
Deep Learning - NLP__PLMs
1. PLMs이란
PLMs는 Pretrained Language Models의 약자로 사전에 대규모로 시행된 학습 결과를 이용하는 것을 의미합니다.
이 PLMs를 설명하기에 앞서 중요한 개념 두가지를 설명하고자 합니다.
-
Transfer Learning
-
Self-Supervised Learning
입니다.
2. Transfer Learning
2.1 탄생배경
데이터는 학습하고자 하는 목적에 따라 달라지기 마련입니다. 예를 들어 동물 이미지 분류를 위해서는 동물사진을, 뉴스기사를 학습하기 위해서는 뉴스기사를 데이터로 사용하는 것과 같습니다.
하지만 동물사진이 아닌 식물사진을 사용하였다 하더라도 사진이라는 범주인 이상 외각선, 색의 분포 등 분명히 공통되는 features가 존재 할 것입니다. 언어 또한 마찬가지로 아무리 SNS의 글을 데이터로 사용하였다 하더라도 같은 언어인 이상 뉴스기사와 공통된 features를 가지고 있을 것 입니다.
그렇기에 Transfer Learing은 Different but related, 즉 다르지만 유사한 문제를 해결하기 위해 탄생하였습니다.
2.2 구조
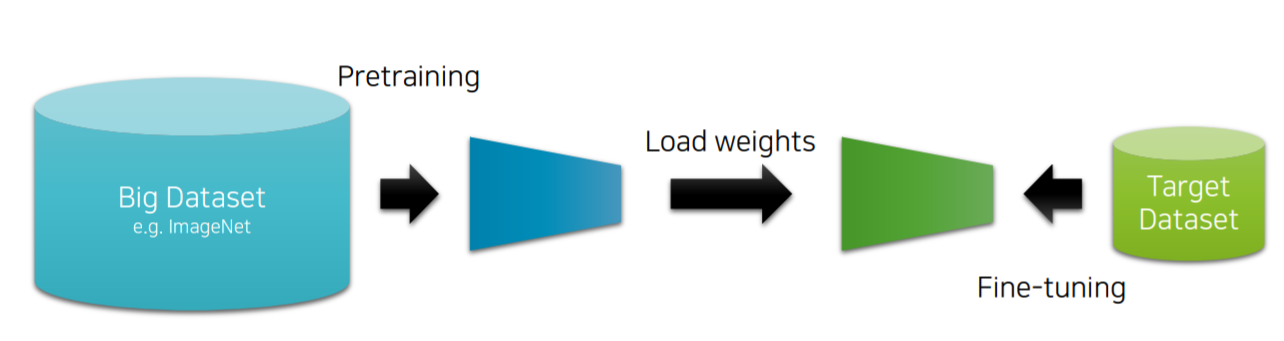
수만은 다르지만 유사한데이터를 수많은 하드웨어, 시간과 같은 자원들을 사용하여 Pretraining합니다. 이를 학습의 weight로 사용하며 자신의 목적에 맞는 데이터를 가져와 다시한번 fine tuning이라는 학습을 거칩니다.
구체적으로는 총 3가지 방법이 있습니다.
- pretrained된 weight를 초기 weight로 설정하고 학습을 진행하는 방법
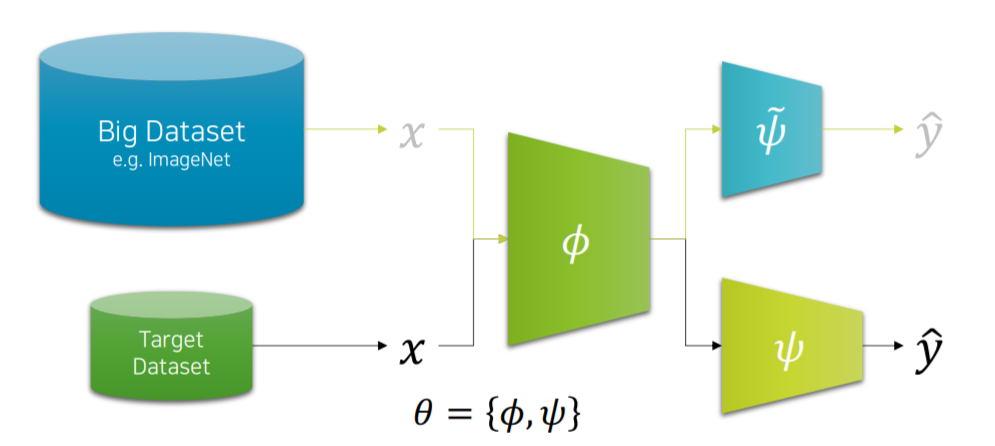
위 그림은 Transfer Learning을 도식화 한 것 입니다. 위의 과정이 pretrained weight를 학습하는 과정이며 이 때 생성된 $\phi$를 초기 weight로 설정하며 학습을 진행하는 것 입니다. $\psi$는 fine tuning을 위한 다음 학습 층이며 이미지 classification을 예로 들자면 pretraining단계와 target train의 구분하고자 하는 분류체계가 다를 것이니 다시한번 softmax층을 올려 학습하는 것 과 같이 이해하셔도 됩니다.
- pretrained된 weight를 초기 weight로 설정하나 이 weight는 고정하고 학습을 진행하는 방법
간단히 말해 $\phi$는 변하지 않고 $\psi$만 update하며 학습을 진행하는 방법입니다.
- pretrained된 weight와 fine tuning의 weight에 다른 learning late를 주는 방법
$\phi$에 작은 learning late를 주고 $\psi$에 큰 learning late를 준다면 pretrained에서 추출한 특징들을 최소한으로 target학습에 변형시키며 최적화 시킬 수 있을 것입니다.
3. Self-Supervised Learning
Self-Supervied Learning은 데이터의 내부구조를 활용하여 label이 없지만 마치 있는것처럼 활용하여 학습하는 것을 의미합니다.
학습 방법으로는 Contrastive Learning을 활용합니다. 이는 특정 데이터와 유사한 postive pair와 전혀 다른 negative pair를 설정 한 후 데이터와 postive pair의 유사도, 거리는 가깝게, negative pair의 유사도는 멀게 학습하는 방식입니다.
이전 Embedding 포스팅에서 설명하였던 Skip-gram with negative sampling이 Self-Supervied Learning입니다. 특정 단어의 window내의 단어를 postive pair, window밖의 단어를 negative pair로 설정한 것 입니다.
3.1 의의
Self-Supervied Learning을 하는 이유는 결정적으로 supervsied learning이 일일이 labeling이 필요하고 이 작업이 너무 비 효율적이기 때문입니다. 그렇다고 unsupervised learning을 이용하기에는 성능이 떨어졌습니다. 그렇기에 쉽게 데이터를 수집하고 성능을 높이는데 큰 역할을 하고 있습니다.
4. PLMs
PLMs는 Transfer learning으로부터 좋은 weight paramerter seed를 얻어 Self-Supervied Learning으로 한정된 데이터 셋에서도 좋은 성능을 얻기 위한 방식입니다.
그렇기에 장점으로는 상대적으로 적은 데이터를 가지고도 좋은 성능을 발휘 할 수 있습니다. 또한 사전에 trained된 weight를 사용하기 때문에 적은 resource를 가지고도 구현 할 수 있습니다.
마치며
이번 포스팅에서는 PLMs에 대하여 알아보았습니다. PLMs는 여러 라이브러리의 발전으로 지금은 구현또한 무척 간단하고 성능도 좋습니다. 이번 포스팅에서는 앞으로 PLMs를 자세히 알아보기에 앞서 개념을 위주로 정리해 보았습니다.