
Python 기초 라이브러리 2
1. Pandas란?
-
Pandas란 python data analysis의 약자입니다.
-
pandas는 정형 데이터 처리에 특화되어 있습니다.
간단하게 말하면 python에서 excel의 기능을 사용할 수 있습니다.
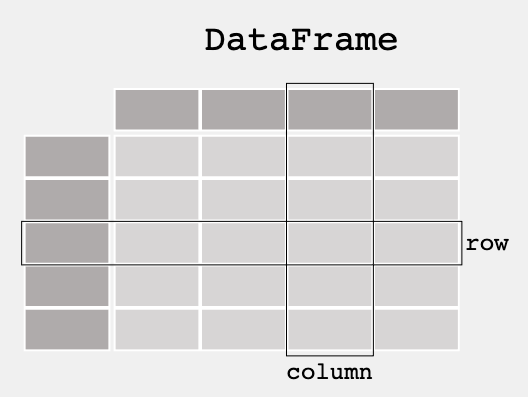
-
pandas에서 기본적으로 데이터를 다루는 단위인 DataFrame입니다. 흔히 알고있는 spread sheet와 같은 개념입니다.
-
이러한 형태의 데이터를 정형 데이터(structured data), tabular data 등으로 부릅니다.
-
DataFrame에서 row를 한줄, 혹은 column을 한줄 떼어낸 것을 Series라고 합니다.
-
pandas를 활용하면 많은 형식의 정형데이터를 읽어들이고 가공하여 또 다시 다양한 형태의 정형 데이터로 저장 할 수 있습니다.

2. Pandas 사용법
- 라이브러리를 불러오는 방법은 다음과 같습니다.
import numpy as np
import pandas as pd
- pandas의 기본 자료 구조는 Series 와 DataFrame입니다.
- 위에서 설명 했듯이 Series는 DataFrame의 한 rows 혹은 column이며 Series의 모임이 DataFrame입니다.
# s는 1, 3, 5, np.nan, 6, 8을 원소로 가지는 pandas.Series 입니다.
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)
# 6x4 행렬에 -1에서 1 사이의 랜덤한 숫자를 가지는 원소를 가지고, index열은 dates, 나머지 coulmns은 순서대로 A, B, C, D로 하는 DataFrame 생성 합니다.
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) #첫번째 인자는 values, 그 후 index랑 columns를 정해줄 수 있습니다.
print(df)
3. DataFrame의 기초 method
# dataframe의 맨 위 다섯줄을 보여주는 head()
df.head()
df.head(3) # 숫자를 지정해서 지정된 숫자만큼만 보여주는 기능도 가능합니다.
# dataframe의 맨 뒤 다섯줄을 보여주는 tail()
df.tail()
# dataframe의 index만을 보여주는 index
df.index
# dataframe의 column을 보여주는 column
df.column
df.column[3] # 이와같이 특정 값을 가져오는 것도 가능합니다.
# dataframe의 values만을 보여주는 values
df.values
# dataframe에 대한 전체적인 요약정보를 보여줍니다. index, columns, null/not-null/dtype/memory usage가 표시됩니다.
df.info() #index, column순으로 정보를 보여줍니다.
# dataframe에 대한 전체적인 통계정보를 보여줍니다.
df.describe()
# column B를 기준으로 내림차순 정렬
df.sort_values(by='B', ascending=False).head(3) #B를 기준으로 내림차순으로 정렬하고 값이 가장큰 top 3
4. DataFrame indexing
# pandas dataframe은 column 이름을 이용하여 기본적인 Indexing이 가능합니다.
# column A를 indexing
df["A"] #dataframe에 바로 indexing을 사용하면, column을 찾습니다. dict의 indexing와 같습니다.
# == "key"를 indexing. == "key" == "column"
#df["2021-01-01"] #이렇게 사용하면 key error가 발생합니다.
# 특정날짜를 통한 Indexing, index의 이름을 알 경우 다음과 같이 호출합니다.
df.loc["2021-01-01"] #pd.Series datafram은 한줄만 뜯어내면 무조건 Series 입니다.
# 특정 위치를 통한 indexing, index의 이름을 모르더라고 위치를 알고 있다면 다음과 같이 호출합니다.
df.iloc[2]
# slicing의 경우 index값을 기준으로 slice됩니다.
df[:3] # 앞에서 3줄의 rows를 가져옵니다.
# df에서 index value를 기준으로 indexing도 가능합니다. (여전히 row 단위)
# 20210102부터 20210104까지 잘라봅니다.
df['2021-01-02':'2021-01-04']
# df.loc에 2차원 indexing도 가능합니다. [:, ["A", "B"]]의 의미는 모든 row에 대해서 columns는 A, B만 가져오라는 의미입니다.
df.loc[:,["A", "B"]] #dataframe에서 2차원 indexing 할때, column들은 리스트로 넘겨 줄 수 있습니다.
# pandas는 fancy indexing을 지원합니다. (사실 numpy에서 지원하기 때문에 pandas도 지원합니다.)
# fancy indexing이란 조건문을 통해 indexing을 할 수 있는 방법으로 True와 False를 원소로 하는 리스트를 통해 masking하는 원리로 동작합니다.
# column A에 있는 원소들중에 0보다 큰 데이터를 가져옵니다.
df > 0 #masking
#df.A > 0 #이러한 형식도 가능합니다.
df['A'] > 0
df[df['A'] > 0]
df[df > 0] #전체 vales중에서 조건에 맞지 않는 애들은 전부 nan이 되어 버립니다.
#chain indexing
df['A'][df['A'] > 0] #A에 대해서 fancy 구문이 맞는 것만 출력합니다.
# dataframe은 dictionary와 비슷한 방식으로 assignment가 가능합니다.
# df에 ['one', 'one','two','three','four','three'] 리스트를 column의 value로 하는 column E를 추가합니다.
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three'] #dict에 추가하듯이 추가할 수 있습니다., 이미 colume E 가 존재한다면 update.
df2
5. 외부 데이터 읽고 쓰기
# 외부 데이터 또한 불러 올 수 있습니다..
# 확장자에 따라 부르는 법이 조금씩 다릅니다. 옵션또한 조금 다르며 이건 csv불러오는 방법입니다.
data = pd.read_csv(path)
# 바꾼 Dataframe을 저장하는 방법입니다.
data.to_csv(path)
- pandas를 사용한다면 여러 확장자의 정형데이터를 읽어들이고 가공 할 수 있습니다.
마치며
이번 포스팅에서는 pandas에 대해 알아보았습니다. 이번 포스팅또한 간단한 사용법과 개념에 대해 설명하였으나 numpy와 pandas는 개념은 간략하게 이해하고 직접 데이터를 다뤄 보는 것이 중요하다고 생각합니다. 데이터 분석에는 이 두가지 라이브러리 이외에도 seaborn과 같은 시각화 라이브러리 등 다양한 라이브러리의 사용이 가능하지만 이 이후는 직접 데이터를 다루었던 예시를 보면서 학습해 보는 것이 좋다고 생각합니다.