELMo) 가 이러한 방식을 사용한 embedding 방식입니다.
이 방식은 문맥별로 word embedding을 생성하였고 같은 단어일지라도 문장따라 다른 word embedding을 가지고 있습니다.
그렇기 때문에 같은 단어여도 다양한 표현이 가능하였고 위와 같은 특징을 deep contextual embedding이라고 합니다.
ELMo는 bidirectional language model로 작동합니다.
이는 forword LM과 backword LM이 concatnate된 형태로 forword LM은 LSTM을 통해 k-1번째 토큰을 입력하면 k번째 토큰을 예측하고 마지막 time step에 softmax가 붙어있는 전통적인 형태입니다.
backword LM은 완전히 이 반대의 형태로 k번째 토큰을 통해 k-1번째 토큰을 예측하고 첫 time step에 softmax가 붙어 있습니다.
이후 뒤늦게 pre-trained model에 대한 관심이 급증하기 시작합니다.
언어 모델은 자연어 이해나 생성에 대한 다양한 특징들을 포함하고 있기 때문에 random initialization하는 것 보다 unsupervied 된 pre-train이 더 좋다고 여겨지고 있습니다.
최근엔 GPT, BERT와 같은 Transformer를 적용한 pre-trained model이 제안되었습니다.
ELMo, GPT, BERT는 각각 다른 task를 사용하지만 그 중 BERT는 문장내의 단어를 특정 비율만큼 mask처리 한 후 이 mask를 예측하는 방식으로 작동합니다.
또한 여기서 그치지 않고 shuffle된 문장속에서 주어진 문장 다음 문장을 예측하도록 학습합니다.
이러한 시도는 기존의 bidirectional LM이 잡아내지 못했던 문장사이의 관계성을 catch하는 시도였으며 BERT는 무척 뛰어난 성능을 보여주었습니다.
Deep language model을 pre-train하는 방식은 최근 뛰어난 성능을 보여주고 있으며 이 흐름은 이미 computer vision분야에서 활발하게 이루어 지고 있습니다.
그렇기 때문에 NLP에서도 전통적인 방식보다는 pre-train을 활용한 모델이 선호될 것으로 예상됩니다.