
Deep Learning - NLP__Transformer
1. Transformer의 등장배경
NLP는 seq2seq의 등장으로 적지 않은 성능 향상을 이루었습니다. 하지만 RNN을 기반으로둔 seq2seq기법은 여러 한계점을 드러내기 시작하였습니다. 그렇게 RNN을 사용하지 않고 Attention을 사용한 Transformer가 등장하였습니다.
2. Attention
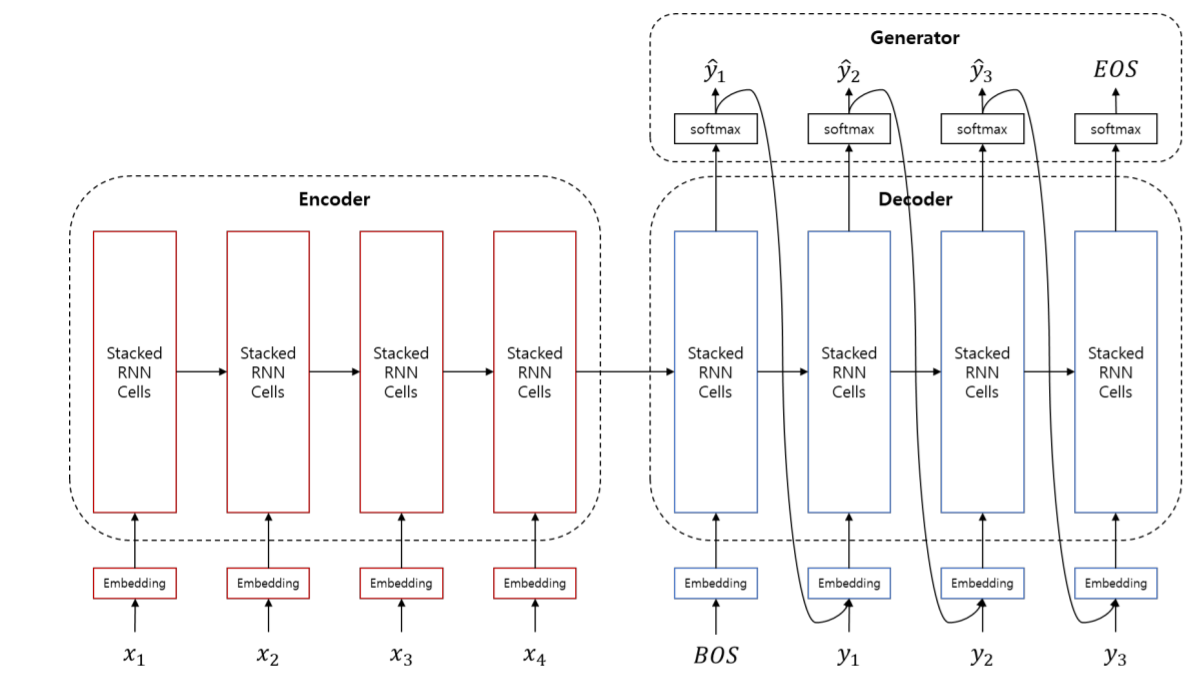
위 그림이 기존의 seq2seq를 활용한 Machine Translation 과정입니다. 하지만 아무리 LSTM을 이용하여도 sequence가 길어진다면 정보의 손실이 발생하게 되고 Encoder에서 Decoder로 넘겨줄 때 정보를 압축하면서 정보의 손실이 발생하게 됩니다.
그렇기 때문에 위 과정을 보정해 주기 위한 작업이 Attention입니다.
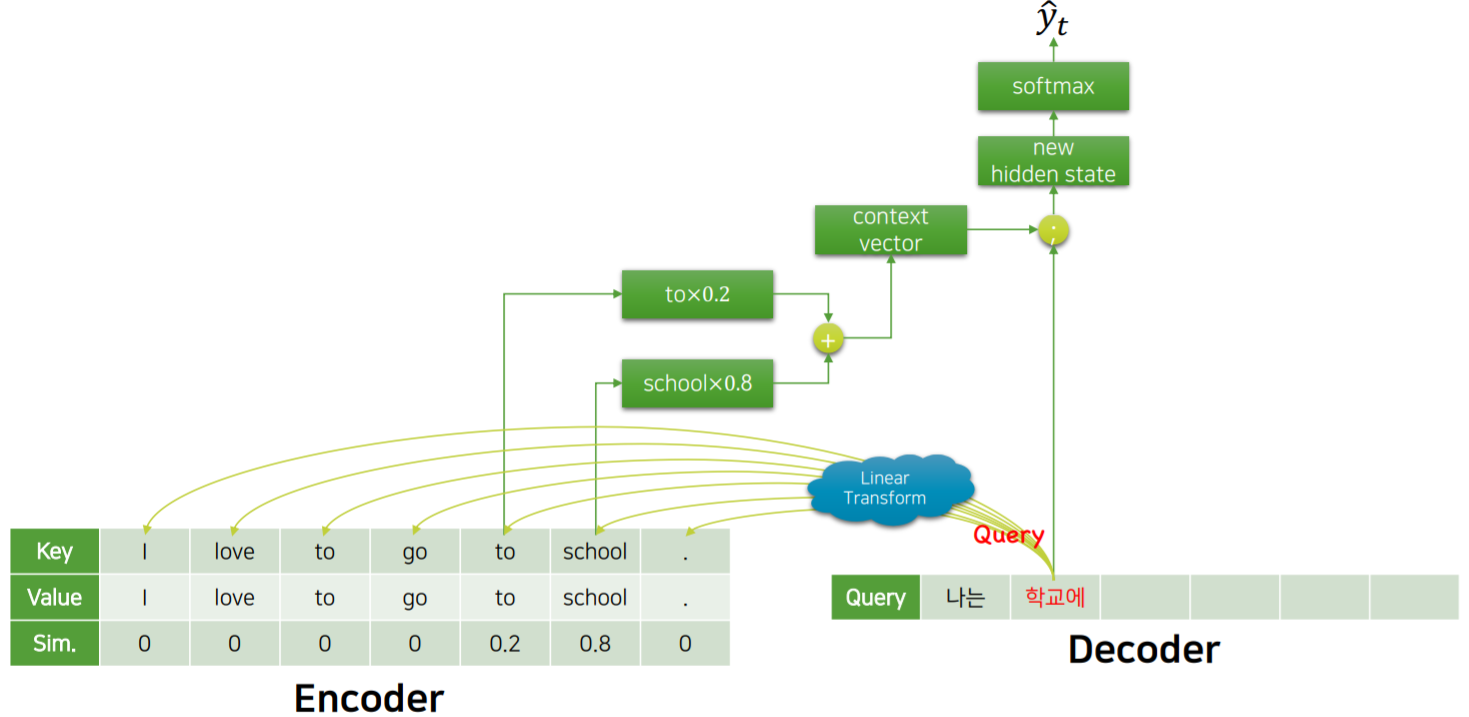
위 그림에서 Decoder는 ‘학교’라는 단어를 유추하였습니다. 이 ‘학교’라는 단어가 제대로 생성이 됬는지 확인하기 위해 Attention을 시행 할 것 입니다.
Attention은 총 3가지 parameter가 존재합니다. Key, Value, Query입니다.
이 때, ‘학교’가 Query가 됩니다.
Key는 Encoder에 집어넣는 원문들이 될 것 입니다. 현재 ‘I’, ‘love’, ‘go’ ,… 등 을 표현하는 Embedding vector가 Key가 될 것 이며, 이와 연결된 값, 즉 ‘I’, ‘love’, ‘go’, … 자체가 Value가 됩니다.
2.1 Process
Attention의 진행과정은 다음과 같습니다.
Query를 linear transform하여 Key와 같은 형식으로 맞추어 줍니다. 예를 들자면 영어를 한국어로 번역하는 Machine Translate 경우 한국어일 Query를 영어인 Key로 표현해 주는 것 입니다.
이렇게 변형된 Query를 Key와 유사도를 계산합니다. 이 유사도는 attention score라 불리며 유사도에 따라 weight를 두어 weighted sum, 즉 합을 계산한 후 기존의 hidden state의 weight에 concatnation을 해줍니다.
그 후 softmax를 통과하여 기존의 label과 비교하는 과정을 통해 정밀도를 검사하는 방식입니다.
2.2 masking

사실 Key-Value에는 모두 필요한 정보만 가지고 있지 않으며 유사도 또한 0으로 계산되지 않습니다. Batch내의 문장의 길이가 다르기 때문에 나머지 문장에 PAD가 생기게 되는데 이 PAD에도 유사도가 생기기 마련입니다.
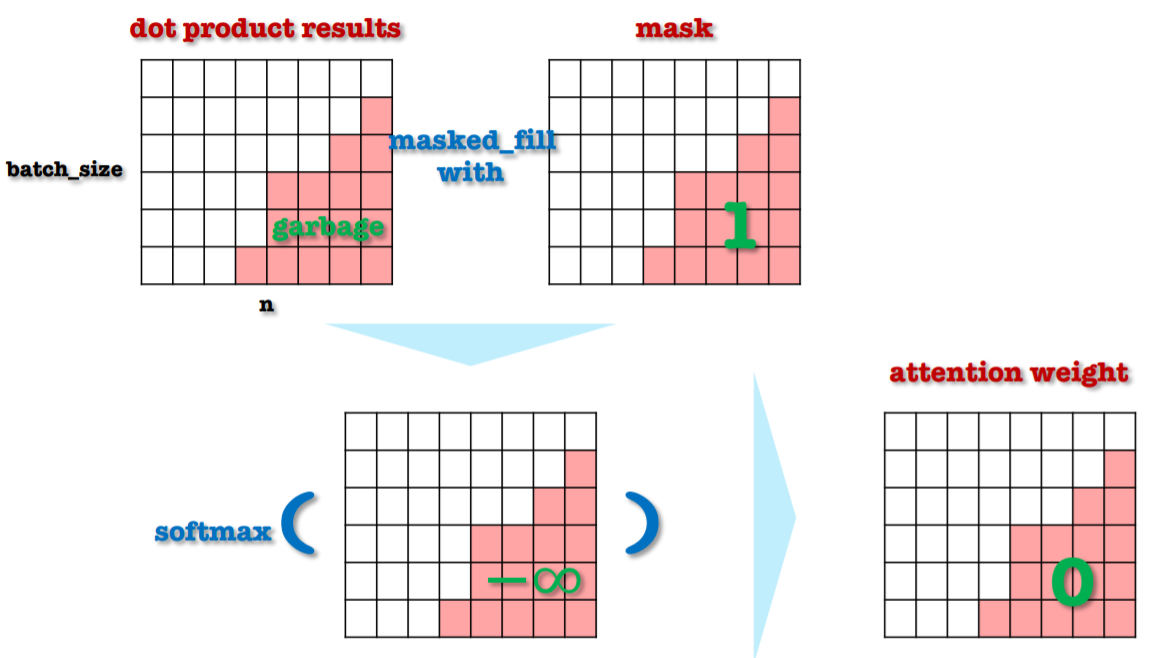
그렇기 때문에 위 와 같이 softmax를 하기 전에 masking을 해주며 결과적으로 weight가 0이 되게 만들어 줍니다.
2.3 정리
Attention은 미분가능한 Key-value function입니다. 이 때 함수의 입력은 Key, Value, Query가 됩니다.
Attention은 정보를 잘 얻기 위한 Query를 변환하는 것을 배우는 과정입니다.
Attention을 사용함으로서 Encoder에 들어가는 모든 sequence를 한 벡터에 압축해야 하는 한계를 극복하고 더 긴 길이의 입 출력에도 대응이 가능해 집니다.
3. Transformer
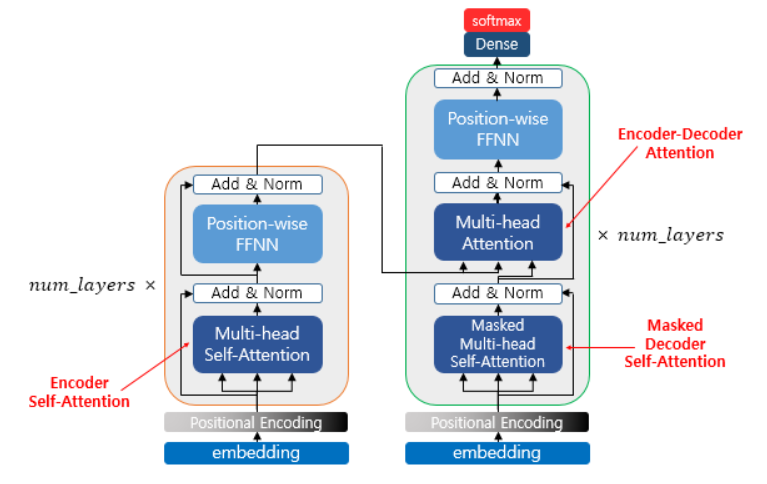
Transformer는 이제 RNN구조를 사용하지 않고 오로지 Attention만 사용하는 구조 입니다.
총 3가지 과정으로 이루어져 있으며 아래와 같습니다.
- Self-attention, Encoder
Self-attention은 Encoder에서 일어나는 과정입니다.
이 때, K,V,Q는 모두 인코더 벡터로 동일한 경우 입니다.
- Masked Self-attention, Decoder
Masked Self-attention은 Decoder에서 일어나는 과정입니다.
기본적으로 Encoder의 Self-attention과 동일하나 Attention은 문장 전체를 한번에 읽고 해석하기 때문에 미래의, 즉 나중에 나오는 단어가 영향을 끼치지 않도록 masking을 합니다.
- Attention from encoder, Decoder
Attention from encoder는 마찬가지로 Decoder에서 일어나는 과정이며 윗 단락에서 설명한 Attention과 동일한 과정입니다.
나머지 부분에 대해서 간략하게 설명하자면 positional encoding은 더이상 RNN을 사용하지 않기에 위치정보, 즉 순서에 따른 정보를 추가해 주기 위한 encoding작업입니다.
FFNN은 Feed Forward NN입니다. Add&Norm은 위의 Attention부분에서 설명한 Concatnation부분입니다.
3.1 Multi - head attention
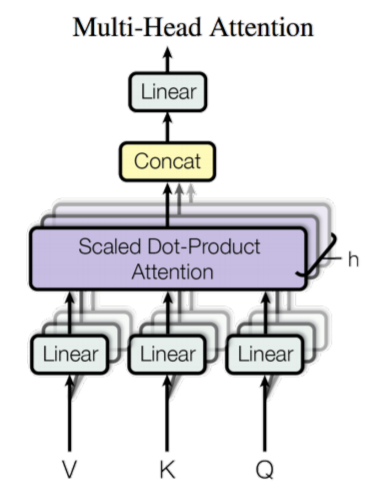
Multi-head attention은 단순히 한번의 Attention을 하는 것 보다는 한번에 여러개의 Attention을 수행하는 것이 효과적이라고 판단하여 수행되는 작업 입니다.
마치며
이번 포스팅에서는 Transformer에 관하여 알아보았습니다. Transformer는 NLP분야 뿐만 아니라 서서히 딥러닝 전반 모든 분야에서도 탁월한 성능향상에 효과가 있다고 알려져 있습니다. 하지만 Query한개마다 모든 vector를 참고해야하며 이 Query가 모든 Vector를 돌아가면서 체크하기 때문에 연산량이 많고 메모리도 많이 차지하고 있습니다.