
Deep Learning - Generative models
1. Generative models란?
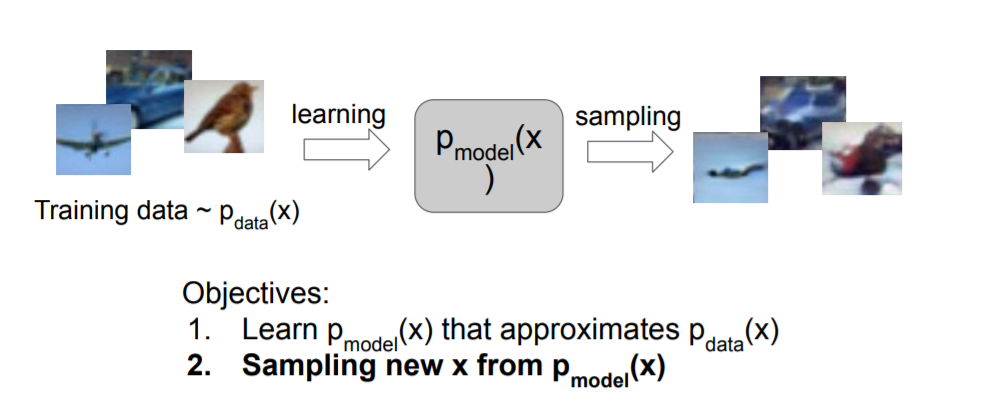
Generative model은 주어진 training data에서 같은 분포(p)를 가지는 새로운 data를 생성하는 모델입니다.
분포로 표현되는 p는 likelihood function이며 보통 Gaussian distribution을 따르는 확률분포함수(Probability Density Function)을 사용합니다.
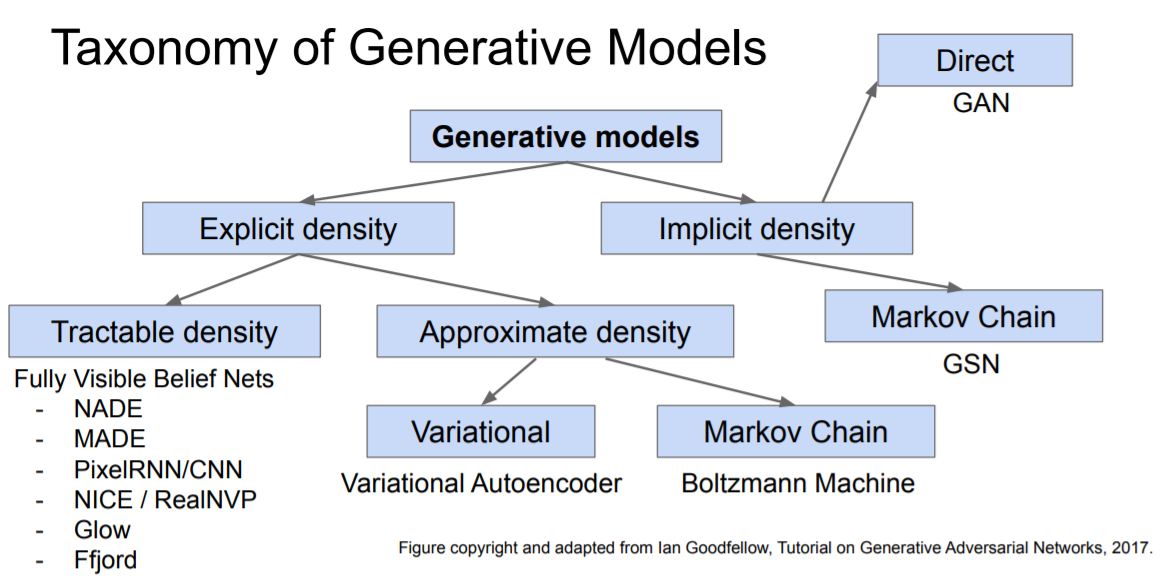
다양한 Generative model이 존재하며 이번 포스팅에서는 Variational AutoEncoder(VAE) 와 GAN 을 주로 다룰 예정입니다.
2. Variational AutoEncoders
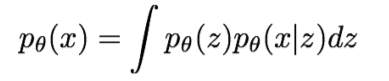
VAE는 intractable density function을 정의하기 때문에 latent z라는 개념이 도입됩니다.
intractable density function은 간단하게 표현 할 수 없는 분포함수로 tractable density function이 단순하게 Gaussian distribution으로 표현되는 것에 비해 쉽게 추정할 수 없는 z term이 발생하고 이를 Neural Network를 이용해 추정하게 됩니다.
2.1 AutoEncoders
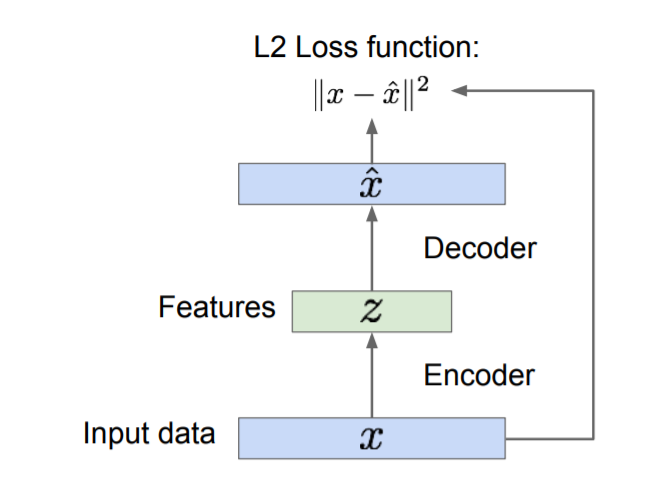
VAE를 알아보기 이전에 AutoEncoders의 개념을 먼저 살펴보겠습니다.
AutoEncoder는 위 사진과 같은 구조를 가지고 있는 Unsupervised learning입니다.
Encoder 를 이용하여 DATA x를 묘사하는 feature z를 생성합니다. 주로 CNN이 사용됩니다.
이 때 z는 원본 DATA의 중요한 요소만 추출한 것이기 때문에 x보다 사이즈가 작습니다.
생성된 feature z를 Decoder를 이용하여 다시 복원한 $\hat x$ 를 생성하며 이를 이용해 Loss 를 계산합니다.
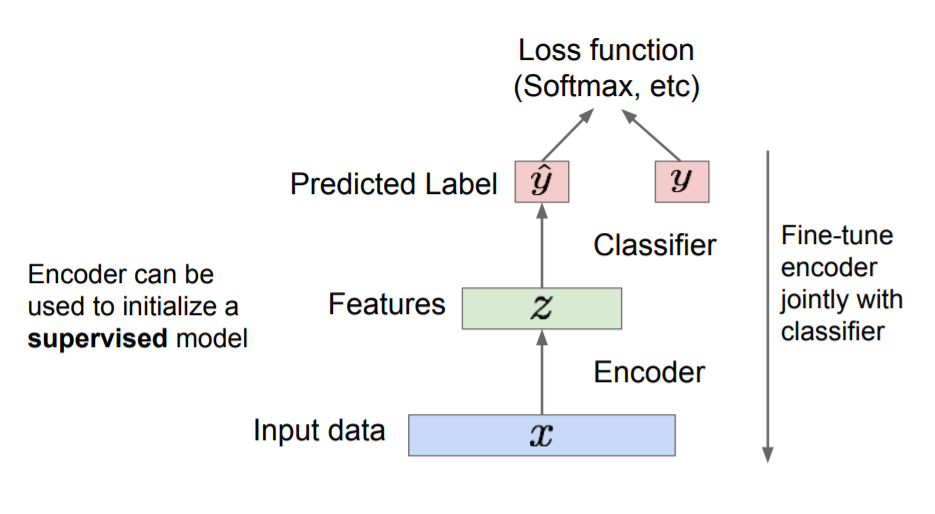
이제 생성된 z에서 Decoder를 떼버리고 평범한 Classification모델에 적용할 수 있습니다.
AutoEncoder는 이렇게 feature size를 줄이는 특징 때문에 feature engineering에서 주로 사용됩니다.
2.2 VAE
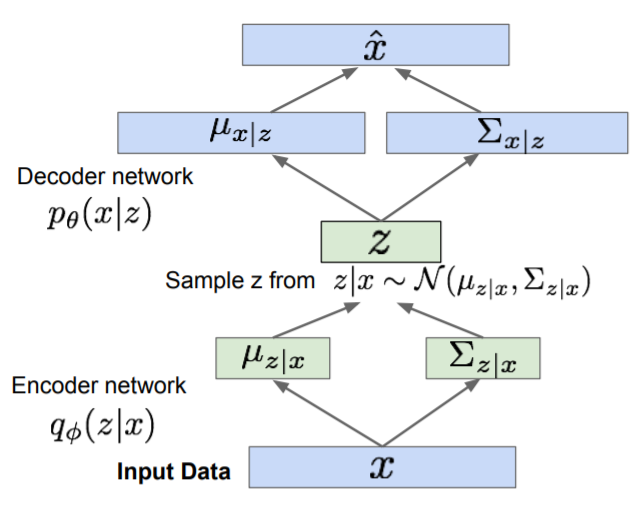
VAE는 AutoEncoders를 사용하여 새로운 DATA인 $\hat x$를 생성하는 모델입니다.
input DATA, x의 평균과 분포를 구한 후 이를 이용하여 x의 PDF(Probability Density Function)를 생성합니다.
생성된 PDF를 활용하여 random sampling된 z를 추출합니다.
똑같은 방식으로 z의 평균과 분포를 활용하여 PDF를 생성하고 random sampling 된 $\hat x$를 생성합니다.
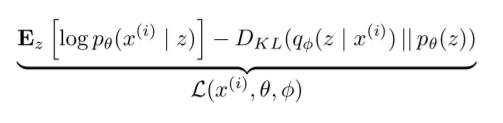
VAE는 Gradient discent를 이용해 Loss를 줄이는 것이 아닌 likelihood의 Lower bound를 최대화 하는 방향으로 update합니다.
위 수식이 likelihood의 Lower bound이며 DKL은 PDF의 유사도를 나타내며 양수로 표현됩니다.
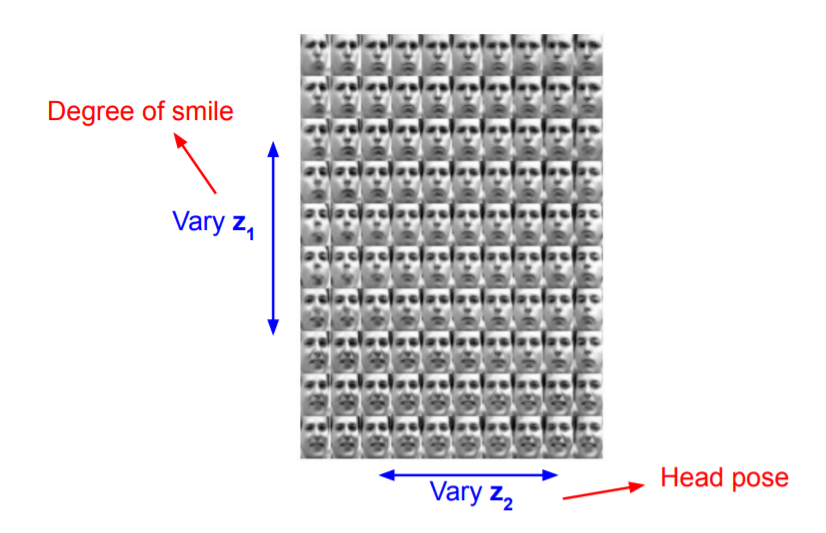

위 사진이 VAE를 사용하여 생성된 이미지 입니다.
Degree of smile, Head pose라는 z1, z2를 생성하고 그에 따른 이미지를 생성한 것 입니다.
두번째 사진또한 VAE를 이용하여 생성한 이미지지만 모든 z의 PDF가 Gaussian distribution을 따르지 않기 때문에 뿌옇게 생성되는 단점또한 존재합니다.
3. Generative Adversarial Networks(GAN)
- Discriminator : 주어진 image가 FAKE인지 REAL인지 1과 0으로 구분하는 부분입니다.
-
Generator : Discriminator를 속이고 REAL이미지를 닮은 FAKE이미지를 생성하는 부분입니다.
- GAN은 Discriminator 와 Generator가 서로 경쟁하며 학습하는 모델입니다. 최종적으로 잘 학습된 Generator만을 이용하며 artificial image generator 분야에서 주로 사용됩니다.
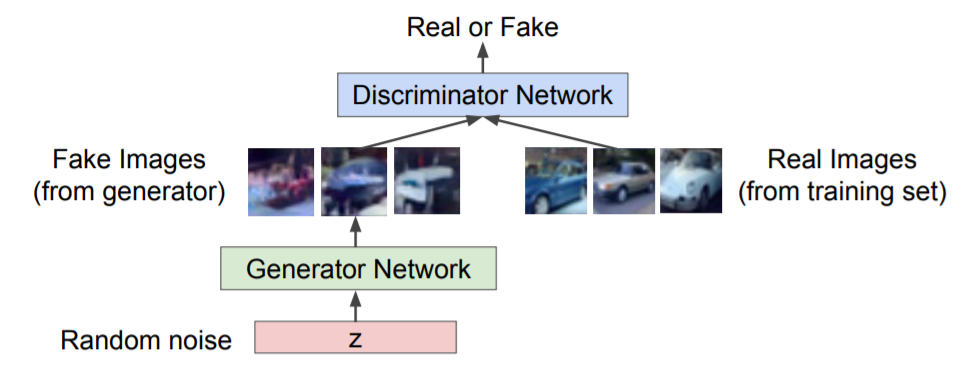
GAN의 구조는 위와 같습니다.
normal distribution을 통해 random sampling된 noise를 generator에 넣고 FAKE image를 생성합니다.
그 후, REAL data와 섞은 후 discriminator에 넣은 후 REAL, FAKE를 판단하는 과정을 반복합니다.
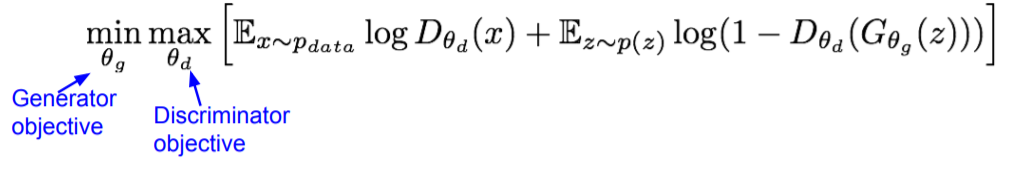
위 수식은 GAN의 objective function입니다. 이 전 까지의 loss function과 같은 역할을 하며 이 objective function을 최소화하는 방향으로 업데이트가 진행됩니다.
objective function의 첫번 째 term은 REAL dataset에서 sampling한 x를 discriminator에 넣고 판단 하는 것 입니다.
두번 째 term은 normal distribution에서 sampling한 z를 generator에 넣어 FAKE를 생성하고 이를 discriminator에 넣고 판단 하는 것 입니다.
$\theta$d는 discriminator의 parameter를, $\theta$g는 generator의 parameter를 나타냅니다.
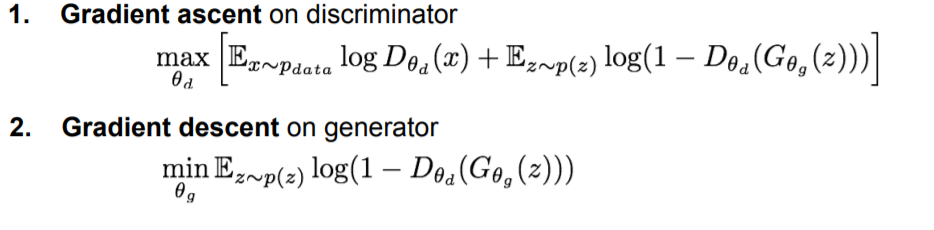
따라서 discriminator 는 Gradient asecent를 이용하여 maximize하며
generator는 Gradient discent를 이용하여 minimize해주는 방향으로 학습을 진행하게 됩니다.
generator의 gradient discent가 짧은 이유는 옆의 term은 $\theta$g term이 없기 때문입니다.
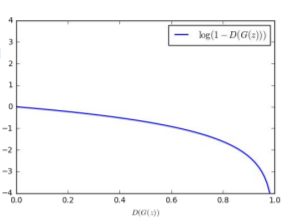
여기서 한가지 문제가 발생하는데 generator의 gradient가 위 그림과 같기 때문에 sample, z가 FAKE일수록 gradient가 완만하기 때문에 학습이 천천히 이루어지고 REAL에 가까워지면서 discent가 잘 이루어지게 되는데 이미 REAL에 가깝기 때문에 상당히 비효율적이게 됩니다.

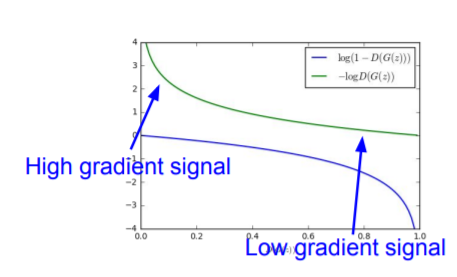
따라서 objective function을 위와 같이 변경 한 후 Gradient asecent를 해주어 gradient를 위 그래프와 같이 변경해주고 학습합니다.

이는 GAN의 실제 traning process입니다.
random distribution과 REAL dataset으로부터 z와 x를 m개만큼 추출한 후 discriminator를 먼저 학습해주는 과정을 k번 반복합니다.
그 후, 다시한번 z를 m개 추출한 후 generator에 넣고 discriminator로 판단하는 학습을 진행합니다.
이 과정을 itreation만큼 진행하는 것이 GAN의 전체적인 학습 과정입니다.
generator와 discriminator가 서로 경쟁하기 때문에 objective function은 0.5 정도가 가장 이상적이며 iteration을 전부 돌거나 objective function이 이상적인 수치가 나올 때 까지 반복합니다.
이렇게 학습한 $\theta$d, $\theta$g 중 $\theta$g를 포함한 generator를 사용하여 새로운 데이터를 생성하는 것이 GAN입니다.
3.1 발전
- 위 objective function에서는 Discriminator를 log term에 넣어 확률로 나타내었지만 이 objective function을 변형하면 다양한 GAN을 구상할 수 있습니다.

현재는 다양한 GAN방식을 사용하며 이러한 GAN들로 위와 같은 FAKE image를 생성 할 수 있습니다.
현재는 상당수의 GAN이 있으며 이러한 GAN을 모아놓은 The GAN Zoo가 존재합니다.
마치며
이번 포스팅에서는 generative models에 관하여 알아보았습니다. 수학적인 부분을 자세히 다루게 된다면 상당히 복잡하고 이해하는데 model들을 이해하는데 도움이 되지 않기에 과감하게 생략하였습니다.