
Deep Learning - NLP__HuggingFace Transformers
시작하기 앞서
이번 포스팅에서는 BERT를 이용해 Text Classification, 즉 감정분석 코드를 작성하고 리뷰하는 형식으로 설명하겠습니다.
코드는 kh-kim님의 simple-ntc를 활용하겠습니다.
repo안에는 다양한 파일이 존재하지만 이번 포스팅에서는 다음과 같은 파일만 사용하도록 하겠습니다.

1. HuggingFace Transformers란
-
HuggingFace Transformers란 Transformers의 NLG, NLU 를 위한 General-purpose 아키텍처를 제공합니다.
BERT, RoBERT, GPT등을 말하며 PyTorch 및 TensorFlow에서 모두 동작합니다. -
Model hub를 제공합니다.
사용자 끼리 모델을 공유하고 통일된 플랫폼 위에서 작업할 수 있게 해줍니다.
사전학습된 모델을 단순히 아이디 하나로 자동 다운로드 및 학습이 가능합니다. -
뿐만아니라 전처리, 학습, 벤치마크 테스트 코드까지 모두 제공합니다.
때문에 전체 pipeline이 쉽게 통합 될 수 있습니다. -
또한 Documentation이 무척 잘되어있어 쉽게 코드에 대한 설명을 볼 수 있습니다.
2. bert_dataset.py
PyTorch를 이용하여 Downstream task를 하기 위해서는 가장 먼저 DataSet 과 DataLoader가 필요합니다.
DataSet에서 Data를 정의하고, Data의 길이, 크기를 알며, 미니배치를 위한 샘플반환 역할을 수행합니다.
DataLoader는 설정된 미니배치만큼 데이터를 불러오는 역할을 합니다.
2.1 TextClassificationDataset()
PyTorch로 custom dataset을 구성하기 위해서는 dataset class를 생성하고 이 class는 총 3개의 메소드가 필요합니다.
-
__init__
데이터를 정의하는 메소드입니다. class를 선언할 때 text와 label을 parameter로 받습니다.
미니배치를 설정하지 않은 전체 dataset을 구성하는 메소드 입니다. -
__len__ 데이터의 크기를 정의하는 메소드입니다. 실제로 text의 길이를 측정하여 return합니다. DataLoader로 데이터를 불러오기 위해 필요한 메소드 입니다.
-
__getittem__ 주어진 index의 data를 불러오는 메소드입니다. DataLoader가 미니배치를 생성하여 데이터를 불러오는데 활용되는 메소드 입니다.
2.2 TextClassificationCollator()
NLP는 자연어를 다루기 때문에 각 문장마다 길이가 전부 다릅니다.
하지만 이를 학습에 응용하고자 하면 문장의 길이가 전부 다르기 때문에 Tensor의 크기도 전부 다르게 됩니다.
이를 해결하기 위해 collate_fn을 정의합니다.
TextClassificationCollator() 클래스는 DataLoader의 collate_fn으로 사용될 것 이며 미니배치 내의 문장을 리스트 형식으로 받아 가장 긴 문장을 기준으로 padding을 생성하는 역할을 수행합니다.
-
__init__ tokenizer, max_length와 with_text를 입력받아 클래스 내의 변수로 지정합니다. 사용된 tokenizer와 dataset내의 문장에서 max_length를 입력받아 넣어주면 됩니다.
-
__cal__ 본격적으로 collate_fn으로 작용하는 메소드 입니다. samples라는 이름으로 받아들인 문장과 lables를 리스트로 저장하고 tokenizer의 padding기능을 이용하여 return_value라는 dictionary를 생성합니다. return_value는 기본적으로 tokenizer가 생성한 token의 index, attention mask, label을 저장합니다. with_text가 True일 경우 본문의 text또한 이 dictionary에 저장합니다.
2.3 실제 적용
위의 class들은 실제 finetune_plm_hftrainer.py에서 다음과 같이 사용되었습니다.
train_dataset = TextClassificationDataset(texts[:idx], labels[:idx])
valid_dataset = TextClassificationDataset(texts[idx:], labels[idx:])
# --------------------------------------------------------------------------
trainer = Trainer(
model=model,
args=training_args,
data_collator=TextClassificationCollator(tokenizer,
config.max_length,
with_text=False),
train_dataset=train_dataset,
eval_dataset=valid_dataset,
compute_metrics=compute_metrics,
)
3. Tokenizor
HuggingFace를 사용한다면 사람들이 공유해둔 Tokenizor를 간단히 학습에 이용할 수 있습니다.
아래는 실제 finetune_plm_hftrainer.py에서 사용된 부분을 추출한 것 입니다.
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained(config.pretrained_model_name)
config는 아래 함수에서 정의되어 있습니다.
이와 같이 HuggingFace는 Pre-trained된 언어모델을 간단하게 코드 3줄로 작성할 수 있습니다.
4. finetune_plm_hftrainer.py
이번 학습의 main을 담당하는 파일입니다. 실제로 main() 함수에서 모든 진행상황을 다루고 있습니다.
library import 부분부터 차근차근 뜯어 보도록 하겠습니다.
4.1 Library
import argparse
import random
argument를 입력받고 random 하게 섞어주는 기능을 사용하게 해주는 모듈입니다.
from sklearn.metrics import accuracy_score
accuracy_score를 계산하기 위한 모듈입니다. Classification문제를 올바르게 예측한 갯수를 전체 갯수로 나누어준 값을 return합니다.
from transformers import BertTokenizerFast
from transformers import BertForSequenceClassification, AlbertForSequenceClassification
from transformers import Trainer
from transformers import TrainingArguments
HuggingFace의 transformers 모듈입니다. BertTokenizerFast는 pre-trained된 tokenizer를 불러오는데 사용되며 BertForSequenceClassification, AlbertForSequenceClassification는 pre-trained된 BERT 혹은 ALBERT모델을 불러오는데 사용됩니다.
ALBERT는 BERT의 light 버전입니다.
Trainer는 train을 시키기 위한 모듈이며 TrainingArguments는 Trainer에 arg인자로 들어가며 학습의 세부 설정을 담당합니다.
from simple_ntc.bert_dataset import TextClassificationCollator
from simple_ntc.bert_dataset import TextClassificationDataset
from simple_ntc.utils import read_text
위 세가지 모듈은 repo안에 포함되어 있으며 위에서 설명 하였으니 넘어가겠습니다. utils의 read_text는 말그대로 원본 데이터, 즉 text를 읽어오는 함수입니다.
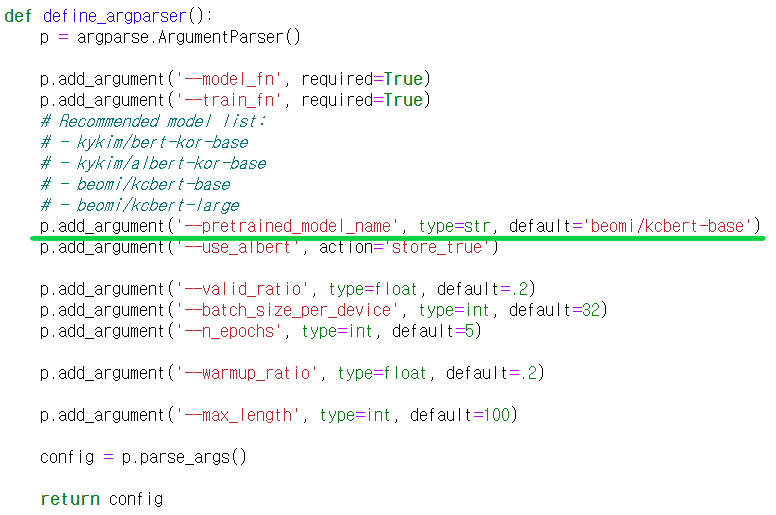
4.2 define_argparser()
CUI환경에서 실행시킬때 실행과 동시에 인자를 입력받는 함수입니다. config안에 argument가 전부 저장되며 config.pretrained_model_name과 같이 사용됩니다.
model_fn은 학습을 완료하고 모델을 저장하는 경로를 입력해주어야 하며 train_fn은 학습을 위한 데이터, tsv파일 경로를 입력해주면 됩니다.
4.3 get_dataset()
학습을 위한 데이터를 저장해둔 tsv파일 경로를 입력받아 train_dataset, valid_dataset, index_to_label을 출력 하는 함수입니다.
내부 과정으로는 먼저 index를 label로 반환하는 dictionary와 label을 index로 반환하는 dictionary를 생성합니다.
후에 train, val set을 나누기 전에 랜덤하게 셔플한 후 valid ratio만큼 분리합니다. valid ratio는 입력값으로 default가 0.2 입니다.
4.4 main()
main함수 입니다. 특별한 return값은 없지만 함수가 진행되는 동안 학습을 진행하고 학습이 완료되면 완료된 모델을 저장합니다.
# Get pretrained tokenizer.
tokenizer = BertTokenizerFast.from_pretrained(config.pretrained_model_name)
# Get datasets and index to label map.
train_dataset, valid_dataset, index_to_label = get_datasets(
config.train_fn,
valid_ratio=config.valid_ratio
)
tokenizer와 dataset을 생성하는 부분입니다. tokenizer는 HuggingFace의 기능을 사용해 한줄만에 구현하였으며 dataset을 만드는 부분은 위에서 만든 get_datasets함수를 사용하였습니다.
total_batch_size = config.batch_size_per_device * torch.cuda.device_count()
n_total_iterations = int(len(train_dataset) / total_batch_size * config.n_epochs)
n_warmup_steps = int(n_total_iterations * config.warmup_ratio)
print(
'#total_iters =', n_total_iterations,
'#warmup_iters =', n_warmup_steps,
)
total iterations와 warmup iteration을 설정하는 부분입니다. 특별한 입력이 없다면 epochs는 5, warmup_ratio는 0.2로 설정되어 있습니다.
# Get pretrained model with specified softmax layer.
model_loader = AlbertForSequenceClassification if config.use_albert else BertForSequenceClassification
model = model_loader.from_pretrained(
config.pretrained_model_name,
num_labels=len(index_to_label)
)
model을 설정하는 부분입니다. 마찬가지로 HuggingFace의 기능을 사용하여 모델 아이디를 넣고 간단하게 구현하였습니다.
training_args = TrainingArguments(
output_dir='./.checkpoints',
num_train_epochs=config.n_epochs,
per_device_train_batch_size=config.batch_size_per_device,
per_device_eval_batch_size=config.batch_size_per_device,
warmup_steps=n_warmup_steps,
weight_decay=0.01,
fp16=True,
evaluation_strategy='epoch',
logging_steps=n_total_iterations // 100,
save_steps=n_total_iterations // config.n_epochs,
load_best_model_at_end=True,
)
HuggingFace의 Trainer를 사용할 예정이기 때문에 마찬가지로 HuggingFace의 TrainingArguments 함수를 이용하여 argument를 작성하는 부분입니다.
경로, epochs, device당 batch size, .. 등등 train의 상세 사항을 조정 할 수 있습니다.
trainer = Trainer(
model=model,
args=training_args,
data_collator=TextClassificationCollator(tokenizer,
config.max_length,
with_text=False),
train_dataset=train_dataset,
eval_dataset=valid_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Fine tuning을 하는 부분입니다. HuggingFace에서 제공하는 Trainer 클래스를 사용하였으며 지금까지 작성한 함수들을 사용해 인자를 채워주고 .train 메소드를 이용해 fine tuning을 실행합니다.
torch.save({
'rnn': None,
'cnn': None,
'bert': trainer.model.state_dict(),
'config': config,
'vocab': None,
'classes': index_to_label,
'tokenizer': tokenizer,
}, config.model_fn)
마지막으로 모델을 저장해줍니다. rnn, cnn은 repo내의 다른 함수들과 호화성 때문에 작성한 것이며 bert라는 key안에 모델이 저장될 것 입니다.
마치며
지금까지 kh_kim님의 simple-ntc코드를 보며 HuggingFace기능을 이용한 Text Classification 학습을 알아보았습니다. PLMs를 이용하였기 때문에 tokenizor와 모델의 초기 상태를 정해 줄 수 있었으며 HuggingFace를 사용하였기 때문에 사전학습된 정보를 가져오고 학습까지 통일된 플랫폼으로 손쉽게 작성할 수 있었습니다. 이번 포스팅에서 설명하지 않았지만 사용된다고 굵게 표시된 파일들은 HuggingFace를 사용하지 않고 Pytorch ignite를 이용하여 구현한 학습입니다. HuggingFace를 이용하지 않고 PLMs를 구현하는 것과 비교해 보고 싶다면 확인해 보시길 바랍니다.