
Deep Learning - NLP__Types of PLMs
1. Types of PLMs
PLMs에는 크게 3가지 유형의 모델이 존재합니다.
-
Autoregressive Model
-
AutoEncoder model
-
Encoder-Decoder model
지금부터 하나씩 알아보도록 하겠습니다.
2. Autoregressive Model
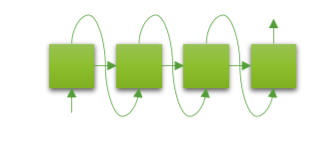
Transformer의 Decoder를 통해 Language model을 구현한 모델입니다.
순서대로 다음 단어를 찾기 때문에 NLG에 강한 성능을 보여줍니다.
대표적으로 Open AI에서 개발한 GPT가 있습니다.
2.1 GPT
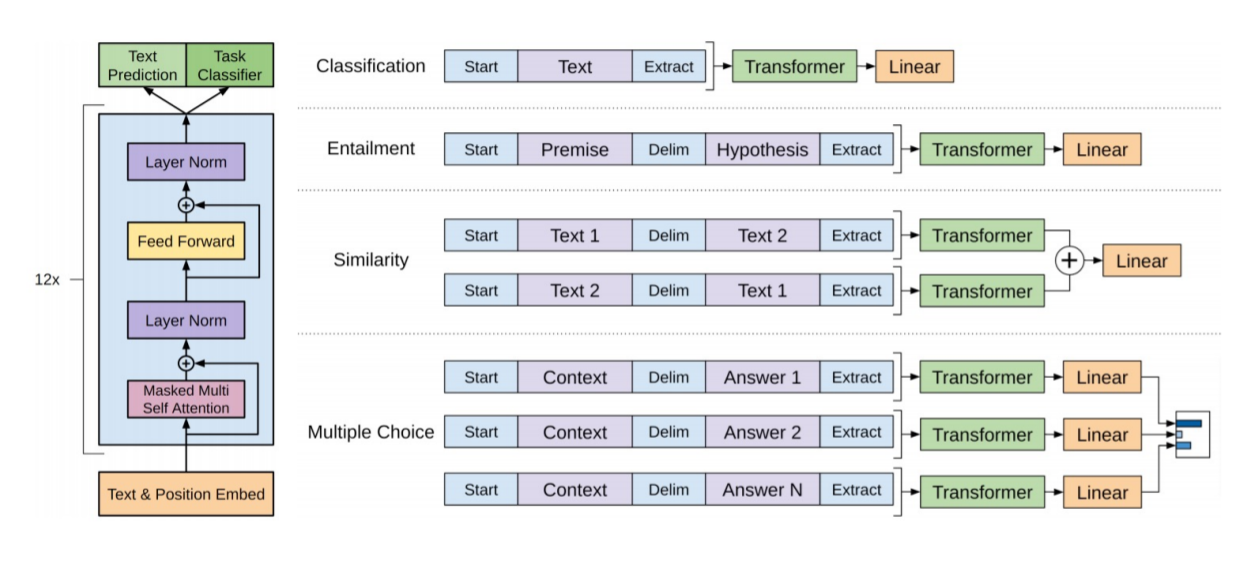
입력으로 Text와 특수토큰로 구성된 sequence를 받습니다. Masked self attention에서 Decoder와 같이 순서대로 다음 text를 예측하며 학습을 진행합니다.
출력으로 각각의 Downstream work에 맞는 구조를 통해 $\hat y$을 얻습니다.
GPT는 초기 PLMs으로서 지금도 계속 나오는 GPT시리즈의 토대가 됩니다. Decoder를 통해 Language model을 구현하고 Transfer를 활용하였을 때 단순한 지도학습보다 뛰어난 성능을 얻을 수 있습니다.
3. AutoEncoder Model
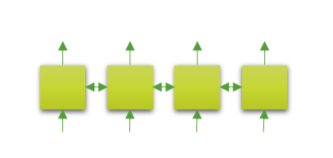
Transformer의 Encoder를 통해 구성되어 있습니다.
Autoregressive model과는 다르게 Bi-directional language model, 즉 text를 순서대로 읽는것이 아닌 양방향으로 읽어 학습 할 수 있습니다.
“말은 끝까지 들어봐야 안다.” 라는 말이 있듯이 언어는 뒤에 나오더라도 중요한 의미를 포함 하고 있을 수 있지만 순서대로 읽어들여 학습하는 기존의 Language model은 뒷 sequence가 학습이 덜 되게 되는 단점을 보완 할 수 있습니다.
때문에 이런 Bi-directionla language model을 구현하기 위하여 Masked Language model을 구현하였으며 NLU task에서 뛰어난 성능을 보여줍니다.
하지만 NLG task는 학습 할 수 없습니다.
대표적으로 google에서 개발한 BERT가 있습니다.
3.1 BERT
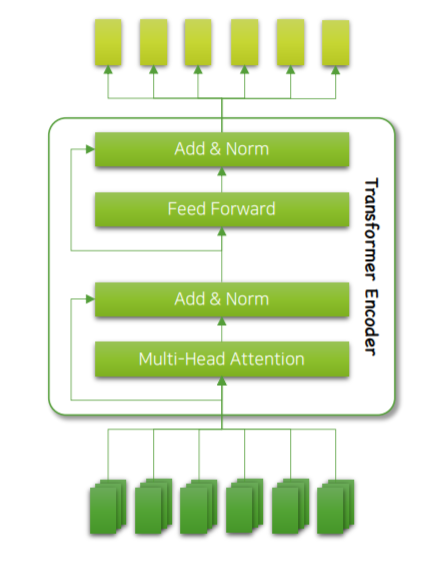
Masked Language model, Next Sentence Prediction을 통해 학습합니다.
또한 Positional 인코딩 대신 word, sentence, position등 다양한 Embedding을 결합하여 사용할 수 있습니다.
- Masked Language model
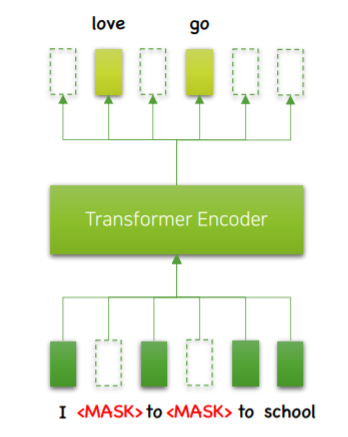
Bi-LM을 구현하기 위해 사용한 모델입니다. 일정 비율의 토큰을 MASK로 가린 뒤 문장을 복원하도록 학습시킵니다.
다음 time step을 예측하는 기존의 LM과 다르게 현재 time step에서 문장 전체 정보를 읽어들여 활용 할 수 있습니다.
- Next sentence prediction
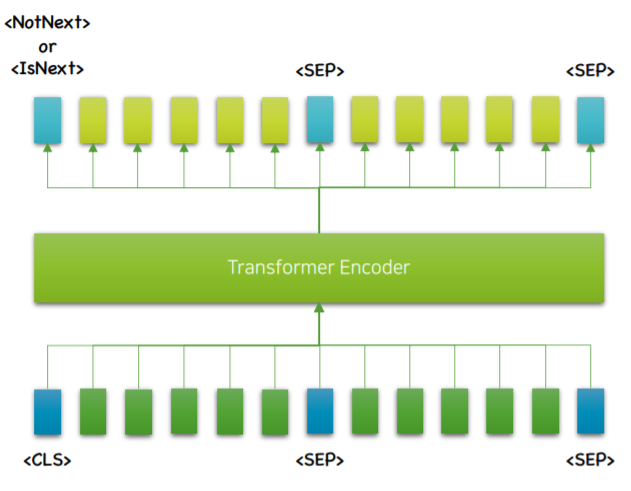
50%의 확률로 연속된 두 문장을 가져와 SEP으로 구분합니다. 이 후 두 문장이 연속된지 아닌지 학습하여 문장사이의 관계를 학습하는 방법 입니다.
CLS토큰으로 시작하며 학습이 완료 된 후 이 위치에 연속하는지, 연속하지 않는지를 표시하게 됩니다.
이러한 BERT는 가장 대중적인 PLMs이며 Bi-LM을 구현함으로서 NLU task의 성능을 대폭 향상시켰습니다.
3.2 RoBERTa
RoBERTa는 쉽게 말해 BERT의 강화판입니다. 원문 또한 Robustly Optimized BERT approch로 해석하면 제대로 최적화 시킨 BERT라는 의미를 가지고 있습니다.
기존 BERT와 다른점은 아래와 같습니다.
- BERT대비 10배의 데이터를 더 오래 학습
DL의 시대에 더 많은 데이터로 더 오래 학습시킨다는 것은 더 좋은 성능을 나타나게 해줍니다.
- NSP, Next Sentence Prediction을 제거
BERT가 공개되고 시간이 흘러 여러 실험을 통해 NSP가 불필요 하다는것을 깨달았습니다.
- 좀 더 긴 sequence에 맞춰 학습
기존의 BERT보다 좀 더 긴 sequence, 512에 맞춰 학습하였습니다.
- Masking 패턴을 feed-forward할 때마다 새롭게 구성하였습니다.
RoBERTa는 BERT이후 많은 PLMs가 제안되었지만 결국에 NLU task에서는 BERT가, 즉 RoBERT가 유용하다는 것을 제대로 입증한 모델입니다.
4. Encoder-Decoder model
지금까지 Transformer의 Decoder와 Encoder를 구현하는 모델을 알아보았습니다. 그렇다면 이 둘을 둘다 사용하는 모델또한 있을 것 입니다.
그 모델이 바로 Encoder-Decoder model이며 대표적으로는 Facebook에서 개발한 BART가 있습니다.
4.1 BART
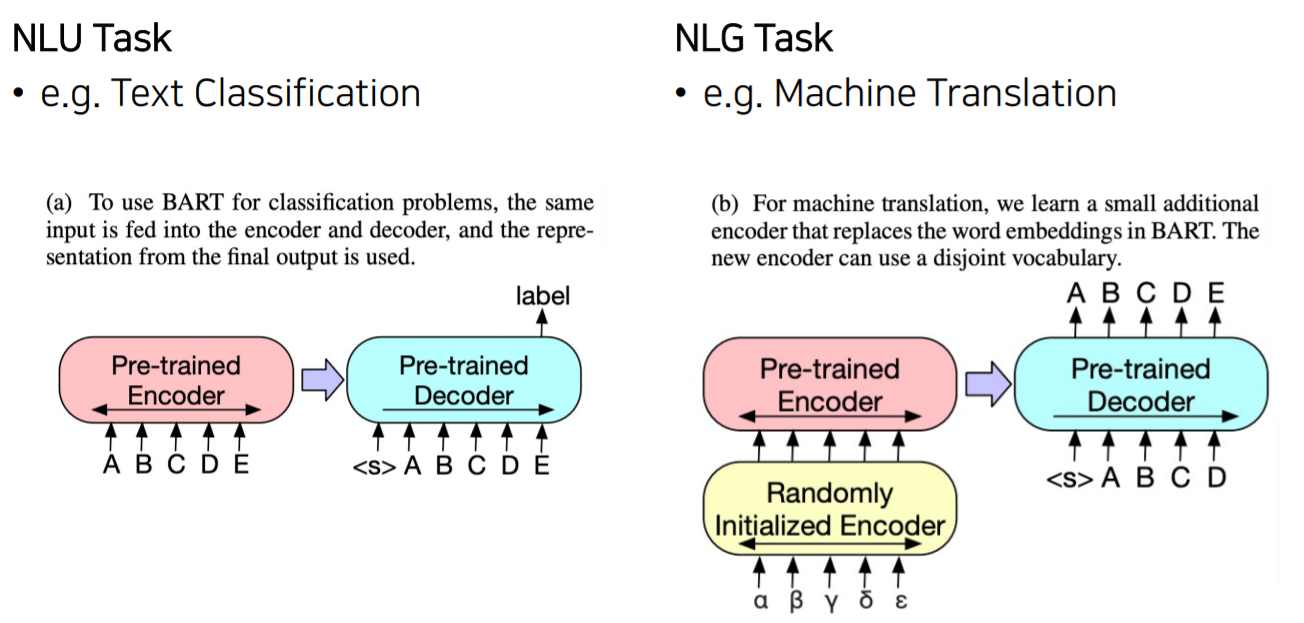
BART는 Encoder와 Decoder로 구성된 모델입니다.
Encoder로부터 정보를 받아 Decoder에서 Autoregressive하게 원문을 복원합니다.
둘 다 사용하기 때문에 Encoder에서는 Bi-LM을 사용가능하며 Enc-Dec구조상 입력과 출력의 길이가 달라도 되어 MASK이외에 여러가지 노이즈를 추가할 수 있습니다.
이렇게 Encoder-Decoder Model은 NLU,NLG 양쪽의 task 모두 해결 가능하며 다양한 노이즈를 주어 사전학습 효과가 증대되는 장점이 있습니다.
후속연구에서는 이 방식이 다른 모델에 비해 성능이 뛰어남을 확인되었습니다.
마치며
이번 포스팅에서는 다양한 타입의 PLMs에 대해 알아보았습니다. 이 타입에 따라 성능이나 resource 등 다양한 trade off가 있으며 각자 장단점이 존재합니다. 또한 PLMs의 발전은 앞으로 모델이나 수학적 이해보다는 더 많은 데이터를 어떻게 효율적으로 잘 학습시키는가와 같은 엔지니어링 능력을 좀 더 요구하고 있습니다.