
MachineLearning의 개념과 종류
1. Machine Learning이란?
- 머신러닝(Machine Learning)이란 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야 입니다.

- 주어진 데이터를 통해 입력변수(X)와 출력변수(Y)사이의 관계를 만드는 함수 f를 만드는 것 입니다.
2. 지도학습과 비 지도학습, 그리고 강화학습
2.1 지도학습(supervised learning)
지도학습은 입력변수 X와 출력변수 Y 의 관계를 모델링 하는 학습입니다.- 또한 크게 회귀(regression)와 분류(classification)으로 분류됩니다.
- 회귀(regression) : 출력변수 Y가 연속변수(continuous)할 때 사용됩니다.
- 분류(classification) : 출력변수 Y가 이산형 변수(discrete)일 때 사용됩니다.
2.2 비지도학습(unsupervised learning)
- 출력변수 Y가 존재하지 않고, 입력변수 X간의 관계에 대해 모델링 하는 학습입니다.
- 비지도학습에는
군집분석과PCA등이 있습니다.
- 군집분석 : 유사한 입력변수(X)끼리 그룹화
- PCA : 독립변수들 사이의 차원을 최소화
2.3 강화학습(reinforcement learning)
- action을 통해 reward를 받으며 이 reward가 최대가 되도록 학습하는 방식입니다.
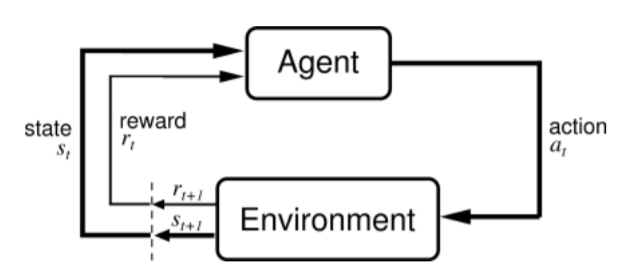
- 대표적으로 알파고가 강화학습을 이용합니다.
3. Machine Learning 의 종류
3.1 선형 회귀분석(Linear Regression)
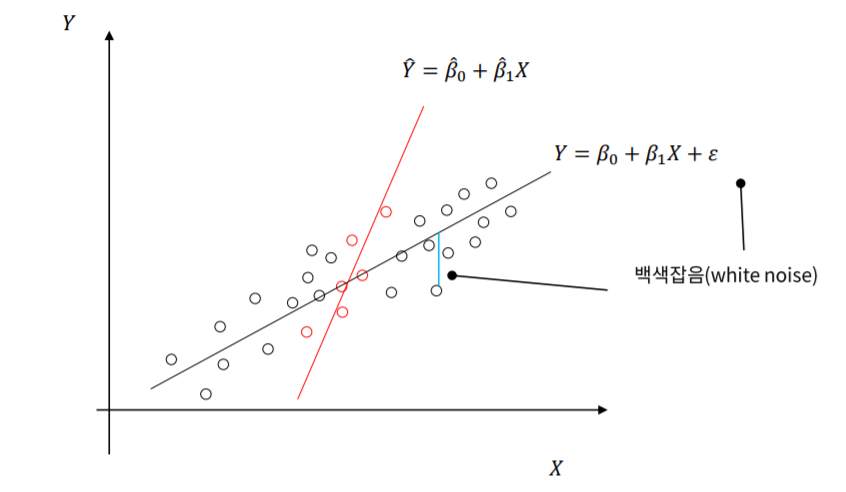
- 입력변수(X)와 출력변수(Y)가 선형적인 관계가 있다고 가정하여 분석합니다.
3.2 의사결정나무(Decision Tree)
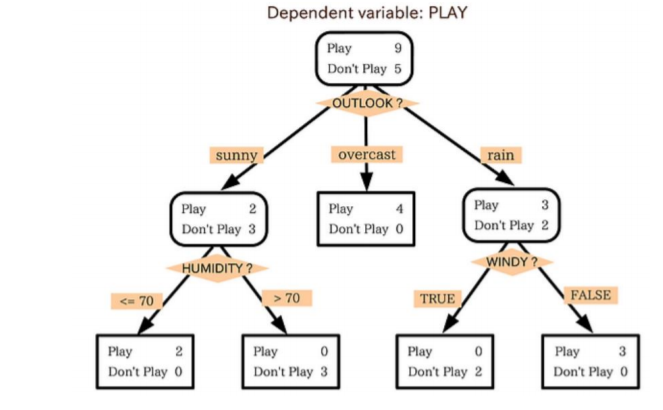
- 독립변수(입력변수)의 조건에 따라 종속변수(출력변수)를 분리합니다.
- 간단하고 이해하기 쉬우나 overfitting이 잘 일어납니다.
3.3 KNN(K - Nearest Neighbor)
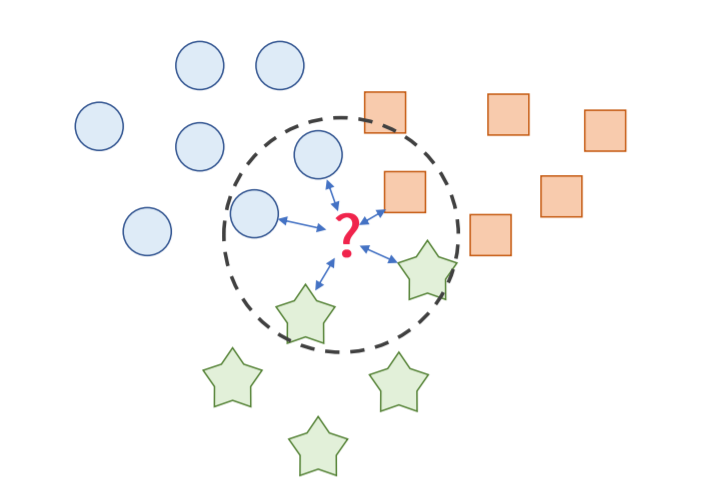
- 새로들어온 데이터의 주변 k개의 데이터로 분류하는 기법입니다.
- k값은 직접 설정해 주어야 합니다.
3.4 Neural Network
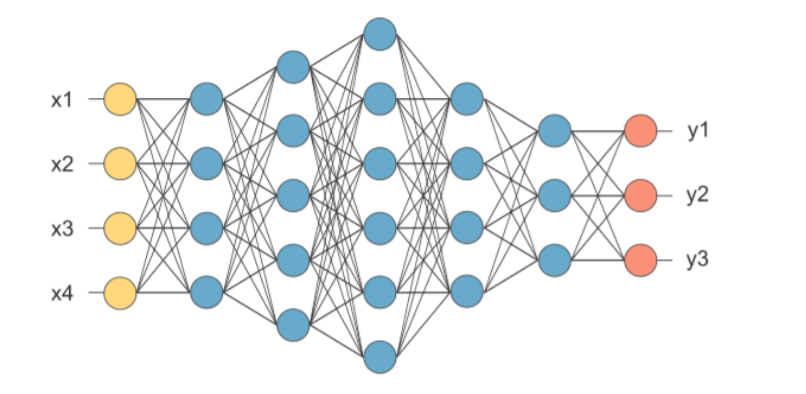
- 입력, 은닉, 출력 층으로 구분하여 각 층을 연결하는 노드의 가중치를 업데이트 하면서 학습합니다.
3.5 SVM ( Support Vector Machine)
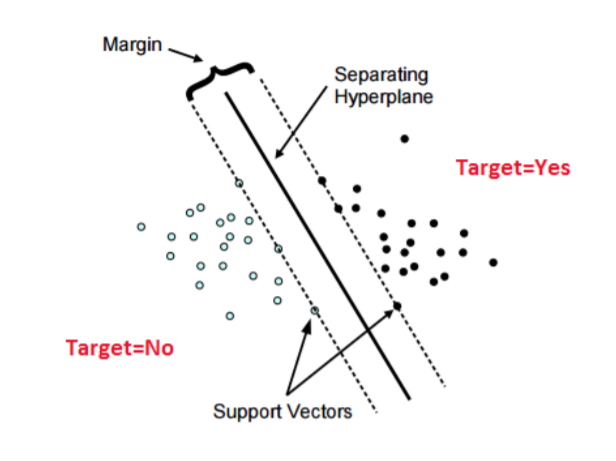
- Class 간의 거리가 최대로 되도록 decision boundry를 설정하는 방법입니다.
3.6 Ensemble Learning
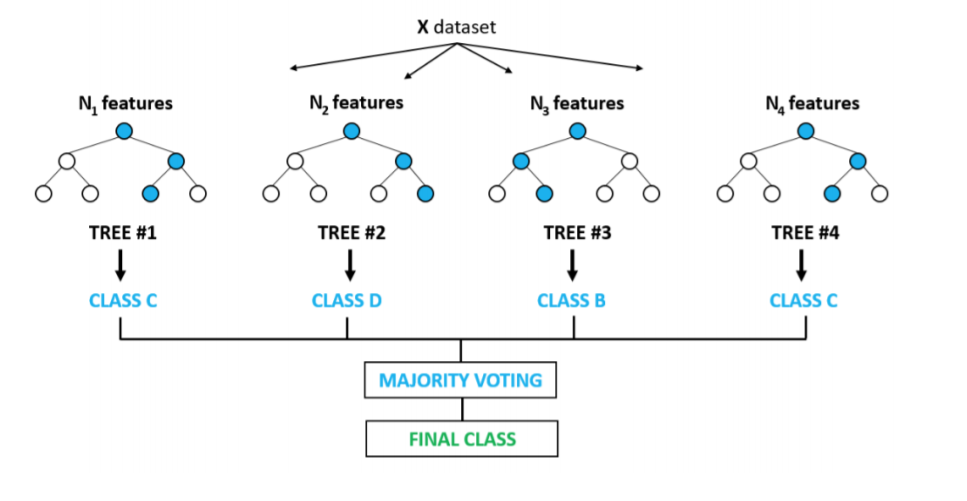
- 여러개의 모델을 결합하여 사용하는 모델입니다.
3.7 K-means Clustering
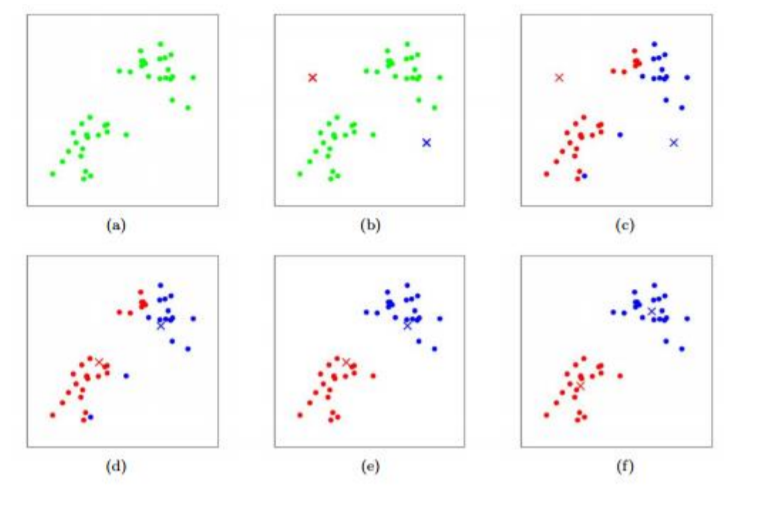
- Lable없이 데이터의 군집을 K개 생성합니다.
4. Deep Learning
- Deep Learning은 다층의 Layer를 활용하여 보다 복잡한 데이터의 활용이 가능합니다.
- 그렇기 때문에 기존의 회귀, 분류와 같은 저차원적인 모델에서 이미지, 텍스트 등 보다 복잡한 차원의 데이터를 분석하는 것이 가능해졌습니다.
- 이러한 Deep Learning의 성능을 보다 향상시키기 위해 사용하는 기술이
GAN과강화학습(Reinforcement Learning)입니다. GAN은 data를 만들어내는 Generater와 data를 평가하는 Discriminator가 서로 대립하며 학습하여 성능을 개선시키는 방법입니다.- 즉, Generator는 Discriminator가 실제 data인지 만들어낸 data인지 모르도록 학습하고 Discriminator는 이러한 데이터를 구분하도록 학습시킵니다.
4. Overfitting (과적합)
Decision tree에서도 잠시 나왔던Overfitting입니다.- 간단히 요약하면 test case에 너무 최적화 되어 실제 데이터에 적합하지 못한 상태를 말합니다.
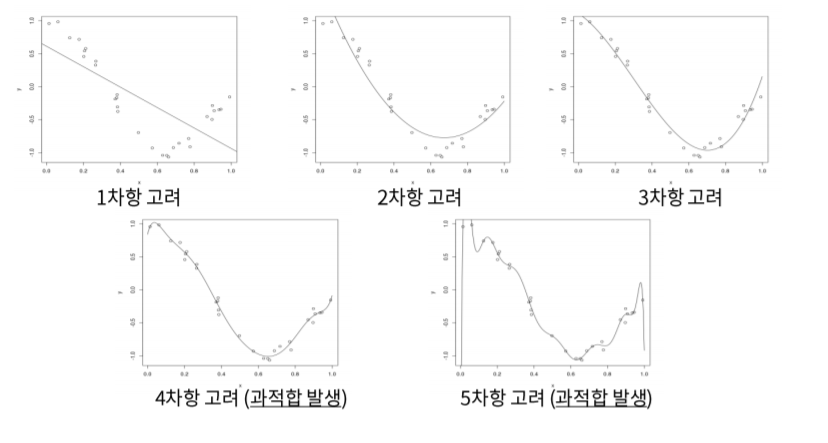
- 위의 사진에서처럼 4차항 고려와 5차항 고려가 과적합 상태입니다.
- 위의 모델에서는 3차항까지 고려한 모델이 최접합 상태입니다.
4. MSE(Mean Squared Error)
- 간단히 말해 데이터와 예측된 모델사이의 총 차이입니다.
- MSE는 Variance(분산)과 Bais(편파) 그리고 Irreduciable error(어쩔수 없는 에러)로 구성되어있습니다.
- 따라서 우리는 모델을 설계할때 Variance가 작고 Bais 도 작은 모델을 목표로 설계해야합니다.
- 하지만 이러한 이상적인 모델은 거의 존재하지 않습니다.
- 그렇기 때문에 적절한 모델을 찾는 것이 어려우며 일반적인 경우 적당히 Variance가 높더라도 Bais가 낮은 모델을 선택합니다.
마치며
이번 포스팅은 Machine Learning에 관해 간략히 포스팅 해보았습니다. ML은 이론적인 부분이 많고 복잡한 내용이 많아 첫 포스팅은 최대한 간략하게, 개념위주로 적어보았습니다.