
Deep Learning - NLP__Embedding
1. Embedding
이번 포스팅에서는 임베딩에 관하여 조금 더 자세히 알아보도록 하겠습니다.
1.1 Vector Space Model
Vector space Model의 기본은 단어를 one-hot vector로 표현 하는 것 입니다.
단어라는 것은 하나의 단어가 다양한 의미를 포함하기도, 서로 다른 단어가 같은 의미를 포함하기도 합니다.
하지만 one-hot vector로는 이러한 특성을 전혀 반영 할 수 없습니다.
- TF-IDF
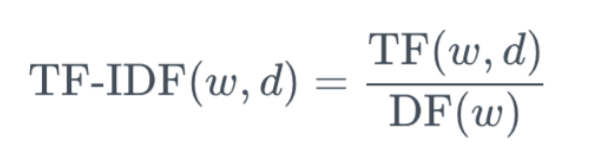
어떤 단어 w가 특정 문서 d 내에서 얼마나 중요한지를 나타내는 수치입니다.
TF는 단어의 문서 내 출현 횟수를 의미하며 DF는 그 단어가 출현한 문서의 역수입니다.
이 때 한 문서 내 단어 출현횟수는 제한된 수를 가지지만 문서의 숫자는 그렇지 않기 때문에 DF에 log를 취하여 스케일 조정을 하기도 합니다.
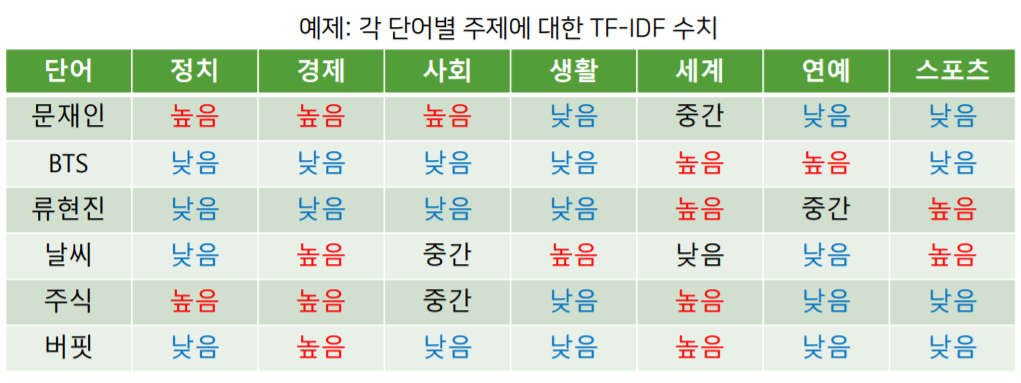
위 그림은 문서별로 TF-IDF 수치를 벡터화 하여 표현 한 것 입니다.
이 처럼 TF-IDF는 단어의 중요도라는 새로운 정보를 포함 시킬 수 있지만 여전히 vector가 Sparse하다는 단점이 있습니다.
Sparse vector란 전체 단어를 포함하는 사전은 방대하지만 사용된 단어수가 극단적으로 적기 때문에 차원이 너무나 큰 벡터를 뜻합니다.
1.2 NNLM
Sparse한 vector대신 Dense한 vector를 사용하기 위해 Neural Network를 사용한 embedding 방법입니다.
- Word2Vec
Word2Vec은 CBOW방식과 Skip-gram방식이 있습니다.
그 중 Skip-gram 구조에 대해 알아보려고 합니다.
- Skip-gram
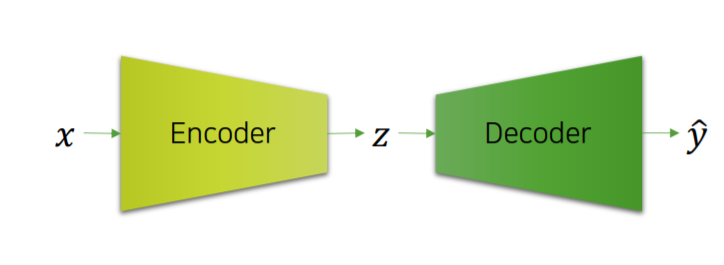
주변(Context Window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터값을 가져야 한다는 것을 구현한 모델입니다.
기본적으로는 Auto Encoder와 상당히 비슷합니다.
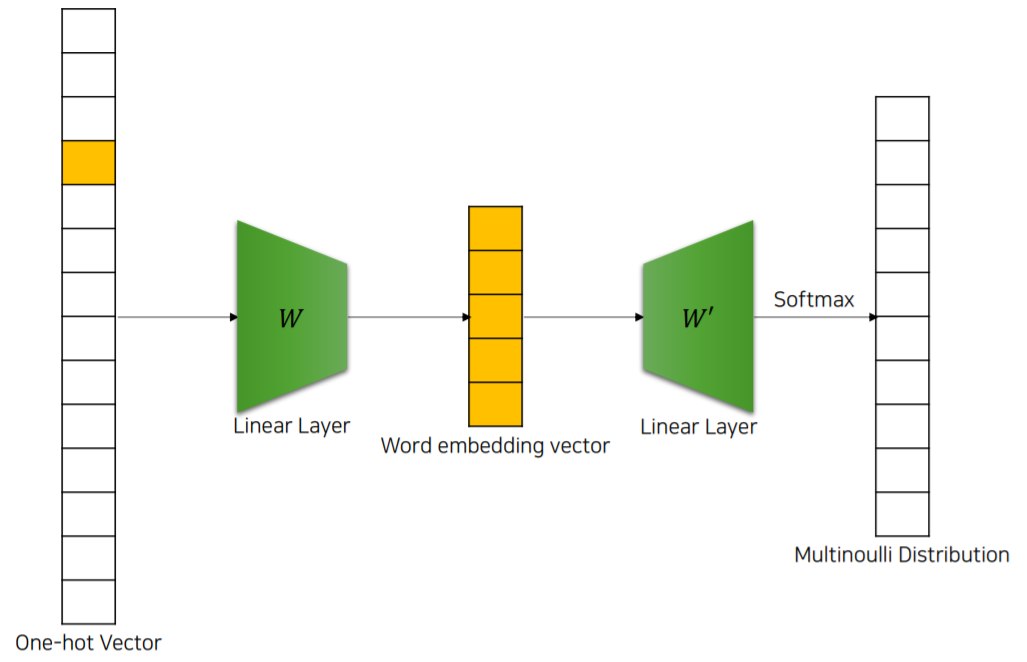
one-hot encoded된 특정 단어 벡터 x를 넣으면 주변(Context Window)에 있는 단어 $\hat y$이 나오도록 학습하는 구조입니다. 이를 Word2Vec의 Skip-gram구조라고 합니다.
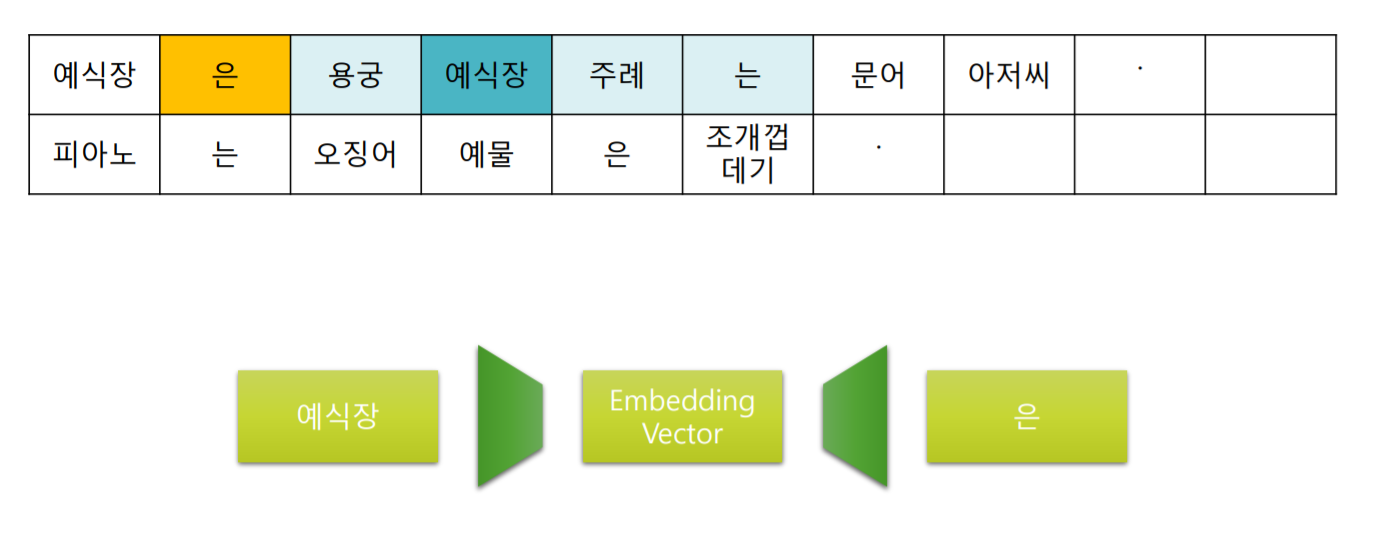
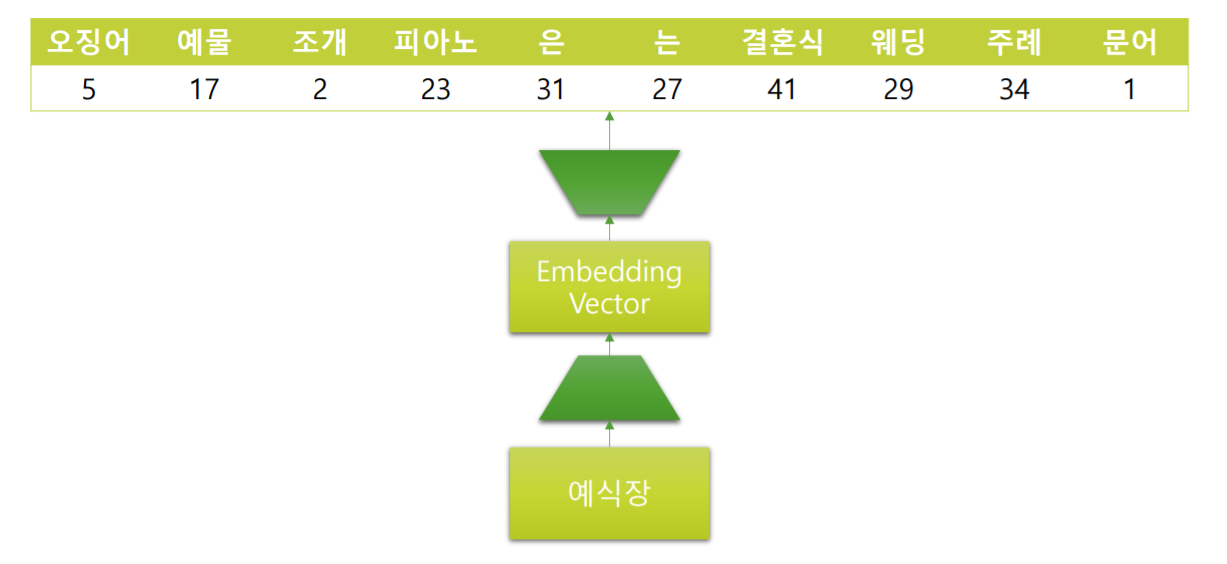
위 그림은 window 가 5인 Skip-gram을 도식화 한 것 입니다.
가장 첫 “예식장” 부터 Context Window가 모든 단어를 순차적으로 이동하면서 주변 단어를 예측하도록 학습합니다.
- GloVe
Skip-gram이 Context Window를 움직여서 모든 단어에 대하여 Classification을 하였다면 GloVe는 단어 x와 Context Window내에 함께 출현한 단어들의 출현빈도를 Regression을 통해 맞추는 학습을 합니다.
때문에 Skip-Gram보다 더욱 빠른 속도를 내며 출현빈도가 적은 단어를 비교적 정확하게 탐색할 수 있습니다.
- FastText
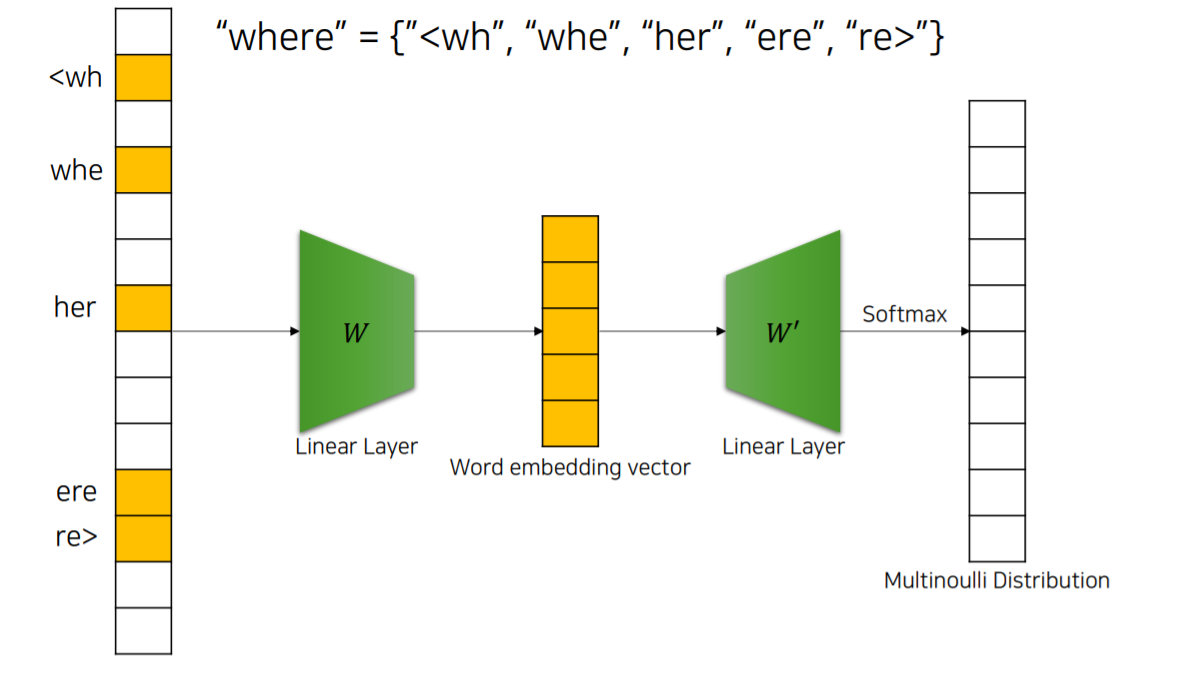
Skip-gram의 발전형 입니다. Skip-gram은 단어 하나를 one-hot encoding을 통해 표현하기 때문에 출현빈도가 적은 단어들에 대해서는 적은 학습량으로 정확한 학습이 불가능 합니다.
FastText는 단어를 subword로 나누고 Skip-gram구조를 활용하여 학습합니다.
최종적으로 Subword에 대한 embedding vector의 합이 word embedding vector가 됩니다.
- Skip-Gram with Negative Sampling
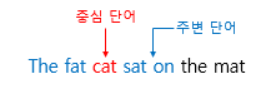
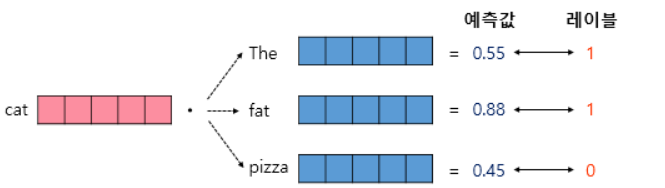
위와 같은 문장으로 부터 Skip-gram을 시도해 보겠습니다.

이 방식은 cat이라는 INPUT을 최종적으로 softmax를 통해 window내의 단어인 sat으로 출력해내는 방식 입니다.
하지만 one-hot encoding된 단어 사전의 크기가 수만가지나 된다면 위와 같이 사용되지도 않는 단어에 대한 update는 굉장히 비효율적입니다.
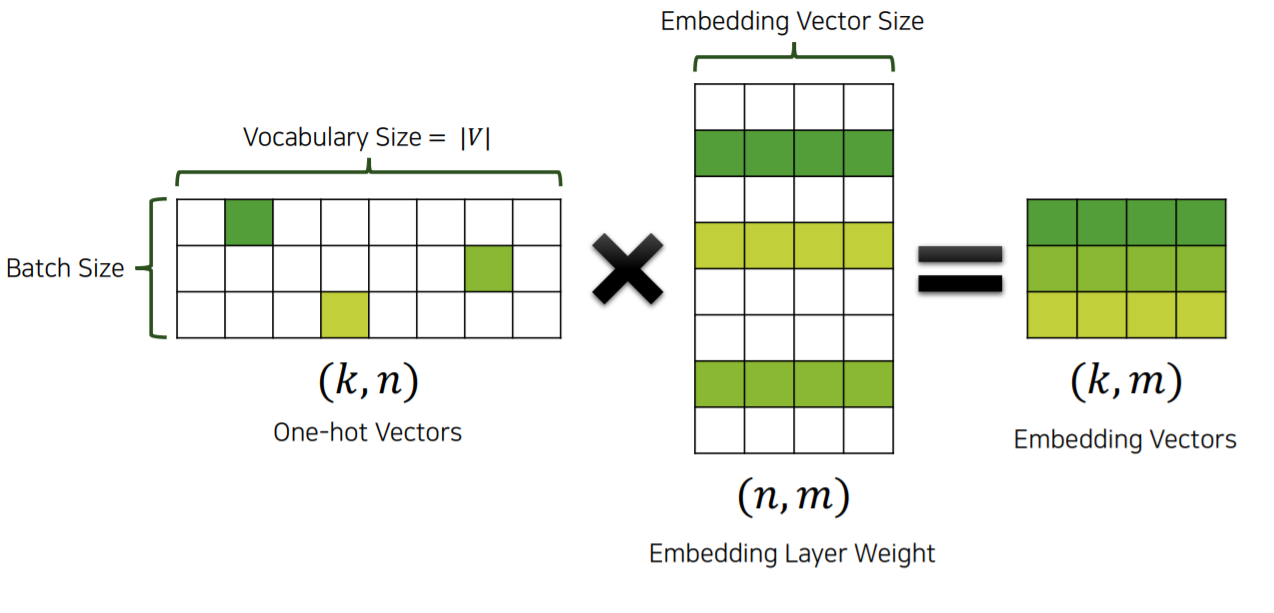
Negative Sampling방식으로 넘어가기 전에 Embedding vector에 대해 잠시 알아보겠습니다.
Input으로 주어진 단어는 one-hot encoding된 단어이기 때문에 Embedding layer weight중 한 vector만을 추출하는 효과를 가지고 있습니다.
그렇기 때문에 Embedding layer weight는 각 단어의 정보에 대한 vector로 이루어져 있습니다.
즉 Embedding vector는 Embedding layer weight에서 필요한 단어의 weight를 추출해온 vector라 할 수 있습니다.

Negative Sampling 방식은 중심단어와 주변단어가 window내에 있을 확률을 계산합니다.
이 때 주변단어는 window내에 있는 Positive와 window 밖에서 랜덤하게 sampling한 Negative가 있습니다.
Negative Sampling은 중심단어의 Embedding vector와 주변단어의 Embedding vector를 유사도를 연산하여 Positive인지 Negative인지 구분하는 Binary Classification을 진행합니다.
Update는 Positive의 확률을 높이면서 Negative의 확률을 낮추는 방향으로 진행되며 Embedding layer weight를 update하게 됩니다.
기존의 방식과 다른점은 전체 단어집합으로 Classification하는 문제에서 전체 단어 집합보다 훨씬 작은 집합을 만들어 그 안에서 Postive인지 Negative인지를 구분하는 Binary Classification으로 변환되었다는 점 입니다.
즉 연산에 사용되는 vector의 사이즈가 확연하게 줄었기 때문에 연산에 있어 굉장히 효율적이게 됩니다.
2. Embedding의 역할
-
학습에 있어 자연어를 vector화 시키는 것이 Embedding입니다.
-
이 때 one-hot encoding된 vector와 SGNS(Skip-gram with Negative Sampling)된 Embedding vector를 넣는가는 정보량과 차원의 저주문제에 있어 확연히 다른 결과를 가져 옵니다.
-
그렇기 때문에 차원을 축소하고 데이터를 압축하는 PCA와 Auto Encoder와 같은 역할을 한다고 생각하면 됩니다.
마치며
ML과 DL의 가장 큰 차이점은 데이터의 전처리를 인간이 직접 하는가 모델에 맡기는가 로 결정됩니다. CNN의 Conv연산 또한 이미지의 정보를 압축하는 과정이었으며 Embedding또한 RNN연산을 하기 앞서 모델에게 자연어 라는 정보를 압축시키는 과정입니다. 현재는 지금까지 포스팅한 Word Embedding방식을 넘어 Sentence Embedding방식이 존재하나 처음 NLP과정을 학습하는데 있어 너무 복잡하기 때문에 이번 포스팅에서는 작성하지 않겠습니다.