
Ensemble Learning
1. Ensemble Learning이란?
-
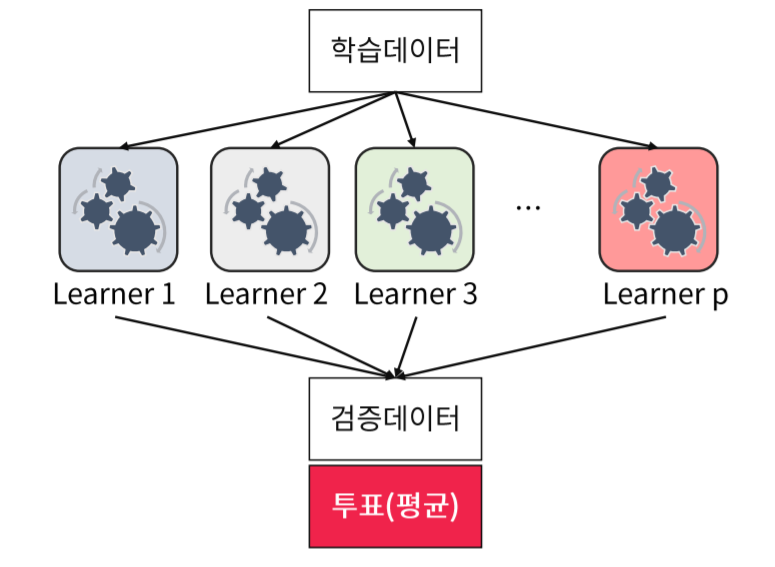
Ensemble Learning이란 여러개의 기본모델을 활용하여 하나의 모델을 만들어 내는 개념입니다. -
이 때의 기본모델을
weak learner,classifier,base learner,single learner라고 부릅니다.
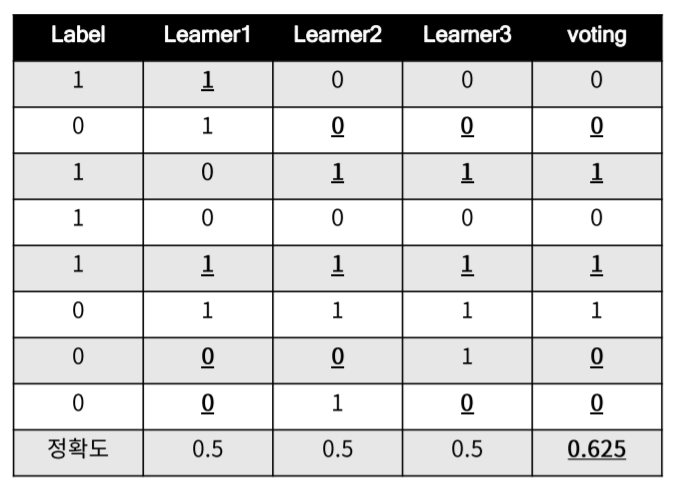
ensemble learning 은 voting이라는 개념을 사용하여 Y, 종속변수를 결정합니다.
위와 같이 정확도가 0.5인 모델들을 voting하여 Y를 결정한다면 정확도 0.625라는 보다 높은 정확도의 모델이 탄생하게 됩니다.
1.1 Ensemble의 종류
-
ensemble은 단순히 여러개의 기본모델을 결합하여 voting을 통해 결과를 도출하는 기법입니다.
-
그 중
Tree기법을 이용한 Ensemble 기법이 다음과 같이 존재합니다. -
Bagging
-
Random Forest
-
Boosting
2. Bagging(bootstrap aggregating)
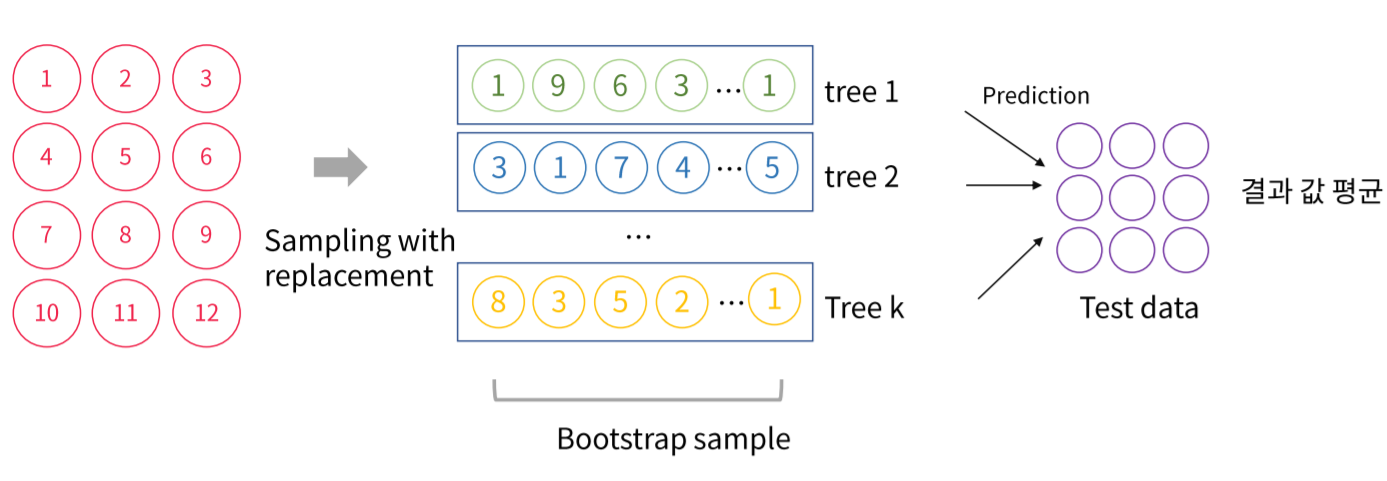
Bagging은 데이터를 랜덤하게 복원추출, 한번 추출하였던 데이터도 다시 추출할 수 있게 하여Tree를 여러개 구성하고 이 결과값들을Voting하는 ensemble기법입니다.
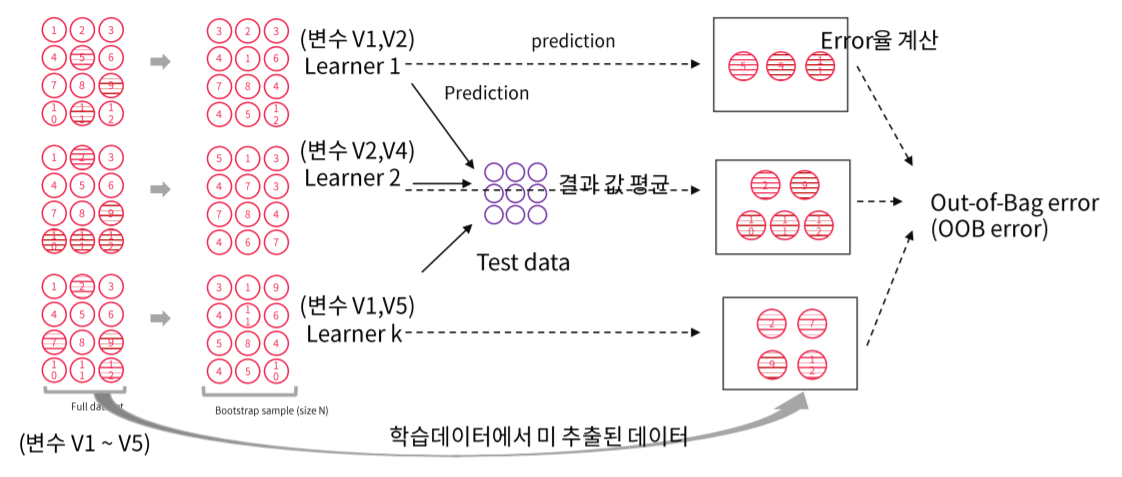
데이터를 복원추출하기 때문에 중복된 데이터가 생기며 동시에 사용하지 않아 빈 데이터도 생기게 됩니다. 이러한 빈 데이터의 error율을 계산하여
Out of Bagerror(OOB error)를 계산합니다.
전체 데이터를 사용한
Tree기법은 깊이가 너무 깊어진다면 분산이 증가하고 과하게 overfitting이 됩니다. 하지만Bagging은 랜덤하게 사용하지 않는 데이터가 발생하기 때문에 이러한 분산을 감소시키며 데이터의 noise에 민감한Tree의 단점을 극복 할 수 있습니다.
3. Random Forest
Bagging은 중복되는 데이터를 대다수 포함하고 있기 때문에 분산을 감소시킬 수는 있으나 각 데이터가 독립이라는 조건을 보장 할 수 없습니다.
즉 변수 사이의 공분산을 줄이기 위하여 데이터 뿐만 아니라 변수, 즉 features또한 랜덤으로 선정하는 기법이
Random Forest입니다.
선정하는 변수의 갯수는 직접 선정하여야 하는 hyper parameter이며 일반적으로 변수의 수의 루트값을 사용합니다.
Random Forest는 데이터 뿐만 아니라 변수 또한 랜덤으로 선정하기 때문에 변수들 사이의 공분산이 줄어들며 일반적으로Bagging보다 성능이 좋습니다.
4. Boosting
-
Boosting 기법은 기본적으로 오분류된 데이터에 초점을 맞추어 더 가중치를 두는 기법입니다.
-
Boosting은 크게 Adaboost, 와 Gradient Boosting으로 구분 할 수 있습니다.
4.1 Adaboost
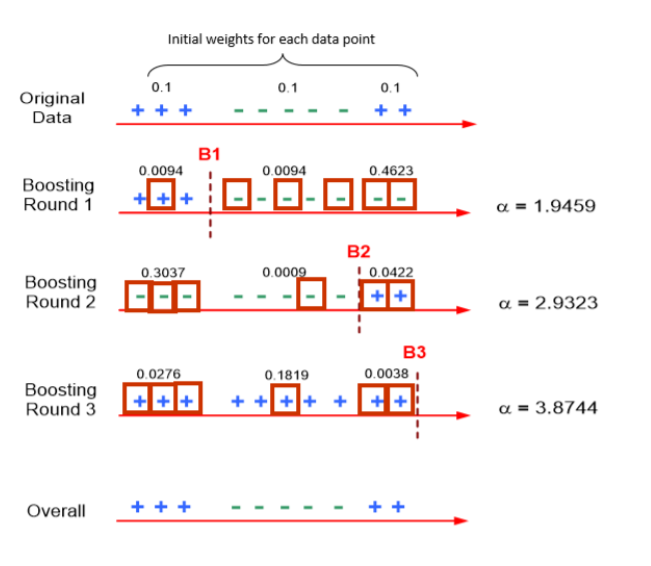
처음에는 각 데이터에 대한 가중치를 전부 동일하게 둡니다.
하지만 Round 1에서 빨간색으로 네모친 부분의 데이터가 수집되며 이 데이터들을 기반으로 + 와 -를 구분하는 B1을 설정합니다.
이 때 오분류 된 데이터들에 더 큰 가중치를 두어 업데이트하고 업데이트한 가중치의 확률로 다시한번 Round 2 와 B2를 설정합니다.
이와 같은 과정을 설정한 반복횟수 만큼 반복하면 기존 데이터와 유사한 추정 값을 얻는 기법을
Adaboost라고 합니다.
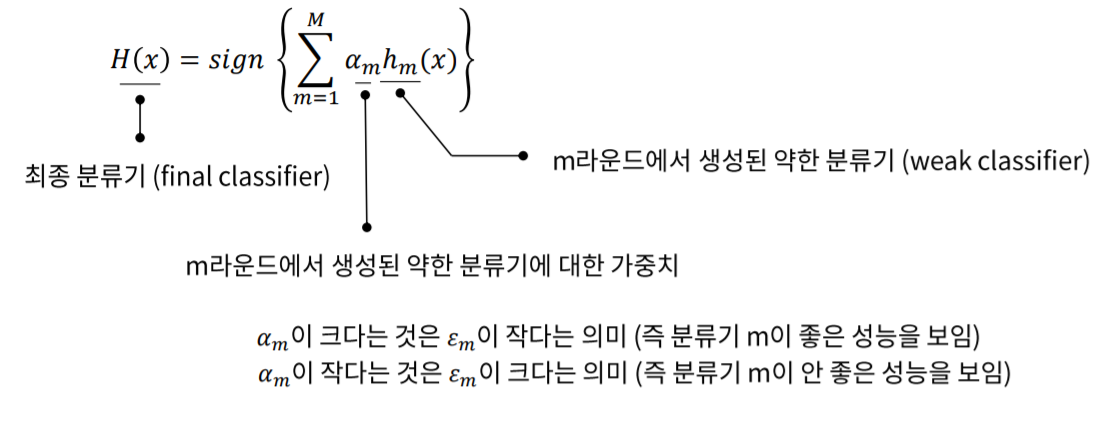
최종적으로 각 데이터의 가중치와 weak learner를 고려하여 모델을 선정하게 됩니다.
4.2 Gradient Boosting
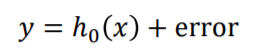

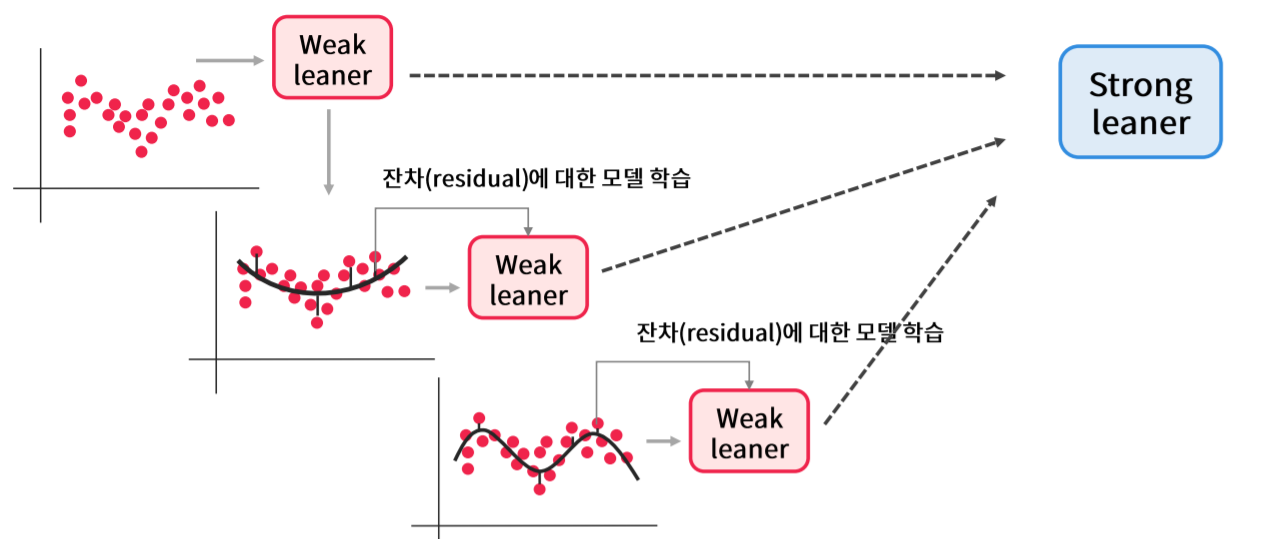
Gradient Boosting은 데이터별 오류를 예측하는 새로운 weak learner를 학습하는 기법입니다.
weak learner h0 를 이용하여 y를 예측하고 error를 얻었다면 이 error를 줄이는 방향으로 모델을 발전시켜야 할 것 입니다.
그렇기 때문에
Gradient Boosting은 다음으로 error를 예측하는 h1 를 생성하고 이 때 생성된 error에 대하여 다시 또 학습을 합니다.
최종적으로 error가 0에 수렴하였다면 학습을 멈추고 최종 모델을 도출합니다.
4.2.1 XGBoost
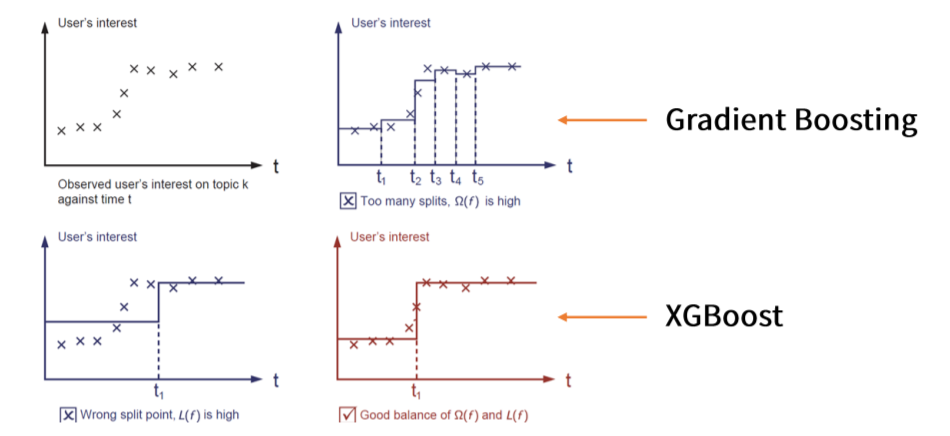
XGBoost는 Gradient Boosting의 일종으로 기존의 Gradient Boosting이 과적합에 취약하다는 점을 Regularization term을 이용하여 복잡한 모델에 페널티를 준 기법입니다.
계수 축소법의
Ridge와 비슷한 개념으로 이해하면 됩니다.
4.2.2 LightGBM
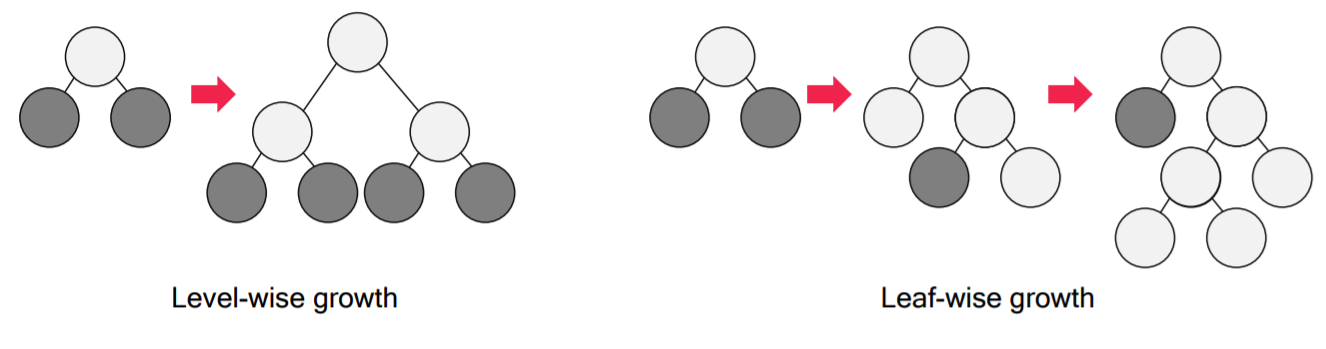
XGBoost처럼 Gradient Boosting기법이지만 이와는 다르게 leaf-wise-loss를 사용합니다.
XGBoost보다 빠르며 overfitting에 민감하지만 대량의 데이터를 필요로 합니다.
4.2.3 Catboost
마찬가지로 Gradient Boosting 기법 중 하나로 주로 categorical features에 잘 맞는다고 알려져 있습니다.
Categorical features를 수치형으로 변환하는 방법을 제안합니다.
5. 중요변수 추출방법
-
Ensemble모델은 정확도가 높지만 Linear Regression처럼 모델이 단순하지 않아 모델에 대한 해석과 설명이 매우 어렵습니다.
-
그렇기 때문에 XGBoost는 weight, cover, gain 라는 척도를 사용하여 변수의 중요도를 설명하곤 합니다.
-
하지만 같은 모델 내에서도 각 척도별로 변수의 중요도가 달라지기 때문에
Shap 지수를 사용합니다.
5.1 Shap 지수

Shap지수는 간단하게 기여도 라고 생각하면 편합니다.
측정 방법은 특정 변수를 지정하고 나머지 features를 랜덤으로 지정한 후 예측값을 측정한 이후 이번에는 선택한 변수를 랜덤하게 바꿔 다시한번 측정합니다.
이러한 과정을 여러번 거친 평균을 구한 것이 Shap 지수 입니다.
Shap지수는 위의 세 척도보다는 모델별로 일정한 성질을 지니고 있습니다.
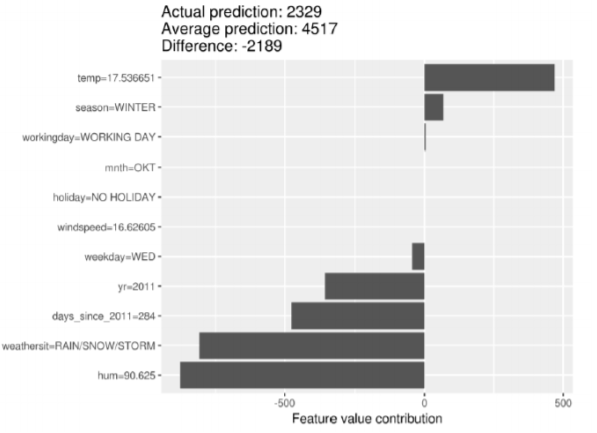
위와 같은 자전거 렌탈 수 예측 모델이 있다고 하였을 경우 기온이 렌달수에 가장 긍정적인 영향을 끼친다고 해석 할 수 있습니다.
반대로 습도와 기상상황은 부정적인 영향을 끼친다고 해석 할 수 있습니다.
하지만 Shap지수는 상관관계일 뿐 인과관계가 아니기 때문에 정량적인 수치로 해석하지 않도록 주의해야 합니다.
마치며
ensemble기법은 모델의 해석과 설명이 어렵다는 단점이 있으나 정확도가 높기 때문에 Data science대회에서 자주 입상하는 모델입니다. 또한 변수들이 graphical한 features와 같이 거대하고 복잡한 변수들이 아니라 정량적인 변수들이라면 딥러닝 기법보다 뛰어난 성능을 지니고 있습니다. 그렇기 때문에 딥러닝이 발전한 지금 현업에서도 꾸준히 ML기법을 사용하고 있으며 어떠한 방식으로 계산하는지, 특징을 가지는지를 알아 두어야 합니다.