
Producer - Queue - Consumer 구조 파이프라인 구축
1. 시작하기에 앞서
이번 포스팅 부터는 Data Engineering에 관한 부분을 포스팅 해보려고 합니다.
그 첫 단계로 AWS를 이용해 데이터 파이프라인을 구축하는 포스팅을 작성하려고 합니다.
2. Pipeline이란?

컴퓨터 과학에서 pipeline이란
한 데이터 처리단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 뜻합니다.
3. Producer - Queue - Consumer 구조
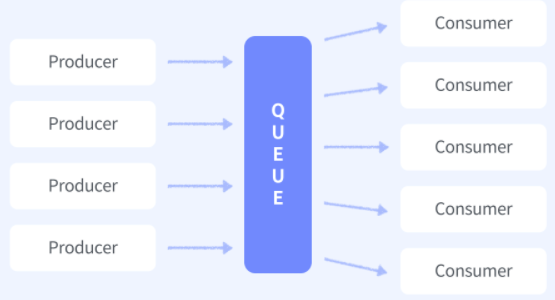
이번에 구축하게 될 pipeline의 구조입니다.
Producer는 메세지를 생산, 즉 데이터를 수집하는 역할을 담당합니다.
Queue는 메세지 큐(Message Queue)를 의미합니다. 간단히 말해 프로그램 사이의 데이터의 송수신방법 입니다.
Consumer는 메세지를 소비하는 주체를 의미합니다. 이번 실습에서는 단순히 메세지를 print하는데서 그치지만 전달된 메세지를 DB에 저장하거나 새로운 구조에 연결하는 등의 역할을 하기도 합니다.
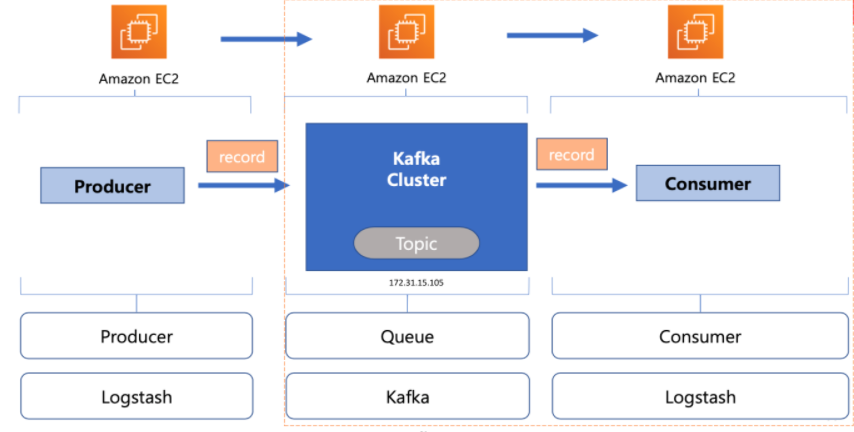
이번 실습의 구성도 입니다.
Amazon EC2는 가상환경입니다. EC2를 이용해 가상환경을 구축하고 그 안에 producer나 queue, consumer역할을 하는 프로그램을 설치할 것 입니다.
Logstash는 다양한 소스로부터 데이터를 수집하고 곧바로 전환하여 대상에 전송하는 경량의 데이터 처리 파이프라인 입니다.
이번 실습에서는 Logstash를 이용해 tweeter데이터를 수집하여 queue로 보내주고 queue로부터 가져오는 역할을 하게 됩니다.
즉, producer와 consumer의 역할을 하게 됩니다.
kafka는 대용량 실시간 로그처리에 특화된 분산형 스트리밍 플랫폼(A distributed streaming platform)입니다.
데이터를 메모리에 저장하는 것이 아닌 파일로 저장하기 때문에 재시작 해도 메시지 유실 우려가 적습니다.
kafka는 이번 실습에서 queue의 역할을 하게 됩니다.
4. 구축
4.1 queue 구축
4.1.1 EC2 - 인스턴스 생성

이번 실습은 AWS를 이용하기 때문에 AWS가입을 마친 후, 서비스 목록에서 컴퓨팅, EC2를 선택해 줍시다.

혹시 리전이 서울이 아니라면 서울로 변경해 주도록 합시다.
이 리전에 따라 인스턴스와 보안그룹 등이 관리되며 지금까지 생성한 인스턴스가 보이지 않는다면 보통 이 리전이 다른 곳으로 설정 된 경우가 많습니다.
인스턴스 시작버튼을 클릭하면 다음과 같은 7가지 과정이 존재합니다.
- AMI선택
가상머신의 이미지를 선택하는 부분입니다. Amazon linux 2 AMI를 선택하고 다음 단계로 가줍니다. - 인스턴스 유형 선택
가상환경의 성능을 선택하는 부분입니다. Logstash를 돌릴 것이기 때문에 t2 medium을 선택하고 다음 단계로 넘어갑시다. - 인스턴스 구성
인스턴스의 세부설정을 선택하는 부분입니다. 따로 설정할 것 없이 다음 단계로 넘어갑시다. - 스토리지 추가
인스턴스의 저장공간을 선택하는 부분입니다. 이번 실습에서는 저장공간을 사용할 일이 없기 때문에 기본인 8GiB 상태로 넘어갑니다. - 태그 추가
인스턴스를 관리하기 위한 태그를 설정하는 부분입니다. 태그 추가 버튼을 누른 후 키에 Name, 값에 kafka-server를 입력한 후 다음 단계로 넘어갑니다. - 보안 그룹 구성
접속을 위한 포트를 설정하는 부분입니다. 여기서는 HTTP 유형의 규칙과 사용자 지정 TCP 유형 규칙을 하나 씩 추가합니다. HTTP는 아마 자동으로 80번 포트가 설정이 되어 있을 것 이며 소스를 위치 무관, 설명에 webpage-test라고 설정합니다.
사용자 지정 TCP 유형 규칙은 kafka를 위한 통로입니다. kafka는 9092번 포트로 통신하기 때문에 포트 범위를 9092로 설정 합니다.
이 후 보안그룹 이름을 자신이 알기 쉽게 설정하면 다음에 또 인스턴스를 생성할 경우 위 보안 그룹을 그대로 다시 사용하기 용이합니다. - 검토 및 시작
지금까지 설정한 내용을 검토하는 부분입니다. 이상이 없다면 인스턴스를 생성해 줍니다.
이 때 key 방식으로 인증을 위한 pem파일을 하나 생성 할 것 입니다. 자신이 구별 가능한 key이름을 설정 한 후 key를 다운로드 받으시길 바랍니다.
이 key또한 region별로 관리 되기 때문에 key이름에 region을 표시하는것이 좋습니다.
4.1.2 kafka 설치
자신이 생성한 인스턴스를 선택한 후 연결 버튼을 누르면 SSH 클라이언트 연결 방식을 찾을 수 있습니다.
cmd, Gitbash등 터미널을 하나 연결하여 자신이 발급받은 key가 존재하는 폴더에 접속합니다.
후에 ssh로 시작하는 명령어를 복사하여 터미널에 실행시키면 ssh를 통해 자신이 생성한 인스턴스에 접속 할 수 있습니다.
먼저, kafka는 java기반으로 돌아가기 때문에 java를 설치해 줍니다.
$ sudo yum install -y java-1.8.0-openjdk-devel.x86_64
이 후 kafka를 다운로드 하고 unzip해줍니다.
$ wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
$ tar xvf kafka_2.13-3.0.0.tgz
다음으로 해주는 작업은 kafka의 버전 관리를 용이하게 해주기 위해 폴더 별 링크를 걸어주는 작업입니다.
$ln -s kafka_2.13-3.0.0 kafka
$cd kafka
zookeeper와 broker를 실행합니다
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties &
$ ./bin/kafka-server-start.sh config/server.properties &
kafka는 9092포트와 2181포트로 작동합니다. 우리가 열어준 포트는 9092지만 둘 다 제대로 작동하는지 확인해 봅니다.
$ sudo netstat -anp | egrep "9092|2181"
이번 작업은 twitter라는 토픽을 생성하는 작업입니다.
$ bin/kafka-topics.sh --create --topic twitter --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 &
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
이제 이 인스턴스는 kafka를 이용해 queue의 역할을 수행할 것 입니다.
다음으로 producer와 consumer를 생성해 queue에 연결해 보도록 하겠습니다.
4.2 producer 구축
4.2.1 EC2 - 인스턴스 생성
인스턴스를 생성하는 방법은 위와 동일합니다.
보안 그룹은 이미 생성한 그룹을 그대로 사용하면 되며 key또한 새로 발급받을 필요 없이 기존의 key를 사용하시면 됩니다.
다만 태그 설정에서 값을 kafka-server가 아닌 kafka-producer로 변경하여 생성합니다.
4.2.2 kafka 설치
kafka-server에서 사용한 터미널 이외에 또 하나의 터미널을 띄우고 producer 인스턴스에 접속합니다.
java와 kafka를 설치하는 방법까지는 동일합니다.
다만 zookeeper와 broker를 실행하는 부분 부터는 하지 않아도 되며 토픽 설정과 kafka-server인스턴스로 연결하는 작업을 수행 할 것 입니다.
$ bin/kafka-console-producer.sh --topic twitter --bootstrap-server 172.31.15.105:9092
위의 IP주소는 여러분들의 kafka-server의 IPv4의 private 주소를 입력하면 됩니다.
4.2.3 logstash 설치
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.0.tar.gz
$ tar xvzf logstash-7.4.0.tar.gz
$ ln -s logstash-7.4.0 logstash
위와 같이 logstash를 설치하였다면 어느 폴더에서나 logstash를 실행 시킬 수 있도록 다음과 같은 작업을 수행해 줍니다.
version체크를 수행해 봄으로서 정상적으로 작동이 되는지 확인까지 해줍니다.
$ vi ~/.bash_profile
export LS_HOME=/home/ec2-user/logstash
PATH=$PATH:$LS_HOME/bin
$ source ~/.bash_profile
$ logstash --version
인스턴스 내에 producer라는 폴더를 하나 생성 해주고 본격적으로 producer역할을 수행하는 코드를 넣어보도록 합시다. 마찬가지로 output에 있는 IP주소는 kafka-server의 IPv4주소입니다.
$ mkdir producer
$ cd producer
$ vi producer.conf
input {
twitter {
consumer_key => "KoxofBvIwdM9zz2JJ9vxg"
consumer_secret => "kKBOnftLZ6htxvddgmZkzsii17ZeexCIgpIHNoWtE"
oauth_token => "81761998-2Vu19ZxxFwEyik7XZ4ubG9mIj91wHdbIXdP08fId4"
oauth_token_secret => "0E6eh4X0eum4NU81LXIKn6MMgH5TAWteL7asT8JxTo"
keywords => ["news","game","bigdata","AI"]
full_tweet => true
}
}
output {
kafka {
bootstrap_servers => "172.31.15.105:9092"
codec => json{}
acks => "1"
topic_id => "twitter"
}
}
다음 명령어로 logstash를 위 코드 기반으로 실행합니다.
$ logstash -f producer.conf
위 명령어를 입력하면 producer쪽에서 twitter데이터를 수집하는 모습이 보이고 그 수집된 데이터가 kafka-server에도 그대로 표시되는 것이 보일 것 입니다.
너무 오래 켜두면 사용량에 따른 요금이 발생 할 수 있으니 데이터가 전달되는 것만 확인하고 작업을 중지해 줍시다.
4.3 consumer 구축
4.3.1 EC2 - 인스턴스 생성
인스턴스를 생성하는 방법은 위와 동일합니다.
보안 그룹은 이미 생성한 그룹을 그대로 사용하면 되며 key또한 새로 발급받을 필요 없이 기존의 key를 사용하시면 됩니다.
다만 태그 설정에서 값을 kafka-server가 아닌 kafka-consumer로 변경하여 생성합니다.
4.3.2 logstash 설치
consumer는 kafka를 설치 할 필요가 없습니다.
그렇기 때문에 java를 설치할 필요도 없으며 logstatsh만 설치해 주도록 합시다.
방식은 위와 같습니다.
어느 폴더에서나 logstash를 실행 할 수 있도록 하는 작업까지 마쳤다면 마찬가지로 consumer폴더를 생성하고 consumer역할을 수행하는 코드를 넣어보도록 합시다.
$ mkdir consumer
$ cd consumer
$ vi consumer.conf
input {
kafka {
bootstrap_servers => "172.31.15.105:9092"
topics => ["twitter"]
consumer_threads => 1
decorate_events => true
}
}
output {
stdout {
codec=> rubydebug
}
}
이번 코드는 kafka-server로 부터 데이터를 가져와 stdout, 단순히 화면에 표시해 주는 역할을 수행합니다.
아래 명령어로 logstash를 실행시켜 producer로 부터 가져온 데이터가 queue를 거쳐 consumer로 전달되는지 확인해 보도록 합시다.
$ logstash -f consumer.conf
마치며
이번 포스팅에서는 logstash와 kafka를 이용해 간단한 데이터 파이프라인을 구축해 보았습니다.
이러한 데이터 파이프라인은 역할과 구조에 따라 수많은 서비스가 존재하며 처음부터 이를 전부 파악하는 것은 무척 어렵습니다.
그렇기 때문에 간단한 파이프 라인 구축을 실습을 통해 수행해 보면서 점차 각 서비스의 역할과 개념을 이해해 나가는 방식으로 학습을 진행하려고 합니다.
다음 포스팅 부터는 점차 심화된 파이프 라인 구축을 실습 해 볼 예정이며 그 때마다 필요한 그때그때 정리할 예정입니다.