
k-Nearest Neighborhood
1. KNN(k-Nearest Neighborhood)란?
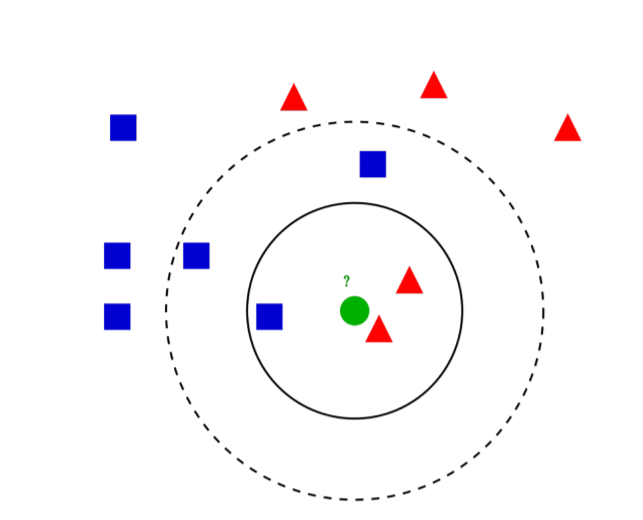
위 그림에서 중심, 녹색 점은 실선을 기준으로 빨간색, 점선을 기준으로는 파란색 으로 분류 할 것 입니다.
그 이유는 가장 근접한 이웃들이 실선에는 빨간색이 가장 많으며, 점선 안에는 파란색이 가장 많기 때문입니다.
이처럼 거리가 가까운, 최근접 이웃 k개를 살펴보았을 때 가장 많은 쪽으로 분류하는 모델이
KNN입니다.
- k를 정하는 법
k는 직접 설정해 주어야 하는 변수입니다.
이 때 k가 너무 크다면 분류가 제대로 이루어 지지 않을 것이며 너무 작다면 overfitting이 일어날 것 입니다.
또한 특정 feature가 너무 많다면 거리에 반비례하는 wight를 주어 그 비중을 조절해야 합니다.
KNN은 k라는 갯수에 영향을 받기 때문에 불필요한 변수에 큰 영향을 받기 쉽습니다. 따라서 적절하게 중요한 변수를 선택해주어야 합니다.
- 종속 변수, Y
Y는 범주형(categorical) 변수, 혹은 연속형(numerical) 변수로 나타날 수 있습니다.
범주형 일 경우는 가장 많이 나타나는 범주로 Y를 추정하며 연속형 일 경우 대표값(평균)을 이용하여 Y를 추정합니다.
- 설명 변수, X
KNN은 관측치, 즉 데이터 사이의 거리를 이용하여 계산하는 모델입니다.
그렇기 때문에 X사이의 거리를 구해야 하며 이는 X가 범주형, 연속형 일 경우 방법이 서로 다릅니다.
X가 범주형일 경우 Hamming Distance를 사용합니다.
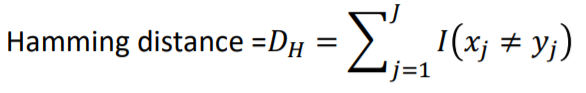
간단하게 말해서 X1의 데이터가 서로 같은 범주 일 경우 0, 서로 다른 경우 1로 두어 다른 범주의 갯수의 합을 거리로 구하는 방법입니다.
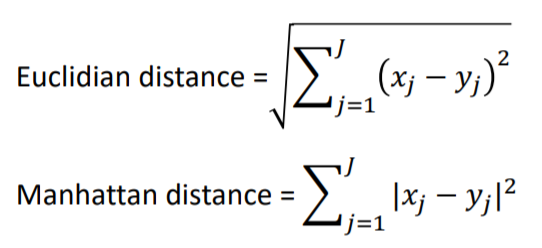
연속형인 경우 유클리드 거리, 맨하탄 거리를 사용하는데 간단하게 말해 직선으로 이은 거리와 XY축을 따라 이동한 거리입니다.
2. 모델의 정의 및 추정


모델을 정의하는 방법은 무척 간단합니다.
각 관측치 사이의 거리를 가까운 순으로 내림차순으로 정렬 한 후 Y가 범주형일 경우 가장 많은 갯수를 가진 범주로, 연속형일 경우 거리의 평균을 계산합니다.
k로 나누어 주는 것은 특정 데이터가 많을 경우를 대비하여 k개로 다시 나누어주어 wight를 부가하는 것 입니다.
3. Cross-validation
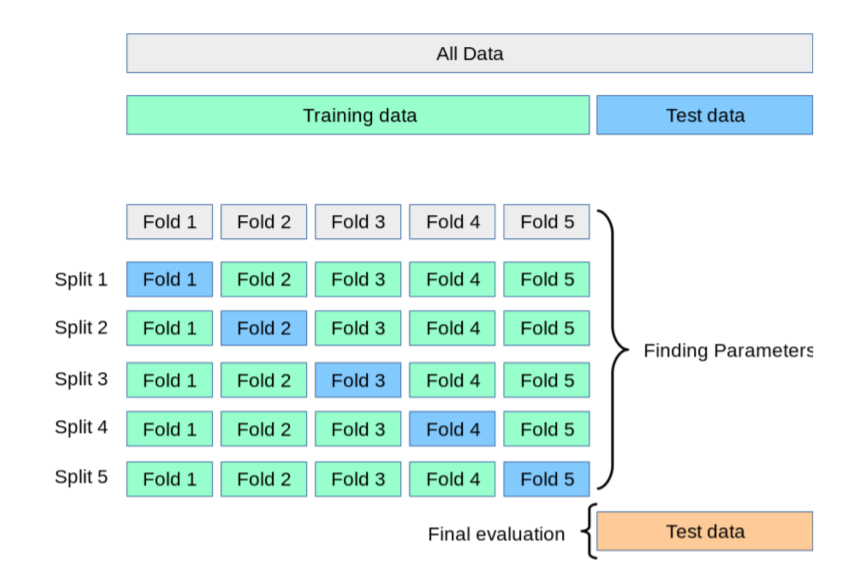
test set은 기존의 train set에서 데이터를 나누어야 하기 때문에 쪼개준 test set만큼 데이터가 소실되게 됩니다.
또한 그렇다고 k를 너무 작게 잡게 되면 error를 과소추정 하기 때문에 overfitting이 일어나기 쉽습니다.
그렇기 때문에 error를 과소추정하지 않으면서 데이터의 소실을 최소한으로 하는 방법이 Cross-validation입니다.
위 그림은 5-fold cross-validation을 하는 방법으로 전체 데이터를 5개로 나누고 각각의 Fold를 test set으로 하며 error를 구하는 방법입니다.
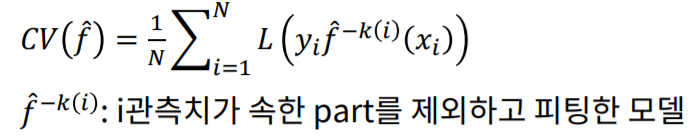
이렇게 구한 CV error 의 평균을 구한 값이 k-fold CV의 error값이 되게 됩니다.
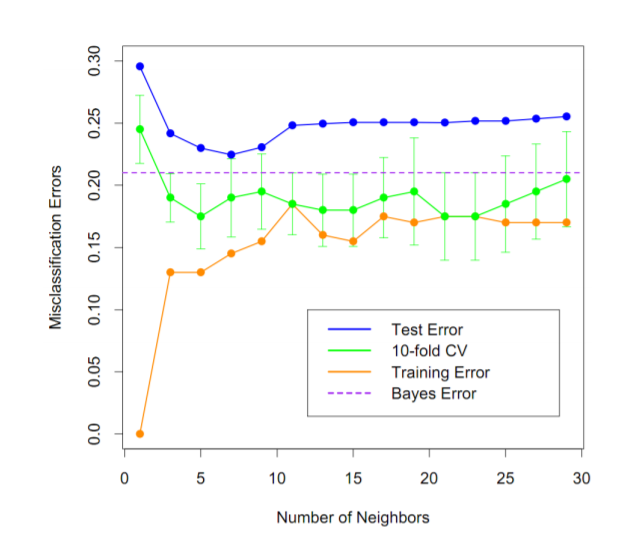
CV error는 test error 보다 낮으며 기존의 error, Bayes error와 보다 유사한 값을 가지게 됩니다.
k-fold CV에서의 k값은 데이터의 사이즈를 보며 사용자가 직접 설정하면 되며 이렇게 구해진 CV error를 KNN의 k별로 비교하여 최적의 k를 찾게 됩니다.
마치며
이번 포스팅에서는 KNN에 관해 알아보았습니다. 데이터 간에 거리를 사용하며 k를 직접 설정해 주어야 하지만 최적의 k를 찾기 위해 CV를 이용하는 과정을 중심으로 이해하면 될 것 입니다.