
Deep Learning - NLP__GPT-3
1. Text-to-Text Framework
GPT-3를 알아보기 이전에 Text-to-Text framework에 대해 알아보도록 합시다.
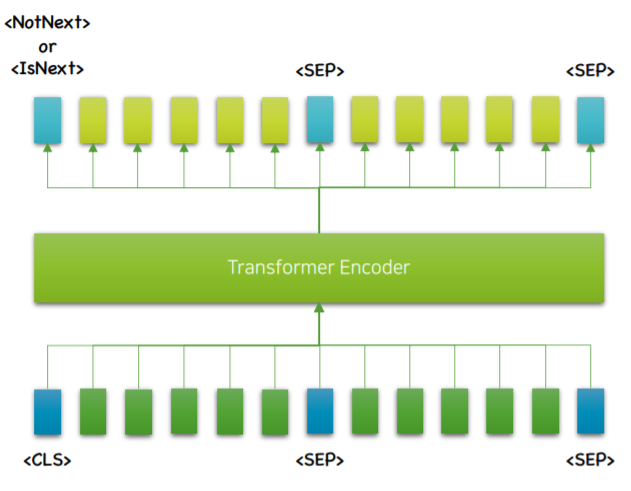
기존의 NLU task는 Encoder를 거친 후 Linear Layer 와 Softmax를 추가하여 fine tuning하고 있습니다.
하지만 이러한 과정에서 새로운 Layer가 추가됨으로 인해 over-confident문제 등이 발생함으로 인해 성능이 저하되는 이슈가 있습니다.
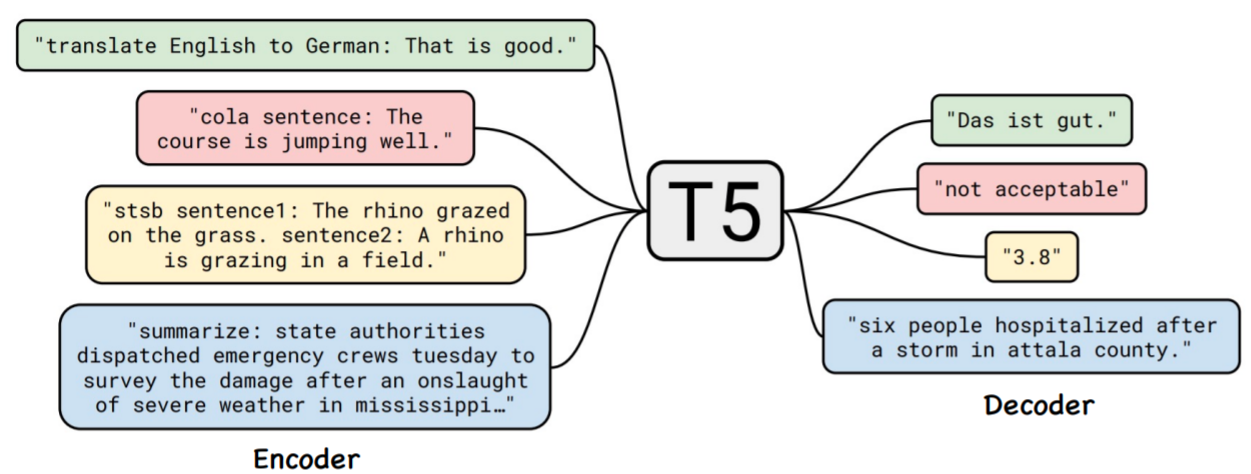
이에 Google에서는 T5라는 새로운 fine tuning방식을 제시하였습니다.
이는 BART와 같은 Enc-Dec방식이며 NLU를 포함한 모든 task를 NLG로 처리합니다.
위 사진에서 빨간색 문제와 노란색 문제는 기존 방식을 따르자면 NLU task이지만 T5는 이를 자연어 생성(NLG) task로 해결하고 있습니다.
2. GPT-3
대부분의 PLMs는 사전학습 후 fine tuning을 통해 학습을 진행합니다. 하지만 이러한 fine tuning은 over-fitting의 원인이 되기도 하며 또한 실제 성능보다 벤치마크 점수가 과도하게 나타날 수도 있습니다.
그리고 fine tuning이 존재함으로서 각 downstream task마다 fine tuned된 모델이 존재하게 됩니다.
그렇기에 GPT-3는 이러한 Fine tuning없이 사전학습만으로 동작합니다.
설명하기에 앞서 GPT-3 또한 T2T framework을 따릅니다.
2.1 In-Context learning
GPT-3는 사실 이전 포스팅에서 다뤘던 GPT와 동일한 구조를 가지고 있습니다.
다만 다른점은 사전학습을 초 대용량으로 하였다는 점 입니다.
즉 대용량 LM은 파라미터 업데이트 없이 Few-shot 학습 만으로 다양한 task를 수행 할 수 있다는 것이 GPT-3의 핵심입니다.
그렇다면 어떻게 GPT-3는 대용량 LM이 가능하였냐면 바로 In-Context learning을 하였기 때문 입니다.
In-Context learning은 파라미터의 업데이트 없이, feed-forward만을 사용해 학습이 이루어집니다. 즉 back-propagation이 발생하지 않습니다.
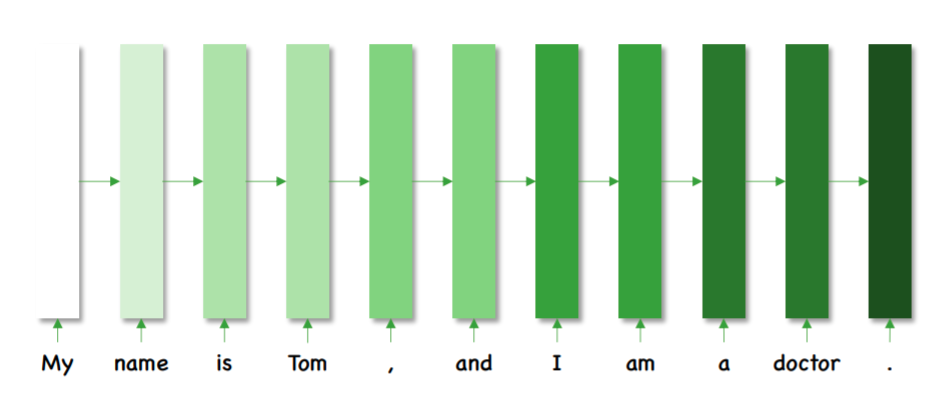
비록 parameter의 업데이트는 일어나지 않지만 대용량으로 축적된 time-step을 진행함으로서 그동안의 정보가 담겨있게 됩니다.
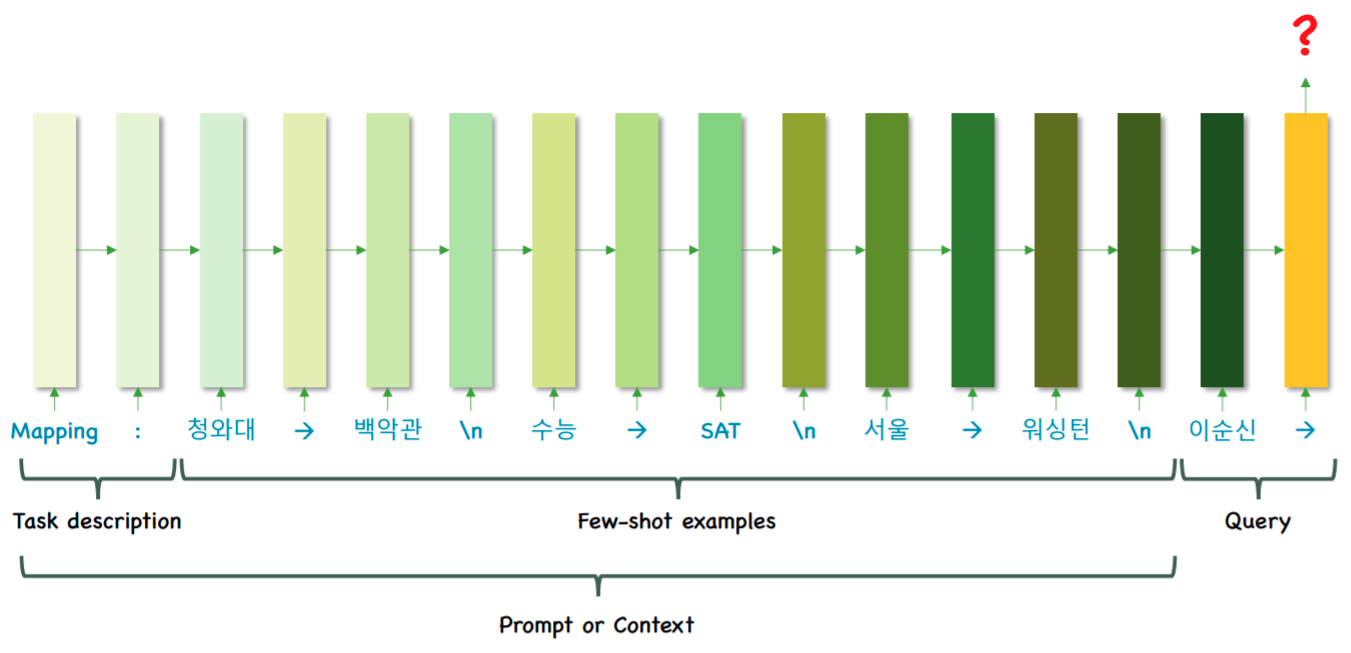
이러한 In-Context learning을 바탕으로 Few-shot 학습을 통해 원하는 task를 해결하는 구조 입니다.
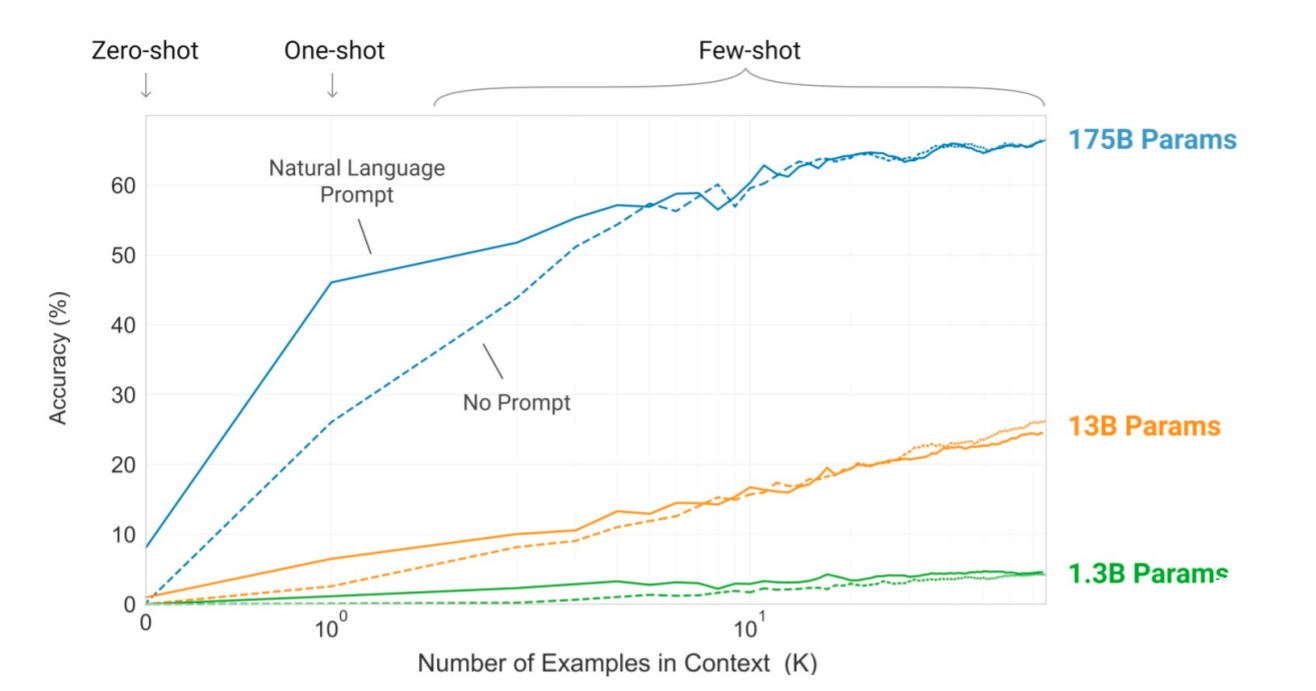
In-context learning은 데이터의 크기가 커질수록 효율이 향상됩니다.
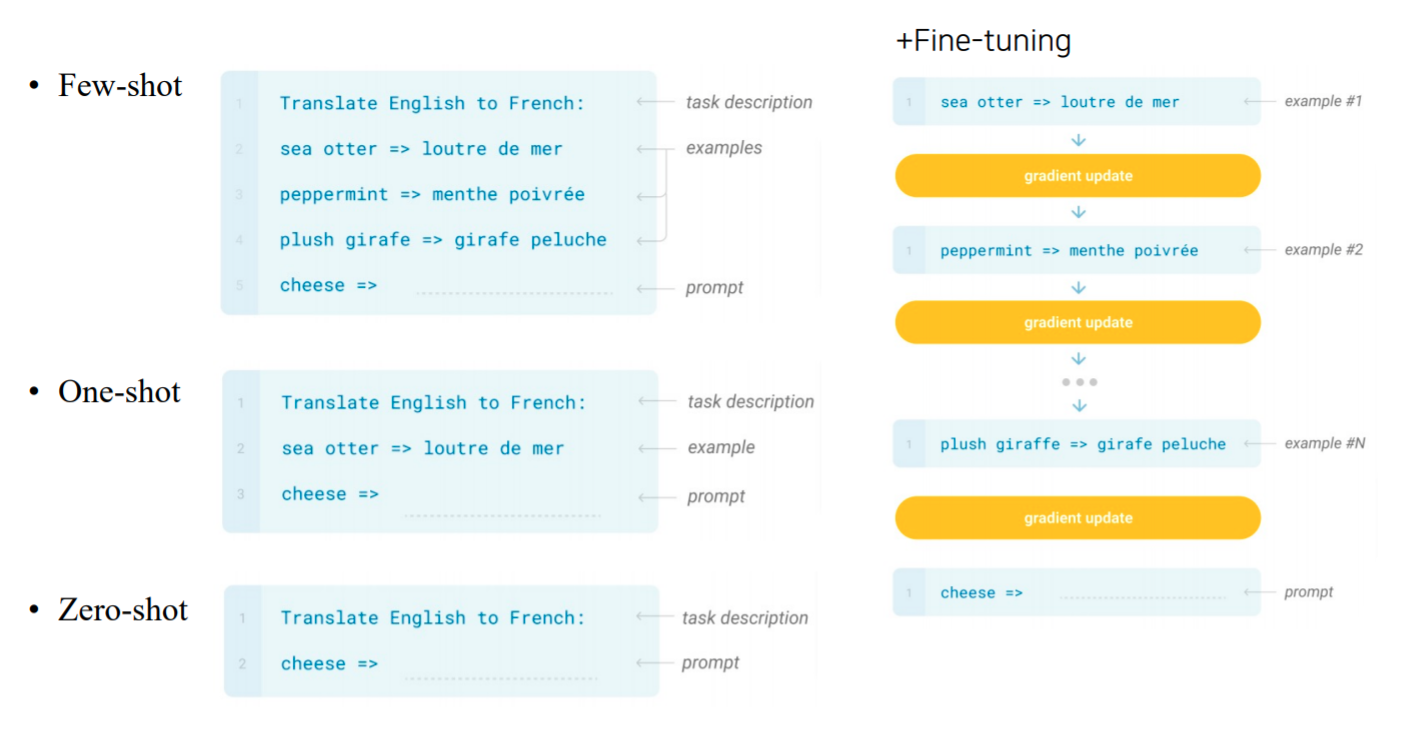
위는 fine-tuning과 Few-shot의 차이를 나타낸 것 입니다. zero-shot, one-shot은 example을 전혀, 한개만 진행한 것이며 few-shot은 example로 소수의 몇개만 주는 방식입니다.
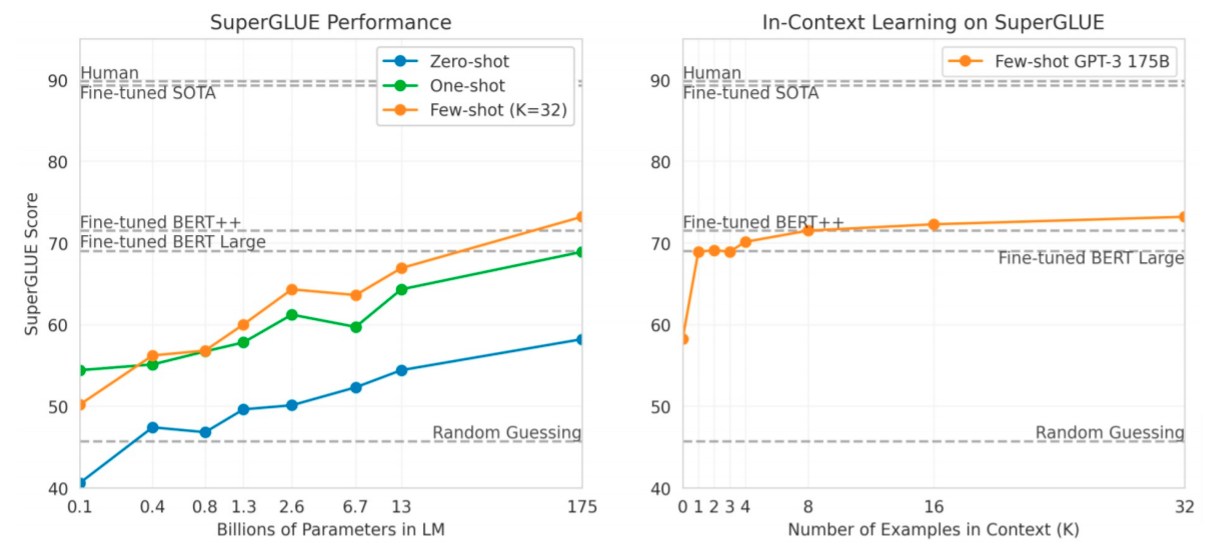
In-context learning은 이렇게 다른모델의 fine-tuning과 비교해 보아도 준수한 성능을 보여줍니다.
2.2 한계
-
Bi-directional이 필요한 task에 비해서 성능이 떨어집니다.
빈칸채우기, 요약하기 등의 task에서는 기존 모델에 비해 성능이 조금 떨어집니다. -
Hallucination 생성된 자연어가 Few-shot과 비슷한 형식을 하고 있으나 알맹이가 없습니다.
예를들어 뉴스기사를 생성하였을 경우 분명 뉴스기사처럼 보이는 글을 생성하지만 그 내용은 엉터리인 경우를 말합니다. -
단어의 개념을 이해하는가 Hallucination과 비슷합니다. 학습이 과연 단어의 개념을 이해하였는지 의심됩니다.
예를들어 “If I put cheese in the fridge, will it melt?”라는 물음에 녹는다 라고 대답하곤 합니다.
마치며
GPT-3는 In-context learning을 활용하여 새로운 시도를 한 모델입니다. 파라미터 크기를 극대화 하여 fine-tuning없이 학습이 가능하도록 만들었으며 downsteam task에 따라 모델을 따로 만들지 않아도 하나의 모델로 모든 task를 처리 할수 있는 새로운 PLMs 패러다임을 제시하였습니다.
하지만 현재는 한계가 있으며 모델을 생성하기 위한 비용이 너무 많이 나가는 등 현실적인 대안이 아닐 수도 있습니다.