
Python 기초 라이브러리 1
1. Numpy란?
- numpy 는 numerical python의 약자 입니다.
numerical computing이란 컴퓨터가 실수 계산을 효과적으로 할 수 있게 하는 연구분야 입니다.
vector arithmetic 이라는 벡터 연산으로 인해 데이터를 벡터로 계산 하고 더 효과적으로 하게 해줍니다.
- numpy는 다양한 머신러닝 라이브러리들에 의존성을 가지고 있고, 일반 파이썬 리스트에 비해 강력한 성능을 자랑합니다.
성능면에서 numpy array » python list( or tuble)
- python list와 비슷한 개념을 numpy에서는 numpy array라고 부릅니다.
numpy array는 파이썬 리스트처럼 여러 데이터를 한번에 다룰수 있으나, 모든 원소가 동일한 데이터 타입을 가져야 합니다.
2. Numpy의 특징
1) numpy array는 모든 원소의 자료형이 동일해야 합니다.
np.int8, np.float16, np.complex32 등등 다양한 자료형을 numpy에서 지원합니다.
int, float, complex는 각각 정수, 실수, 복소수를 나타내는 자료형이며 뒤의 숫자는 8byte, 16byte 와 같이 한 numpy array에 할당된 메모리를 의미합니다.
2) numpy array는 선언 당시 크기를 정하고 변경할 수 없습니다. 원소의 update는 가능하나 array의 크기를 변경하는 것은 불가능합니다.
append를 사용할 수 있으나 list처럼 크기를 변경하는 것이 아닌 사이즈가 변경된 array를 하나 더 만들고 복사해 오는 방식입니다.
3) 사실 numpy는 c와 c++로 구현되어 있습니다. 이는 파이썬이 numerical computing에 취약하기 때문이며 부족한 속도를 보안하기 위함입니다.
4) numpy는 datatype을 변경할 필요가 없기 때문에 python list보다 빠릅니다.
5) 또한 numpy는 후에 기술할 Universial function을 제공하기 때문에 반복연산면에서 데이터가 클수록 파이썬과의 속도차이가 커진다.
3. Numpy 사용법
3.1 선언과 array생성
import numpy as np
- numpy를 import한 후 np라는 이름으로 사용합니다.
data = [1, 2, 3, 4, 5] # 파이썬 리스트 생성입니다.
print(type(data)) # 타입 확인을 해 보아도 list 입니다.
arr1 = np.array(data) # 파이썬 list를 array로 변환 하는 것 입니다.
print(type(arr1)) # 타입 체크를 해보면 numpy.ndarray, n-dimensional array인 것을 확인 할 수 있습니다.
# 이 외 에도 아래와 같은 방식으로도 array를 생성 할 수 있습니다.
# arr1 = np.array([1, 2, 3, 4, 5]) # Sucessed
# arr1 = np.array(1, 2, 3, 4, 5) # failed
# arr1 = np.array((1, 2, 3, 4, 5)) # Sucessed
# array메소드 안에는 리스트, 튜플과 같은 연속형 자료형이 들어가야 합니다.
arr1.shape # array의 크기를 알려줍니다.
# 5 X 1, (5, )
- 2차원 array를 생성해 보겠습니다.
data2 = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
arr2 = np.array(data2) # 2차원 array생성
print(type(arr2)) # 마찬가지로 ndarray입니다.
3.2 np.array의 메소드들
# arr2의 차원
print("arr2의 차원(ndimenstion) : ", arr2.ndim ) #2차원어레이
# arr2의 행, 열의 크기
print("arr2의 행과 열(shape) : ", arr2.shape) # 3 by 3
# arr2의 행 x 열
print("arr2의 사이즈(size) : ", arr2.size) #행 X 열
# arr2의 원소의 타입. # int64 : integer + 64bits
print("arr2의 데이터타입(dtype) : ", arr2.dtype) #int32 : integer +32bits
# arr2의 원소의 사이즈(bytes) # 64bits = 8B
print("arr2의 아이템사이즈(itemsize) : ", arr2.itemsize) #4bites = 32bits
# itemsize * size # numpy array가 차지하는 메모리 공간.
print("arr2의 nbytes : ", arr2.nbytes)
3.3 Array Initialization
-
numpy array를 초기값과 함께 생성하는 방법도 있습니다.
-
원소가 0인 array를 생성하는 np.zeros()
-
원소가 1인 array를 생성하는 np.ones()
-
특정 범위의 원소를 가지는 np.arange()
# 0이 5개 있는 array
np.zeros(5)
# 0이 3x3인 array
np.zeros((3, 3)) #list혹은 튜플로 집어넣어야 합니다. np.zeros(3, 3)은 error가 납니다.
# 0부터 9까지 숫자를 자동으로 생성한 array
np.arange(10)
4. Array 계산 - Vector operation
-
numpy.array를 쓰는 가장 큰 이유는 vector 계산이 가능하기 때문입니다.
-
특히 데이터 분석 분야에서는 거의 대부분의 데이터를 벡터로 표현하여 분석하기 때문에 매우 중요합니다.
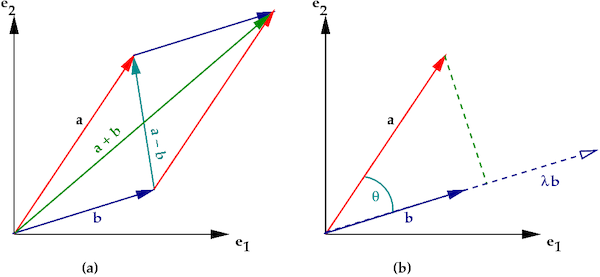
- 두 벡터 A = (1, 2), B = (2, 1) 이라고 할 때 두 벡터의 연산은 다음과 같이 정의됩니다.
A + B = (1 + 2, 2 + 1) = (3, 3)
A - B = (1 - 2, 2 - 1) = (-1, 1)
A · B = 1 X 2 + 2 X 1 = 4 # dot product
- 실제로 numpy.array를 생성하여 벡터 계산을 해보고 파이썬 리스트 연산과 무엇이 다른지 확인해 봅시다.
L1 = [1, 2, 3]
L2 = [4, 5, 6]
print(L1 + L2) # [1, 2, 3, 4, 5, 6]
arr1 = np.array(L1)
arr2 = np.array(L2)
print(arr1 + arr2) # [5, 7, 9]
- 다음 연산은 vector연산과는 조금 다른 elementwise 연산입니다. 주의 해야 할 점은 vector 곱셈과 나눗셈과는 다른 연산이라는 것 입니다.
#elementwise multiplication
print(arr1 * arr2)
#elementwise division
print(arr1 / arr2)
#-----------------------------
#dot product
print(arr1 @ arr2) # 이 연산은 vector의 dot product(점곱)을 계산하는 방법이며 vector 연산이 맞습니다.
5. Array계산 - Broadcast
-
Broadcast는 서로 size가 다른 두 vector를 연산시 자동으로 분배(broadcast)해주는 기능입니다.
-
선형대수(Linear algebra)에서의 행렬계산과 동일한 연산을 하기 위한 기능입니다.
arr1 = np.array([1, 2, 3],
[4, 5, 6]) # 2 X 3 array 생성
arr2 = np.array([7, 8, 9]) # 3 X 1 array 생성
print(arr1 + arr2) # [1, 2, 3] + [7, 8, 9] // [4, 5, 6] + [7, 8, 9]
# 큰 array에 작은 array를 뿌리는 느낌입니다.
print(arr1 * arr2) # [1, 2, 3] · [7, 8, 9] // [4, 5, 6] · [7, 8, 9]
# 행렬의 곱셈과 무척 유사합니다
# [1, 2, 3] X [7]
# [4, 5, 6] [8]
# [9]
6. Array계산 - Universal functions
- Universal functions는 하나의 함수를 모든 원소에 자동으로 적용해주는 기능입니다.
- 이 기능 덕분에 하나의 연산을 모든 원소에 적용하는 작업에 대해 엄청나게 빠른 속도를 제공합니다.
# [1, 2, 3]이라는 list와 array를 생성합니다.
L = [1, 2, 3]
arr1 = np.array(L)
# 모든 원소에 + 1을 하는 연산을 하기 위해선 python list의 경우 다음과 같은 과정이 필요합니다.
for index in range(len(L)):
L[index] += 1
# numpy array같은 경우 다음과 같은 과정이 필요합니다. 훨씬 간단할 뿐만 속도도 빠릅니다.
arr1 + 1
7. Indexing
- numpy array의 indexing같은 경우 python list와 상당히 비슷하지만 훨씬 강력한 기능을 제공하고 있습니다.
arr = ([1, 2, 3],
[4, 5, 6],
[7, 8, 9])
print(arr[1, 2]) # 기존 python list 의 경우 arr[1][2]
# 7
print(arr[:, 2]) # : 는 전체라는 의미입니다. 즉 3번째 row를 전부 출력합니다.
# [7, 8, 9]
8. Masking
- masking은 조건에 맞는 경우 True 맞지 않는 경우 False를 출력합니다.
- 위의 indexing과 결합할 경우 원하는 조건에 맞는 원소를 탐색해주는 매우 강력한 기능을 제공합니다.
data = np.random.randn(7, 4) # -1 부터 1까지 random한 값을 갖는 7 X 4 array를 생성합니다.
print(data)
masked_data = data > 0 # random으로 생성된 data의 원소중 양수인 원소에만 True를 생성합니다.
print(masked_data)
print(data[masked_data]) # 전체 data 원소 중 masked_data가 True인 원소만을 출력합니다. 이런식으로 index부분에 expression을 집어 넣는 것을 fancy indexing이라고 합니다.
print(data[:, 0] < 0) # 첫번째 row 에서 0보다 작은 원소는 True를, 0보다 큰 원소는 False를 출력합니다.
print(data[data[:, 0] < 0, 1]) # 첫번째 row 에서 True가 나온 column을 기억해 두번째 row 에서의 그 column값을 출력합니다.
마치며
numpy의 기능은 여러가지 method를 포함하여 여러가지가 있지만 이번 포스팅에서는 대략적인 사용법만 알아보았습니다. numpy는 데이터 분석에서 매우 중요한 라이브러리 입니다. 다음 포스팅에서는 numpy처럼 데이터 분석에 매우 중요한 두번째 라이브러리, pandas에 대해 알아보려고 합니다.