
데이터 분석 파이프라인 구축 - EMR, Zeppelin
시작하기에 앞서
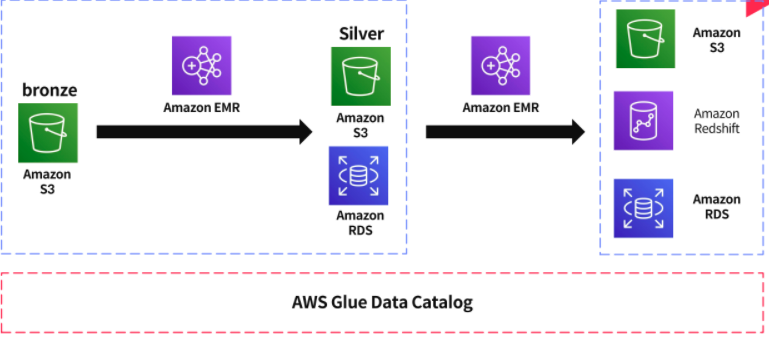
시작하기에 앞서 이번 포스팅에서 사용할 Bronze, Silver, Gold 데이터 라는 용어를 정의하겠습니다.
Bronze 데이터는 kinesis를 거쳐서 S3에 저장한 raw-data라고 하겠습니다.
Silver 데이터는 이렇게 수집된 Bronze 데이터를 가공하기 편한 적당한 형식으로 변환한 데이터 라고 하겠습니다.
예를 들자면 text형태로 들어온 Bronze 데이터를 JSON 파일로 변환 하는 식의 변환입니다.
Gold 데이터는 각 customer의 용도에 맞춰 가공한 데이터 라고 하겠습니다.
1. 구조
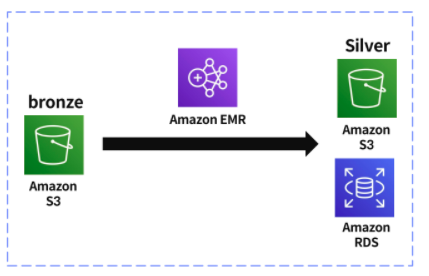
이번에 실습할 구조는 위와 같습니다.
S3로 부터 Bronze 데이터를 받아와 파일 형식을 변경하고 Silver 데이터로서 RDBMS 에 저장하는 구조입니다.
2. EMR
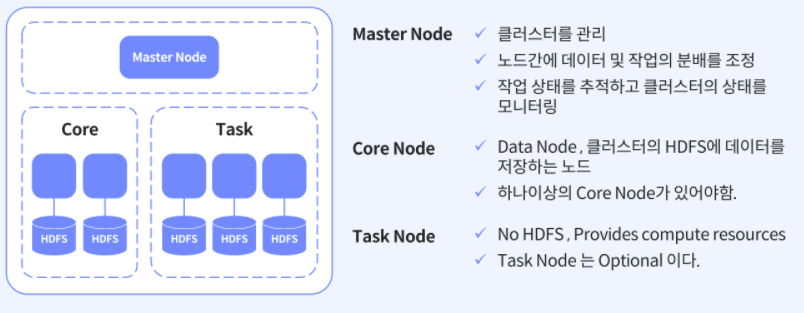
이번 포스팅에서 몇번이나 등장한 EMR에 대해 알아보려고 합니다.
EMR은 AWS에서 Apache 하둡 및 Apache Spark와 같은 빅 데이터 프레임워크 실행을 간소화 해주는 관리형 클러스터 플랫폼 입니다.
간단히 말하면 하둡, Spark이외에도 여러가지 어플리케이션을 사용하기 위해선 가상환경을 구축하고 설치하는 과정이 필요하지만 이 과정을 단순화 시켜주는 AWS 서비스 입니다.
크게 Master Node, Core Node, Task Node로 구성되어 있으며 각자의 역할이 다르게 설정되어 있습니다.
여기서 말하는 HDFS는 데이터를 저장하는 공간으로 저희는 이번 실습에서 S3를 사용합니다.
3. Zeppelin notebook
쉽게 말해 Anaconda의 Jupyter notebook과 같은 역할을 합니다.
브라우저에서 Python, Scala, R, SQL 등의 다양한 언어를 섞어가며 분석 코드를 표현 할 수 있습니다.
또한 실행하여 바로 결과를 볼 수 있어 데이터를 확인하거나 시각화 또한 할 수 있습니다.
이번 실습에서 S3 에서 데이터를 불러오고 전처리 한 후 RDBMS로 보내는 코드를 이 Zeppelin notebook에서 작성 할 예정입니다.
4.1 EMR 설정
- 가장 먼저 AWS 서비스 중 EMR을 선택한 후 클러스터 생성, 고급 옵션으로 이동을 선택해 줍시다.
- 저희가 앞으로 사용할 소프트웨어 입니다. 선택해 줍시다.
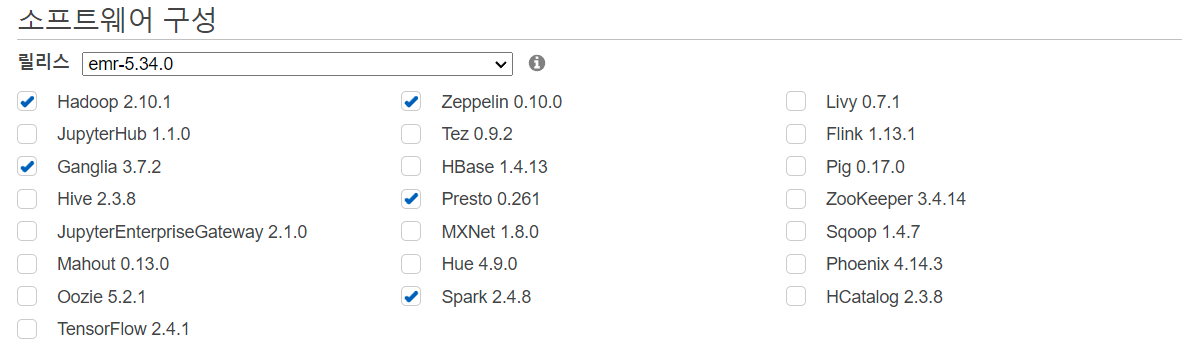
- 다음 버튼을 누룬 후 다음 과 같이 노드와 인스턴스 설정을 해줍니다.
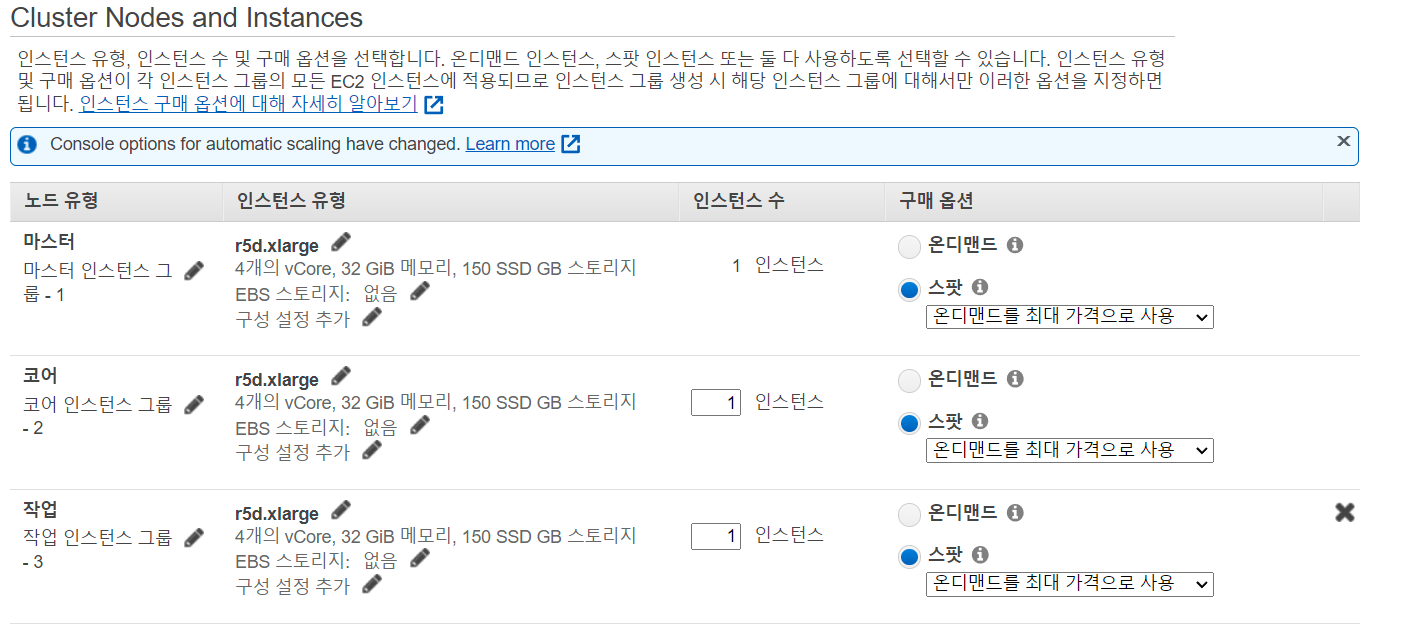
r5d.xlarge를 선택한 이유는 r 시리즈가 메모리 특화인 것과 ssd를 이용해 좀 더 빠른 속도를 사용하기 위함 입니다.
스팟의 경우 실습용이기 때문에 더 과도한 비용이 부과되지 않도록 온디멘드를 최대 가격으로 설정해 놓았습니다. - 다음 버튼을 누룬 후 클러스트 이름을 class-master, 태그에 Name, datapipeline이라고 설정해 주었습니다.
- 다음 버튼을 누룬 후 첫 EC2를 생성할 때 사용한 key pair를 그대로 사용하며 최종적으로 클러스터 생성과정을 마치시면 됩니다.
클러스터가 생성되기까지 대략 10분 정도의 시간이 필요합니다.
만약 클러스터가 대기중 상태가 되었다면 제대로 생성이 완료 된 것 입니다.
EC2서비스로 입장해 인스턴스를 확인해 보면 Master Node, Core Node, Task Node 가 설정한 대로 1개씩 인스턴스가 생성되어 있는 것을 확인 할 수도 있습니다.
4.1.1 EMR 보안그룹 설정

EMR이 대기중 상태라면 클릭하여 위와 같은 마스터 보안 그룹을 찾습니다.
설명 란이 master group for… 으로 되어 있는 보안그룹을 체크 한 후 아래 인바운드 규칙 편집 버튼을 클릭합니다.

이후 위와 같은 규칙을 추가 해 줍니다.
모든 IP에 대해 모든 포트를 열어두는 것은 무척 보안상 위험한 작업이기에 평소에는 자신의 IP만 접속 하도록 IP 제한을 해두는 것이 바람직 합니다.
이번 실습에서는 Zeppelin notebook에서 편집하는 과정상 외부 IP로 접속하는 과정이 생기기에 일시적으로 보안그룹에 추가해 두었습니다.
4.1.2 Zeppelin notebook 실행해 보기
다시 EMR 클러스터로 돌아와서 어플리케이션 이력을 클릭합니다.
그 중 Zeppelin 의 User interface URL을 확인 할 수 있는데 그 URL을 복사하여 새탭 주소창에 넣고 접속하면 Zeppelin notebook을 실행할 수 있습니다.
4.1.3 Ganglia를 통한 모니터링
마찬가지로 Ganglia의 URL또한 확인 할 수 있습니다.
그 URL을 새탭 주소창에 입력하고 접속하면 EMR의 여러 상태를 모니터링 할 수 있습니다.
4.2 RDS 설정
- AWS 서비스 중
RDS라는 서비스를 찾아 접속한 후 데이터베이스 - 데이터베이스 생성을 클릭합니다. RDS는RDBMS를 구축 할 수 있게 해주는 AWS 서비스 입니다.- 여러가지 엔진을 선택 할 수 있지만 저희는
Amazon Aurora를 사용할 것 입니다.
Amazon Aurora는MySQL및PostgreSQL호환 관계형 데이터베이스(RDBMS) 입니다. - 템플릿은 실습용이기 때문에 개발/테스트 를 선택합니다.
- DB 클러스터 식별자를 myclass를 입력하고 마스터 암호를 자신이 기억하는 암호로 설정해 줍니다.
- 그 후 생성하면 자신의
RDBMS가 구축됩니다.
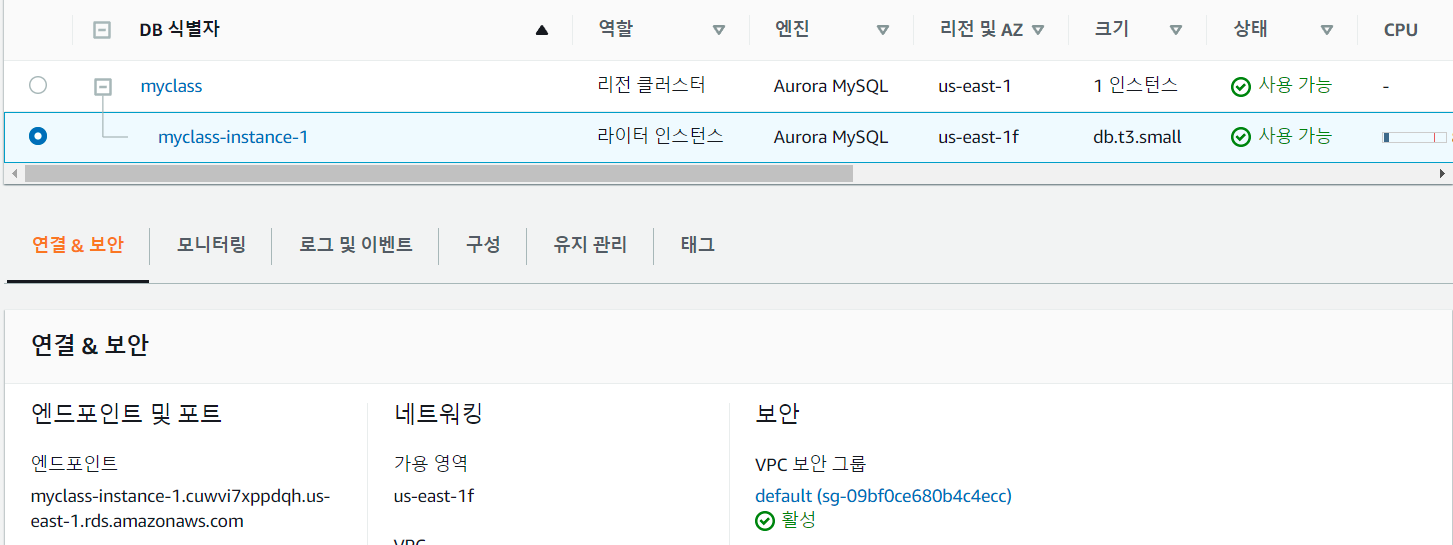
위와 같이 생성된 인스턴스를 클릭하면 엔드포인트 주소를 확인할 수 있으며 이 엔드포인트 주소를 통해 RDBMS에 접속 할 수 있습니다.
저같은 경우 Datagrip이라는 외부 프로그램을 사용하여 이 RDBMS를 관리하며 Zeppelin notebook에서도 이 주소를 통해 접속 할 수 있습니다.
4.3 Zeppeline notebook을 통한 데이터 전처리 및 전송
이 부분의 경우 제가 외부에서 제공받은 데이터와 소스코드를 사용했기 때문에 블로그에 따로 기재하기 힘들 것 같습니다.
Zeppeline notebook의 경우 Scala 언어와 SQL을 이용하여 text 형식의 Bronze 데이터를 JSON 및 Parquet 형식으로 변경하여 RDS에 저장하는 코드를 작성하여 작동하였습니다.
마치며
이번 포스팅에서는 수집한 Bronze 데이터를 S3에 저장하는 것 만이 아닌 저장된 Bronze 데이터를 분석 및 가공하여 Silver 데이터로서 RDBMS에 저장하는 실습을 하였습니다.
비록 데이터를 불러들이고 가공하고 저장하는 부분의 코드는 생략되어 있지만 AWS의 개념과 데이터의 흐름만큼은 이해 될 것 이라고 생각합니다.