
데이터 수집 파이프라인 구축
시작하기에 앞서
저번 포스팅에서는 메세지 큐를 이용하여 파이프라인이 구축되는 것을 확인하였습니다.
이번 포스팅은 데이터를 수집하고 S3에 저장하는 파이프라인을 구축해 보려고 합니다.
1. 구조
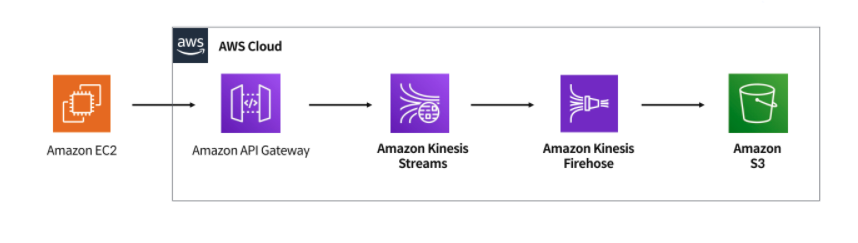
이번 실습에서 구현할 파이프라인 구조입니다.
가상머신인 EC2에서 데이터를 생성하여 최종적으로 S3에 저장하려고 합니다.
2. API gateway
어떤 규모에서든 개발자가 API를 생성, 게시, 유지 관리, 모니터링 및 보호할 수 있게 해주는 AWS 서비스 입니다.
API서버의 앞단에서 모든 API서버들의 엔드포인트를 단일화 해주는 또다른 서버 입니다.
예를 들어, 이번 실습에서는 수집한 데이터를 S3로 보내주는 단일 마이크로 서비스만 구축할 예정이지만 복수의 마이크로 서비스를 운영하는 경우,
각각의 서비스마다 인증 및 인가와 같은 공통된 로직을 구현해야 하는 번거로움이 발생하게 됩니다.
또한 클라이언트 측에서 각각의 서비스에 대한 호출을 해야 하는 등 번거로움이 발생하게 되고 관리 또한 어렵게 됩니다.
이렇게 API Gateway는 공통된 로직을 가지는 인증 및 인가, 요청 절차의 단순화 등의 기능을 가지고 있습니다.
3. Kinesis stream
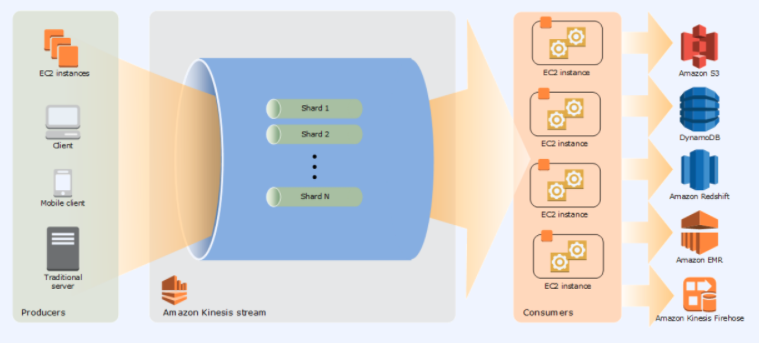
대규모 데이터 레코드 스트림을 실시간으로 수집하고 처리할 수 있습니다.
Shard라는 고유한 데이터 레코드 시퀀스에 데이터를 저장하여 전달하며 이 Shard의 수를 조절하여 속도를 조절 할 수 있습니다.
간단하게 Shard의 수가 많아지면 성능이 좋아집니다.
또한 데이터를 기본 하루까지 저장 할 수 있으며 최대 7일 까지 보존하여 reply를 할 수 있습니다.
4. Kinesis firehose
얼핏 보면 Kinesis stream와 차이점을 알기 어려울 수 있습니다.
Kinesis stream이 데이터를 수집 및 저장 한다면 Kinesis firshose는 데이터의 처리 및 전송하는 역할을 수행합니다.
이번 실습에서는 수집된 데이터를 Kinesis firehose를 통해 S3로 전송 하는 역할을 수행합니다.
5. S3
간단하게 말하자면 저장공간 입니다.
버킷, 객체, 키로 구성되어 있으며 버킷은 저장공간, 객체는 저장되는 기본 매체, 키는 버킷 내 객체의 고유 식별자입니다.
S3를 사용하는 이유는 여러가지 존재하지만 우선 serverless로 운영비용이 감소하고 추가비용을 통해 무한정 용량을 증대 시킬 수 있다는 점 입니다.
6. 구축
6.1 EC2 인스턴스 생성

인스턴스를 생성하는 방법은 저번 포스팅에 설명해 두었으니 위와 같이 인스턴스를 하나 생성해 봅시다.
6.2 API Gateway 설정
AWS 서비스 중 API Gateway를 찾아 접속 한 후 API 생성 버튼을 눌러 줍시다.
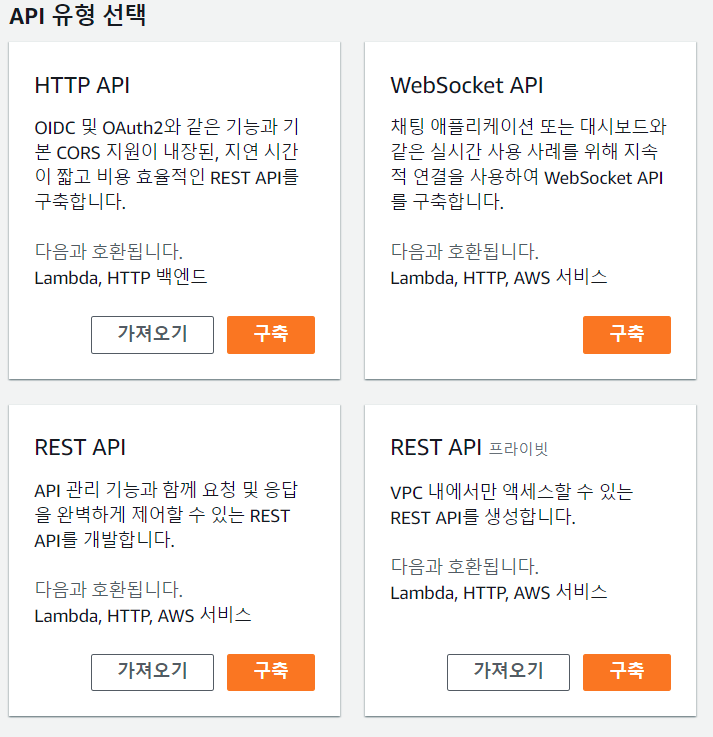
저희가 생성할 유형은 REST API 입니다.
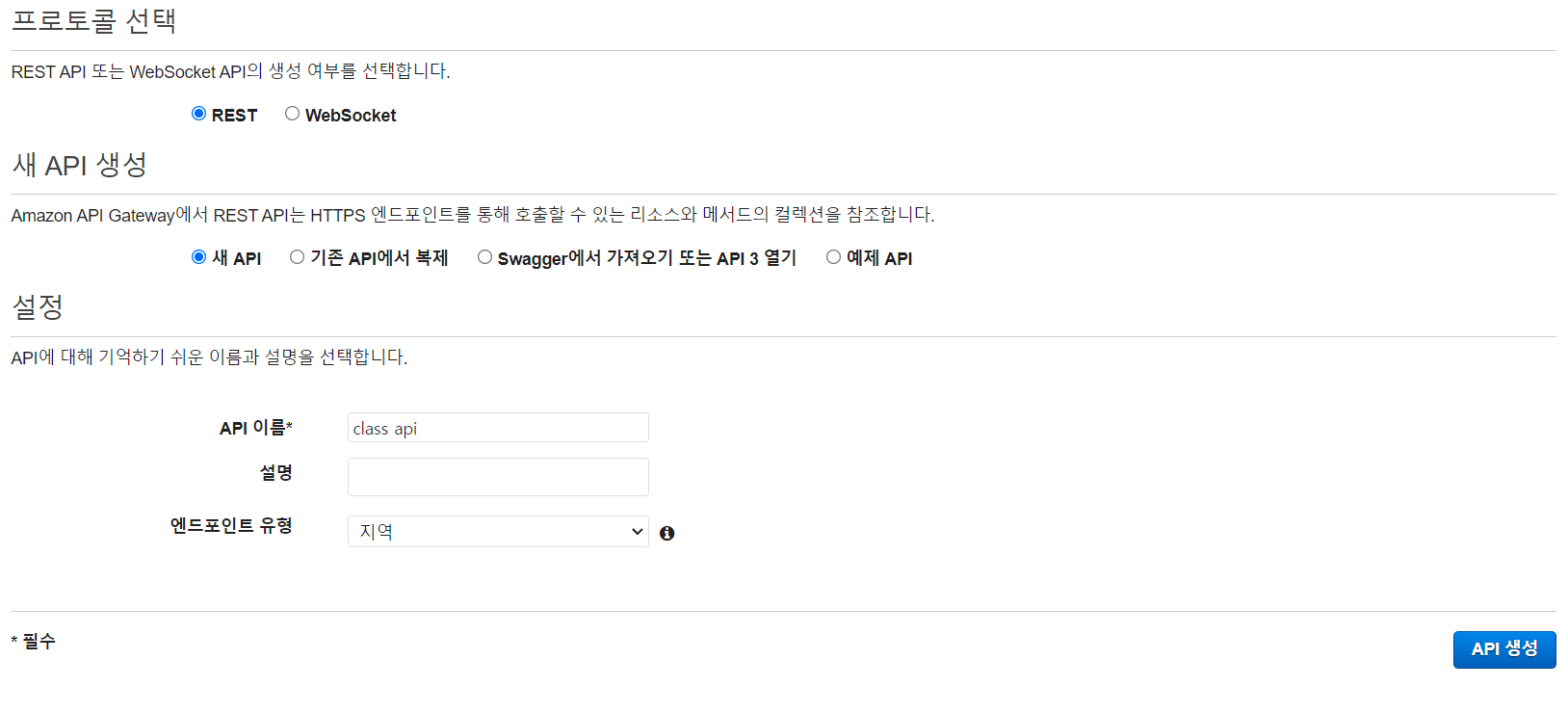
위와 같이 이름만 설정 한 후 간단하게 API를 생성해 줍시다.
그 후 생성된 API를 클릭한 후 리소스를 생성해 보도록 합시다.
작업 토글 버튼을 클릭해 리소스 생성 버튼을 클릭하고 다음과 같이 리소스를 생성합니다.
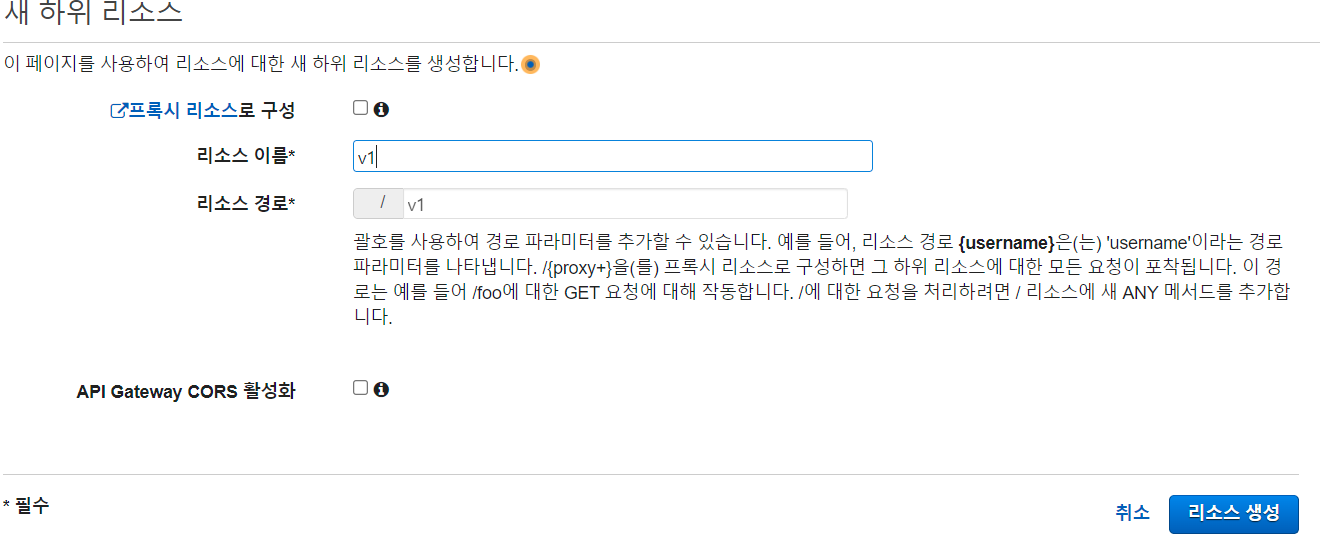
생성된 리소스를 확인 한 후 메소드를 생성해 보도록 합시다. 마찬가지로 작업 토글 버튼을 클릭해 메소드 생성 버튼을 클릭합니다.
이번 실습에서는 POST방식으로 데이터를 전송 할 예정이니 POST를 선택합니다.
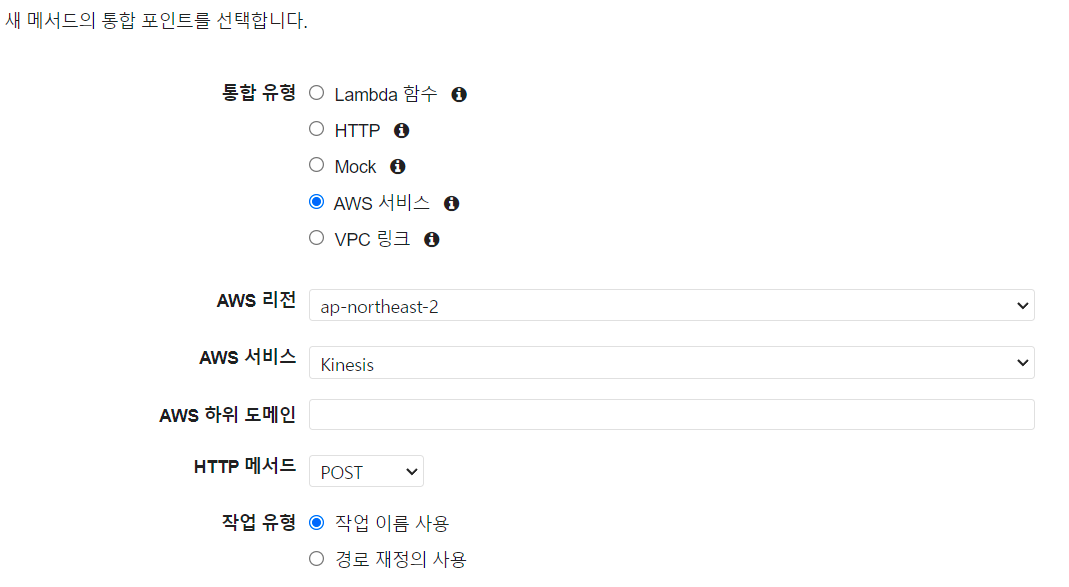
위와 같이 설정을 해줍니다.
저희는 API Gateway를 AWS 서비스인 Kinesis에 연결 해 줄 예정이니 통합유형은 AWS서비스를 선택하였고 리전과 서비스를 선택해 주었습니다.
HTTP 메서드는 마찬가지로 POST입니다.
이제 작업과 역할을 입력해 주어야 합니다.
역할을 입력하기 전에 우선 역할을 생성해주도록 합시다.
현재 탭을 닫지 말고 새로운 탭을 열어 AWS 콘솔을 하나 더 띄워 IAM이라는 서비스를 실행해 보도록 합시다.
6.2.1 IAM 설정
IAM서비스에 왔다면 왼쪽에 역할을 찾을 수 있을 것 입니다.
역할은 말 그대로 어떤 작업을 수행하는 권한 입니다.
저희가 API gateway에 수행할 역할은 gateway에서 kinesis로 데이터를 전송 하는 것 이므로 이 역할을 생성할 것 입니다.
역할 만들기 버튼을 클릭하고 AWS 서비스 중 Kinesis를 찾아 선택합니다.
사용사례로는 Kinesis firehose를 선택합니다. 저희가 Kinesis stream을 kinesis firehose로 연결 할 예정이기 때문입니다.
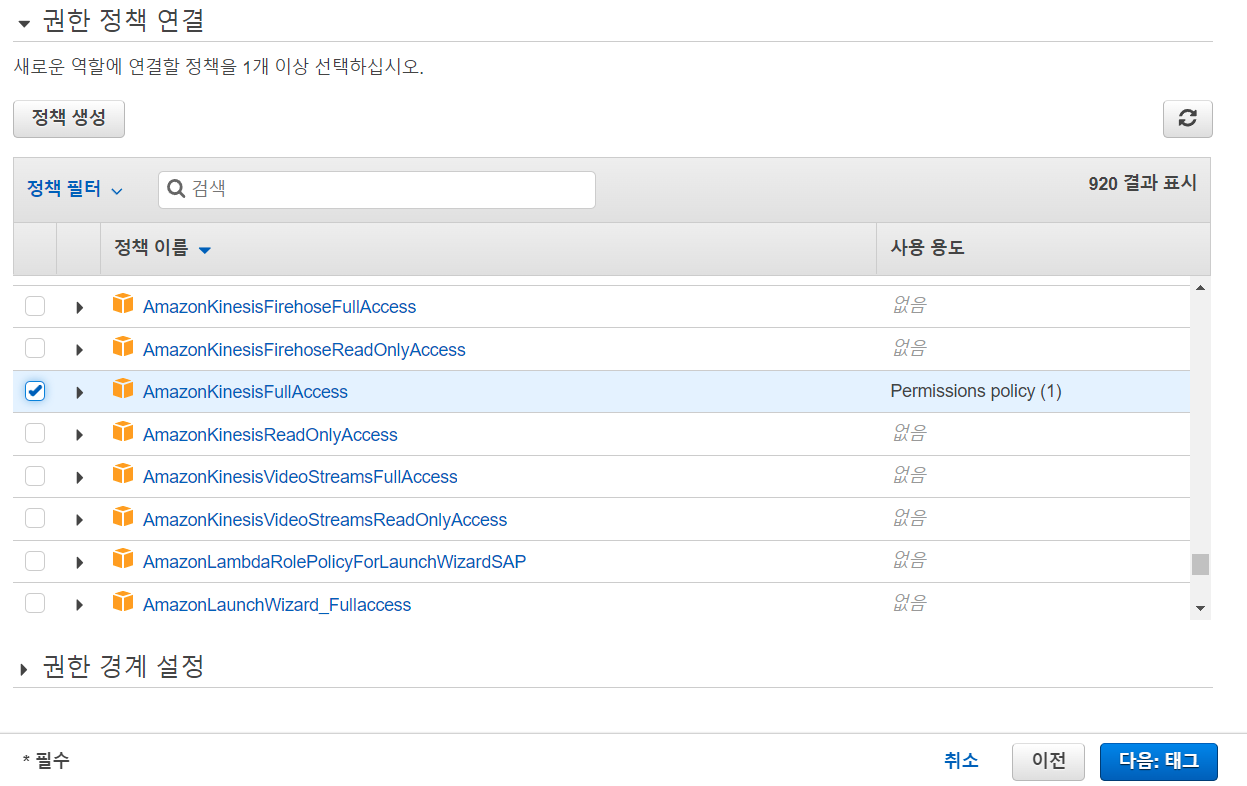
다음은 권한 설정 입니다.
Kinesis를 찾아 Full access권한을 주도록 합시다.
태그는 생성한 역할을 구분하는 중요한 요소입니다. key값에 Name, 값에는 gatewayTokinesis라고 입력하고 역할 생성을 마무리 합니다.
이제 생성된 역할을 클릭하여 ARN주소를 복사합시다.
6.2.2 API gateway 설정으로
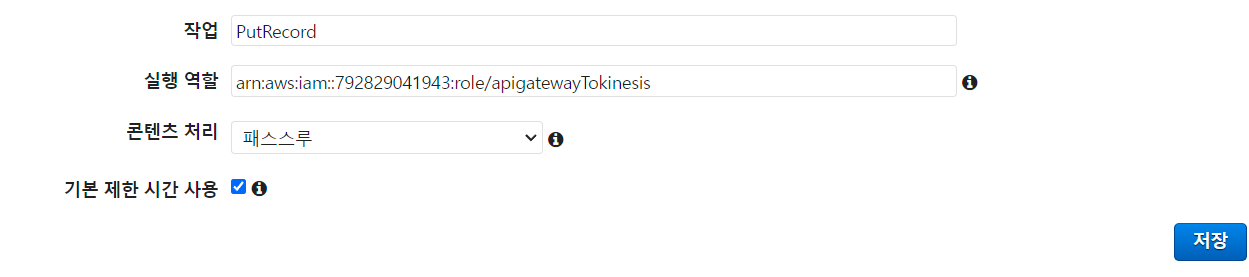
다시 API gateway설정으로 가서 위와 같이 항목을 채워주도록 합시다.
물론 실행 역할에는 복사한 ARN주소를 입력합니다.
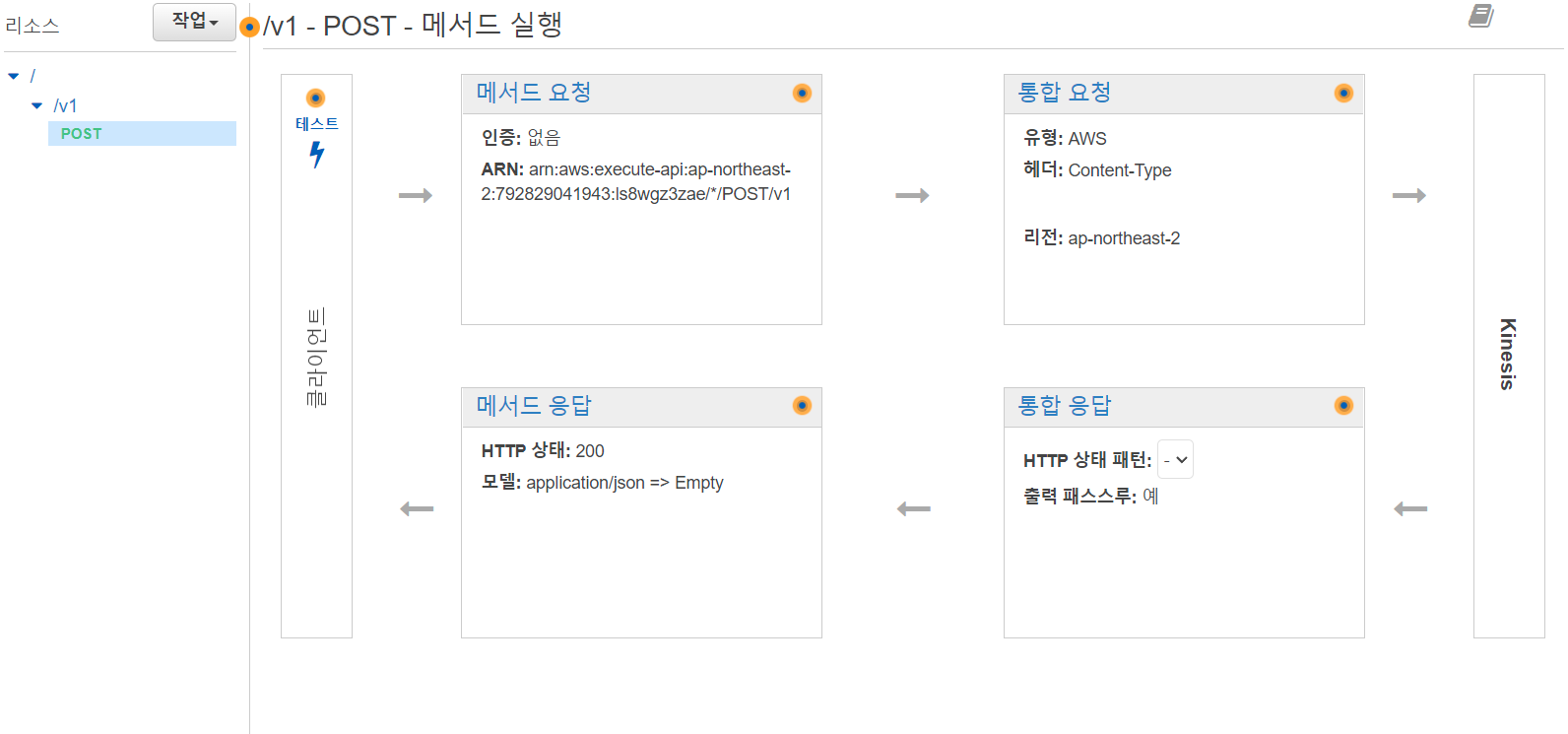
위와 같이 메소드가 생성되었다면 통합요청을 클릭합니다.
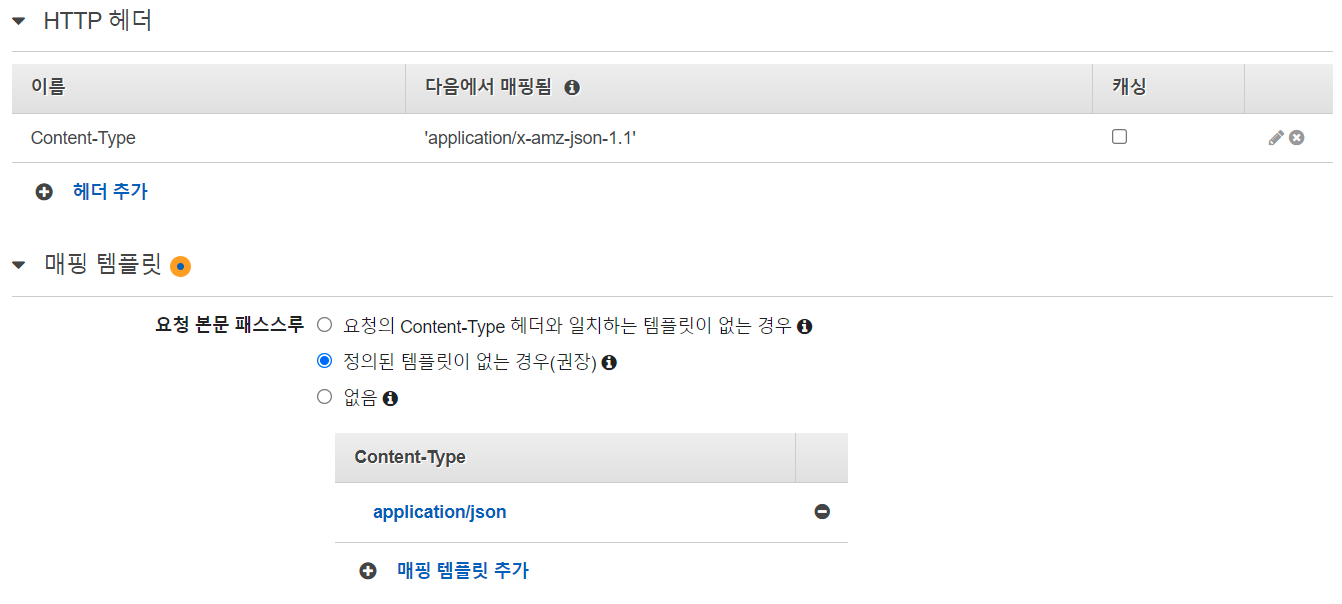
아래 HTTP 헤더와 매핑 탬플릿을 위와 같이 추가해줍니다.
그 후 아래 코드를 탬플릿으로 지정해 줍시다.
#set ( $enter = "
")
#set($json = "$input.json('$')$enter")
{
"Data": "$util.base64Encode("$json")",
"PartitionKey": "$input.params('X-Amzn-Trace-Id')",
"StreamName": "class-stream"
}
간단히 설명하자면 gateway로 받은 데이터를 base64 encoding하고 Data에
key 값을 partitionKey에 StreamName은 Kinesis이름 입니다.
이제 생성된 API를 배포할 순서 입니다.
스테이지 이름을 PROD라고 지정하고 생성해 주면 됩니다.
6.3 Kinesis stream 설정
AWS 서비스 항목에서 Kinesis를 찾아 접속합니다.
바로 데이터 스트림 생성 버튼을 누르고 데이터 스트림을 생성합니다.
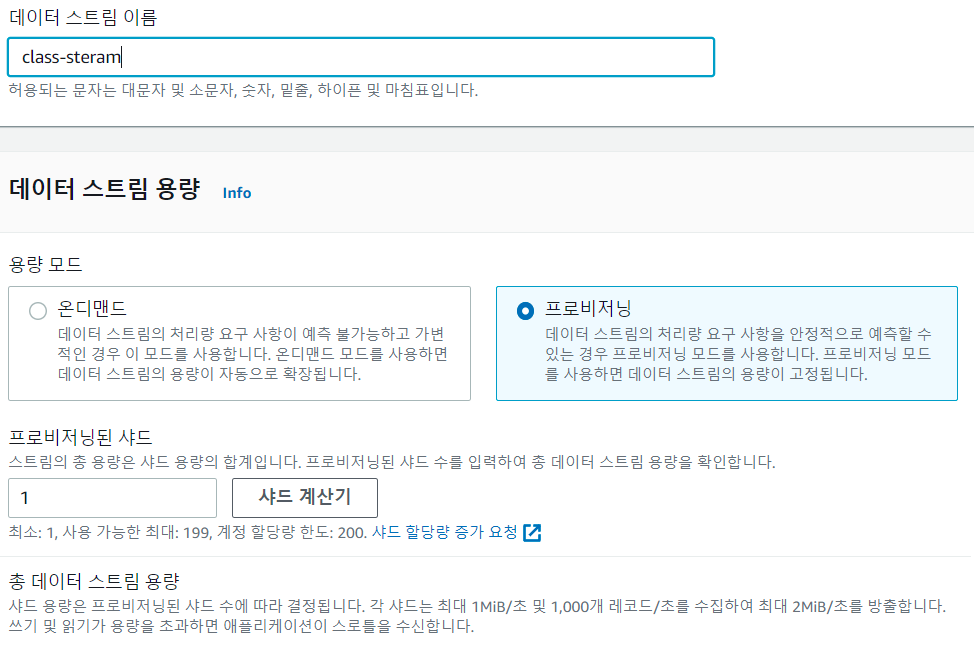
데이터 스트림 이름은 API gateway 메소드 탬플릿 지정 할 때 StreamName으로 넣어준 class-stream으로 지정해 줍니다.
또한 테스트를 위한 stream이기 때문에 Shard 수 또한 1개로 지정 합니다.
6.4 Kinesis firehose 설정
Kinesis stream을 설정 한 후 왼쪽 항목에 전송 스트림 혹은 Delivery stream이라는 항목을 클릭 합니다.
마찬가지로 Create Delivery stream 을 클릭하여 생성하도록 합시다.
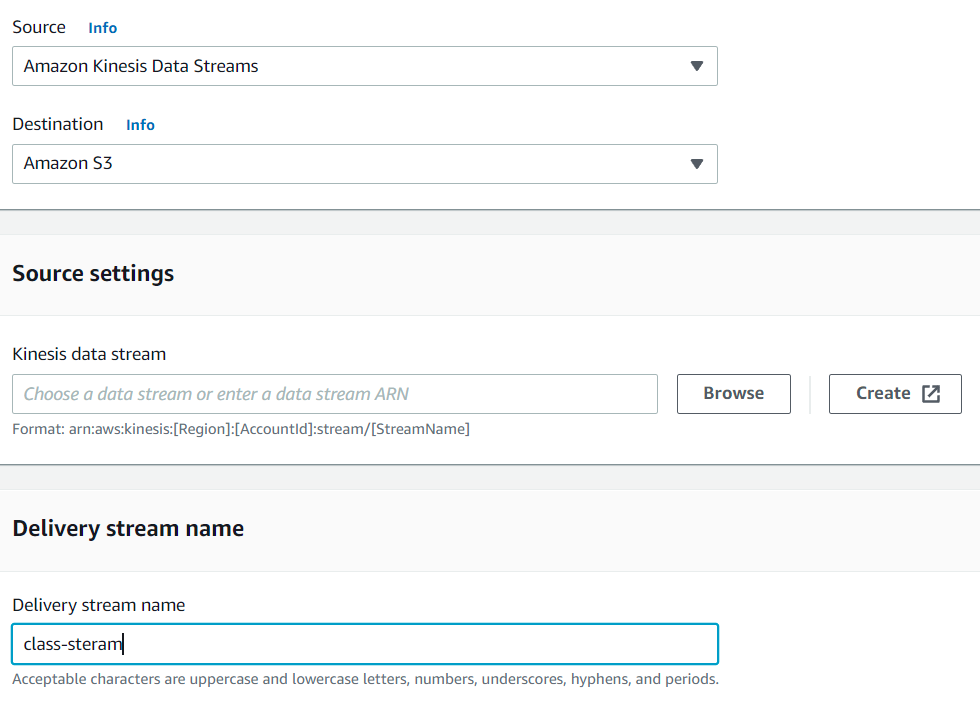
위와 같이 설정을 해 줍니다.
저희는 Kinesis stream으로 부터 데이터를 얻어 S3로 저장할 것이기 때문입니다.
6.4.1 S3 버킷 만들기
아직 firehose설정이 끝나지 않았지만 S3 버킷을 설정해 주어야 하기 때문에 마찬가지로 새 탭을 연 후 AWS 서비스 항목에서 S3를 찾아 접속합니다.
마찬가지로 버킷 만들기를 클릭한 후 이름을 설정해 주시면 됩니다.
여기서 버킷의 이름은 중복 될 수 없기 때문에 자신만의 버킷 이름을 생성해 주시면 됩니다.
6.4.2 다시 firehose 설정

다시 firehose 설정 탭으로 돌아와 생성한 버킷을 불러와 줍니다.
또한 prefix에 raw-data/라고 입력해 주어 firehose를 통해 전달된 데이터가 버킷 내의 raw-data라는 폴더를 생성한 후 그 안에 저장되게 됩니다.
이 때 yyyy/mm/dd 순으로 폴더를 생성하여 저장하게 되는데 이 시간대가 UTC이기 때문에 국내 시간과는 일치하지 않습니다.
이렇게 설정을 마치고 생성을 완료 합니다.
7. 테스트

다시 API gateway로 돌아와 PROD 스테이지로 돌아와 URL을 확인 해야 합니다.
또한 저번 포스팅에서 했듯이 맨 처음에 생성한 EC2 인스턴스에 접속 한 후 아래와 같은 명령어를 입력해 주시기 바랍니다.
curl -d "{\"value\":\"30\",\"type\":\"Tip 3\"}" -H "Content-Type: application/json" -X POST https://ls8wgz3zae.execute-api.ap-northeast-2.amazonaws.com/PROD/v1
여기서 POST 이후에 나오는 주소는 자신의 스테이지 URL을 입력해 주어야 합니다.

위와 같은 sequence number가 출력되었다면 성공적으로 gateway로 데이터를 전송 한 것 입니다.
이제 AWS 서비스의 S3에 접속하여 생성한 버킷의 raw-data폴더에 저장 되어 있는지 확인해 봅니다.
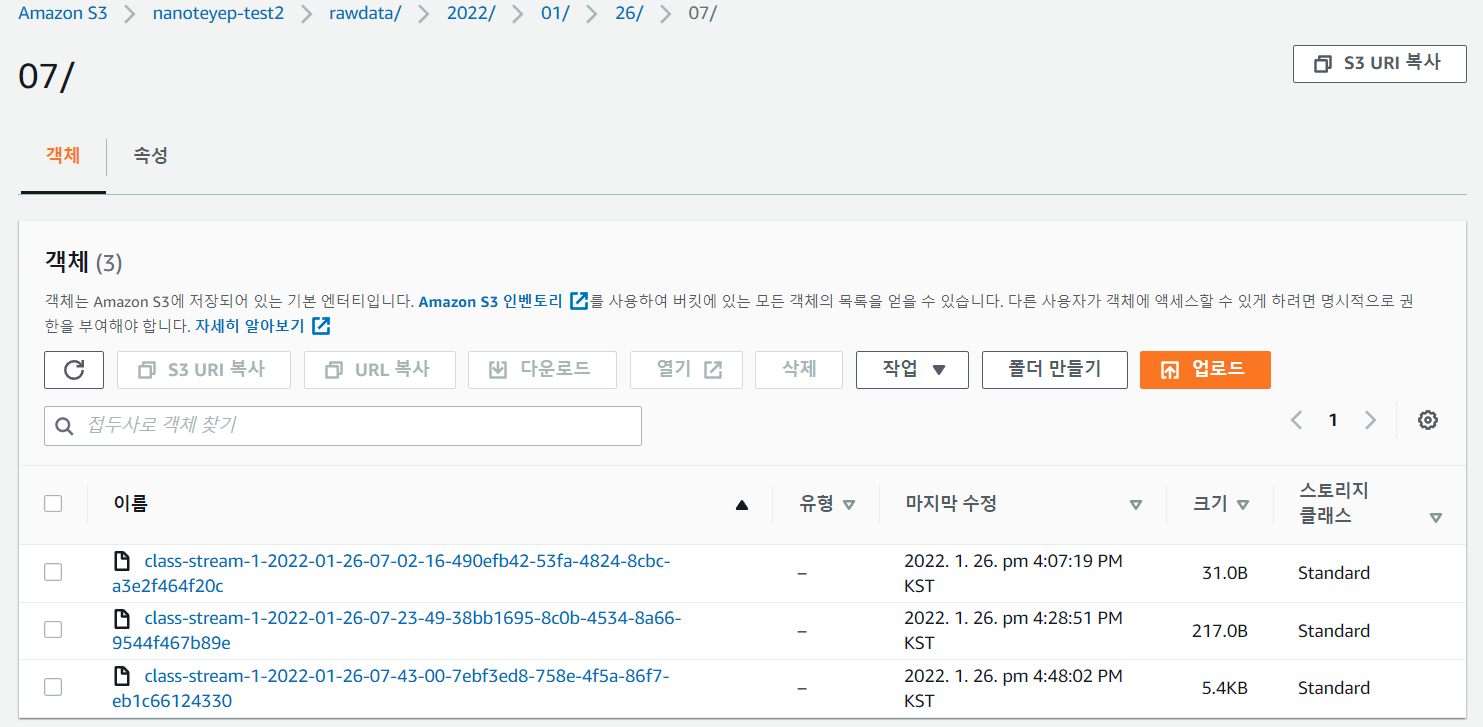
저의 경우 위와 같이 성공적으로 데이터가 저장 된 것을 확인 할 수 있었습니다.
마치며
이번 포스팅은 데이터를 수집하여 저장하는 파이프라인을 구축해 보았습니다.
생성한 EC2의 인스턴스에 자동으로 데이터를 수집하고 API gateway로 보내는 코드를 작성하여 실행 시켜 둔다면 데이터를 수집하여 S3에 저장하는 파이프라인이 생성 될 것 입니다.